- 本文对Redis源码的学习是基于5.0.2版本.
前言
为什么有跳表这种数据结构 :
- 相比常见的平衡树,比如平衡二叉树(AVL),由于AVL树是一颗过于平衡的二叉树,在更改操作中对于维护平衡所需的代价较大;而较为平衡的红黑树的实现细节也是较为复杂 :
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速.
- 范围查询 : AVL树、红黑树、跳表存储的元素都是有序的,所以支持范围查询,但是AVL树、红黑树的范围查询需要以中序遍历的顺序继续寻找其它不超过大值的节点,而跳表上进行范围查找就非常简单.
- 跳表和平衡树的时间复杂度都为O(log n),大体相当,但跳表的原理相当简单.
例子
对于一个有序的数列中,我们是如何做到插入一个值并保证数列的有序性 : 二分查找后进行插入,但是找到位置还要在数组中一个一个挪位置,时间复杂度依旧是O(n),如下图 :
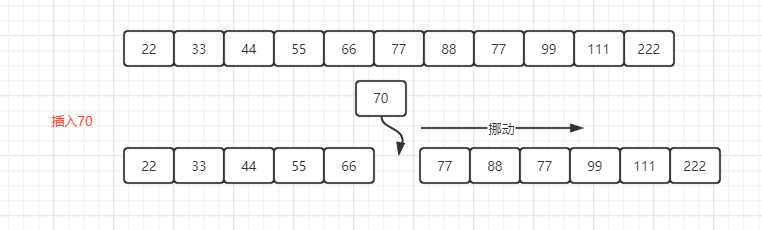
- 普通链表不支持二分查找,但是更新操作并不需要进行数据挪动;
- 数组支持二分查找,但是更新操作需要进行数据挪动;
- 数组的更新操作需要挪动数据是不可接受的,那么从普通链表下手,即现在要解决的是普通链表的查找问题;
普通链表的遍历是通过指针一步一步遍历查找,如果能跳着查找就好了,比如打个标记,可以在查找的时候加速查找,如下图 :
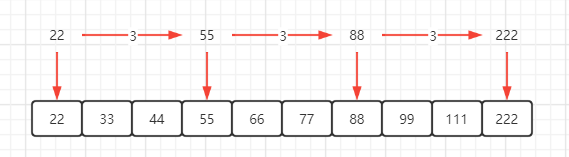
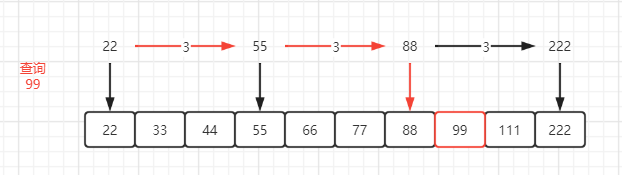
查询99,如下图 : 查找一个数时先从标记的最高层开始查找,如果同层的下一个标记比本身大的话就往下走(降层),因为再往前肯定是不符合要求了,否则是往前查找(前进指针) :
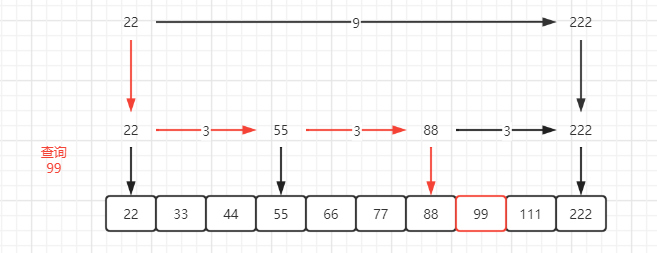
再来一些标记, 如下图 :
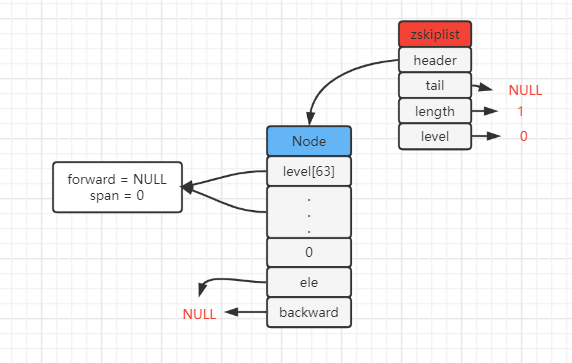
zskiplist --- 结构体(源文件server.h)
zskiplistNode --- 结构体
zskiplist跳表维护着许多zskiplistNode结点,通过每个结点的分值(有序)、对应的层(标记)可加速有序的访问.
# 跳表结点
typedef struct zskiplistNode {
// 结点存储的具体值
sds ele;
// 分值
double score;
// 后退指针,使得跳表第一层组织为双向链表
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned long span;
} level[];
} zskiplistNode;
- zskiplistLevel(层) : 一个level数组,每个结点通过level数组来标记,可加快访问其他结点的速度;
- forward(前进指针) : 同一层的下一指针结点
- span(跨度) : 当前结点到下一指针结点之间存在多少个结点;跨度与遍历操作无关,遍历操作只使用前进指针就可以了;跨度实际上是用来计算排位(rank)的 : 在查找某个结点的过程中,将沿途访问过的所有层的跨度累计起来,得到的结果就是目标结点在跳跃表中的排位.
- score(分值) : 所有结点都按分值从小到大来排序
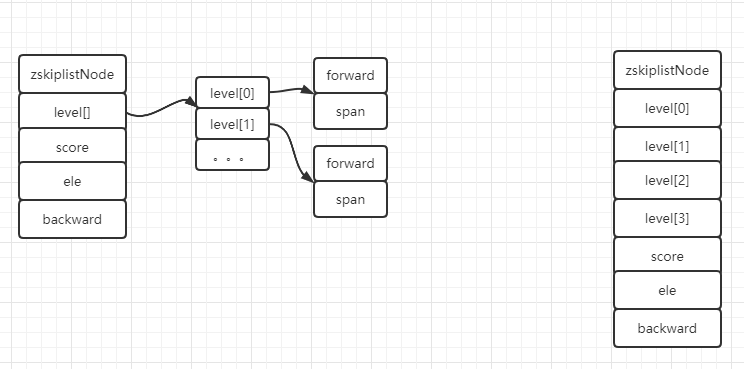
zskiplist --- 结构体
# 跳表
typedef struct zskiplist {
// 头结点、尾结点
struct zskiplistNode *header, *tail;
// 记录元素存储个数
unsigned long length;
// 记录当前最高层是多少
int level;
} zskiplist;
如下图 :
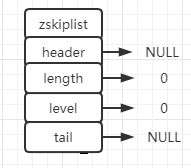
zskiplist --- 图形化
- 图一 :
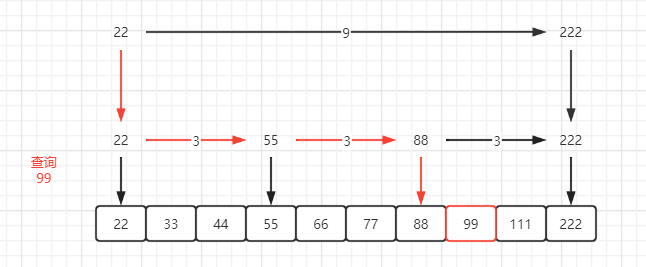
- 图二 :
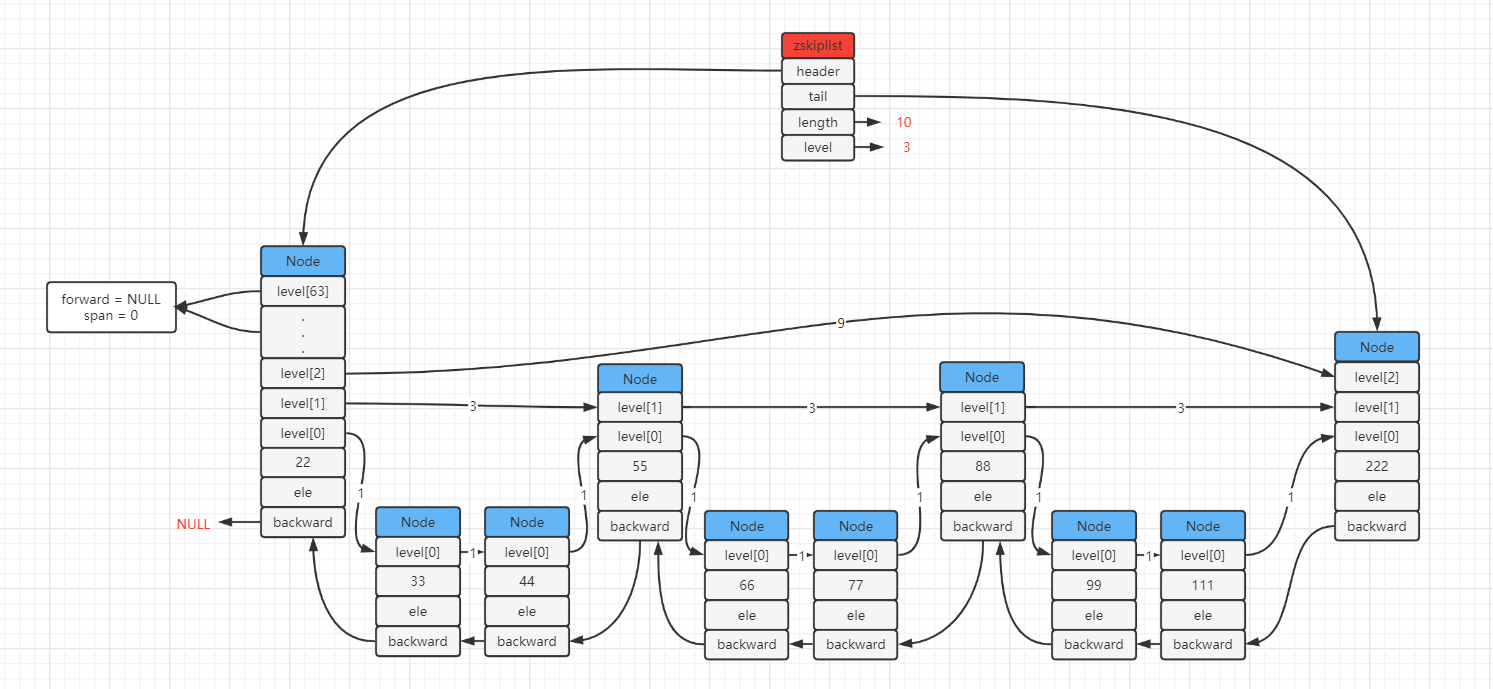
zskiplist --- 常用API(源文件t_zset.c)
zslCreate() --- 初始化
# zslCreate()
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
1. // 申请内存
zsl = zmalloc(sizeof(*zsl));
2. // 默认初始化1层
zsl->level = 1;
zsl->length = 0;
3. // 创建头结点
// 头结点为ZSKIPLIST_MAXLEVEL(64)层
// Redis限制最多64层
// 该函数具体下面分析
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
4. // 默认对头结点的每一层进行初始化
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
5. // 尾结点
zsl->tail = NULL;
return zsl;
}
zslCreateNode --- 创建结点
# zslCreateNode()
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
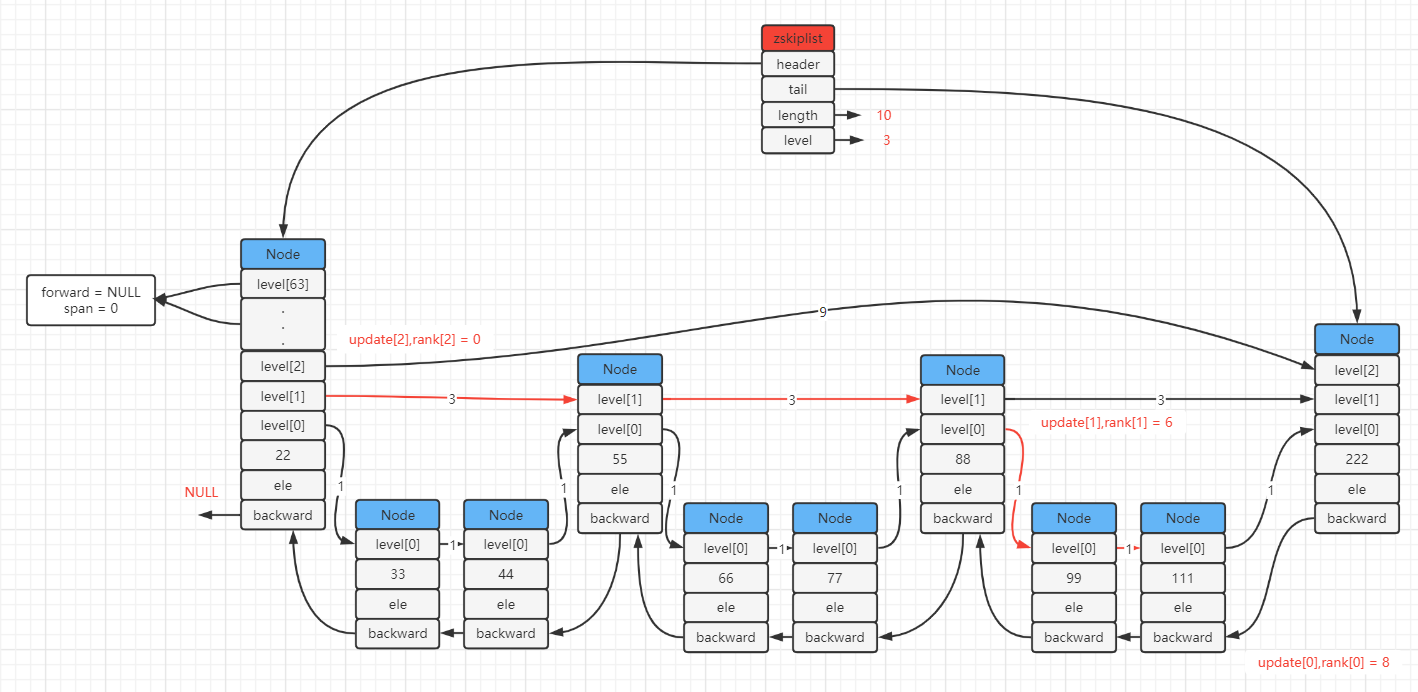
zslInsert() --- 添加
我把该函数分为两大部分 :
- 查询插入结点的插入位置 : 查询过程中也会记录标记,标记的地方也需要插入新结点;
- 开始处理插入结点.
# zslInsert()
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
// update : 记录 在查询 插入结点位置 的过程的降层结点,包括最后找到的的level[0]层的结点
// 即从最高层开始向下记录每层标记的插入位置结点,也可以说是记录降层结点
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
// 记录每一层中 从最高层到当前层的降层结点的排位(rank)
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
# 查询 插入结点 的插入位置 start
## 查询过程会通过update来记录每一层的降层结点,rank来记录每一层的排位
// 取到header
x = zsl->header;
1. // 从最高层开始往下遍历
for (i = zsl->level-1; i >= 0; i--) {
1.1 // 记录当前i层的排位,如果是最高层,则是0
// 否则取上一层的排位
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
1.2 // 多个条件判断是否同层前进还是降层
// 如果i层结点的forward没有结点,那么当前必须降层,对应的1.3步骤,否则继续判断
// 如果i层结点的forward结点的分值 小于 插入结点的分值 则同层前进(1.2.2步骤),否则继续判断
// 如果i层结点的forward结点的分值 等于 插入结点的分值 并且
// i层结点的forward结点的ele字符串 小于 插入结点的ele字符串
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
1.2.1 // 叠加i层的排位
rank[i] += x->level[i].span;
1.2.2 // 同层移动
x = x->level[i].forward;
}
1.3 // 降层,保存每层的插入位置节点,即保存降层结点
update[i] = x;
}
# 查询 插入结点 的插入位置 end
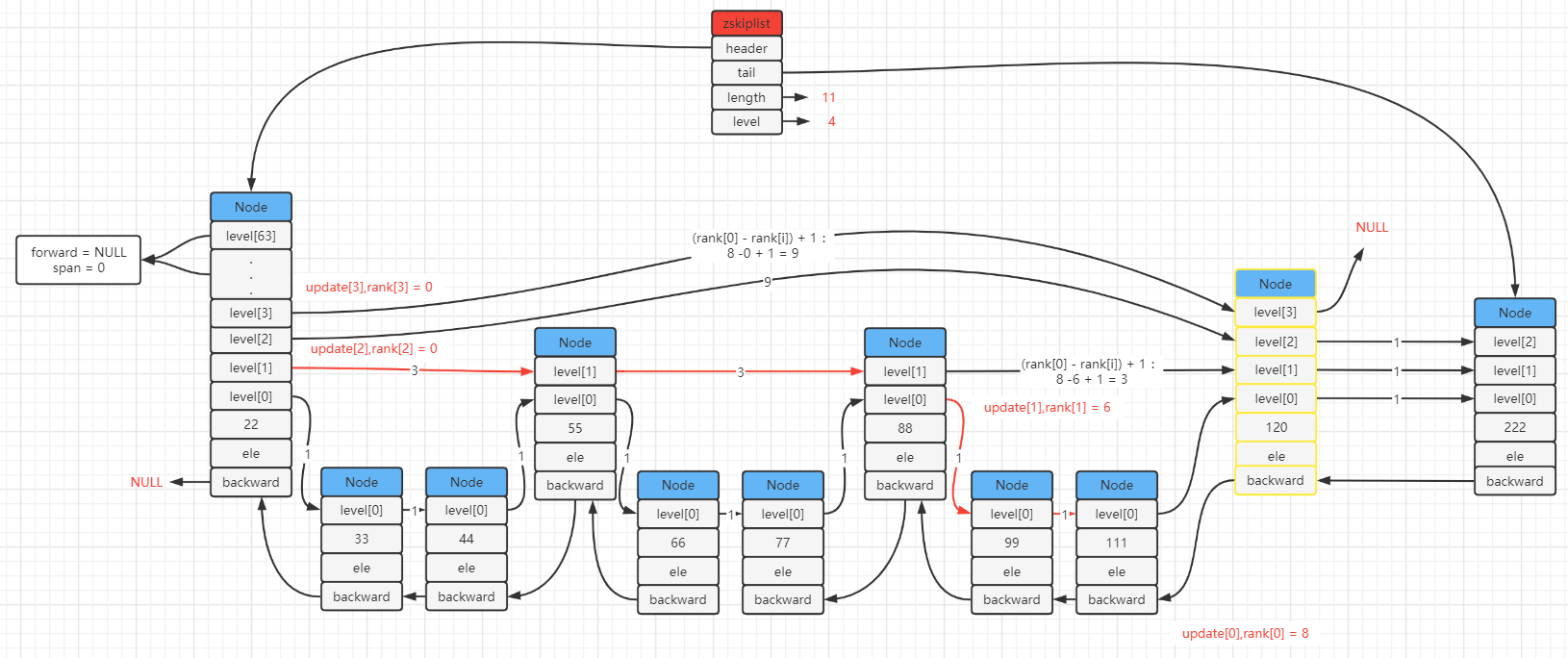
## 开始插入结点 start
2. // 随机计算层数
level = zslRandomLevel();
3. // 如果随机计算的层数大于当前的层数,需要做一些操作
if (level > zsl->level) {
3.1 // 超出的新层 [zsl->level,level) 需要初始化
for (i = zsl->level; i < level; i++) {
3.1.1 // 排位为0
rank[i] = 0;
3.1.2 // 指向header
update[i] = zsl->header;
3.1.3 // 跨度取当前存储元素的个数
update[i]->level[i].span = zsl->length;
}
3.2 // 更换层数
zsl->level = level;
}
4. // 创建插入结点
x = zslCreateNode(level,score,ele);
5. // 开始从最高层往下遍历,根据update、rank的记录来指向插入结点
for (i = 0; i < level; i++) {
5.1 // 把插入结点连接上每层记录的降层结点
// update记录了每层的降层结点
// i层的前进指向了update的i层降层结点的前进结点
x->level[i].forward = update[i]->level[i].forward;
// update的i层前进指针指向了当前插入的结点
update[i]->level[i].forward = x;
5.2 // 重新处理跨度(span),这里看不懂的话可以先看下面的插入过程流程图
// rank 记录了 从最高层到最低层的查询路线中,每一层的最高层到当前层走过(红线)的rank
// rank[0] - rank[i] : 第一层的降层结点排位 减去 i层的降层结点rank 得到的是 i层的降层结点 到 i层的插入x结点 之间的 跨度
// update[i]->level[i].span 减去 i层的降层结点 到 i层的插入x结点的跨度 得到的 就是 i层插入x结点到forward结点的跨度
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// i层的降层结点 到 i层的插入x结点的跨度 再加上1
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
6. // 超出的新层 [zsl->level,level) 的跨度也+1
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
7. // 处理backward
// 如果update[0]指向header,表示新结点x的插入位置是在链头
// 否则backward指向update[0]
x->backward = (update[0] == zsl->header) ? NULL : update[0];
8. // 处理forward结点的backward
if (x->level[0].forward)
8.1 // 存在forward结点,forward结点的backward与x结点接上
x->level[0].forward->backward = x;
else
8.2 // 不存在forward结点,是尾结点,tail指向x结点
zsl->tail = x;
9. // 存储元素个数+1
zsl->length++;
## 开始插入结点 end
return x;
}
下列两张图演示插入新结点(分值为120)的过程 :
- 图一 : 会保存每个降层结点以及对应的rank.
- 图二 : 我这里假设随机生成的是4层,如下图成功插入最新的结点.
zslRandomLevel() --- 随机生成层数
- 该函数生成的层数总是保证在 [1,64] .
- 【PS : Redis作者的随机算法参考链接】
# zslRandomLevel()
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
# ZSKIPLIST_P : 1/4
zslDelete() --- 删除
根据分值、ele字符串来删除结点 :
# zslDelete()
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
1. // 从最高层开始查询
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
1.1 // 前进
x = x->level[i].forward;
}
1.2 // 保留降层结点
update[i] = x;
}
2. // 根据分值、ele字符串来删除结点
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
2.1 // 根据update记录的降层结点来删除结点,该函数下面具体分析
zslDeleteNode(zsl, x, update);
2.2 // 如果node不为null,则回收内存
if (!node)
zslFreeNode(x);
2.3 如果node为null,则不回收内存,node指向删除的结点
else
*node = x;
return 1;
}
3. 没有查询到需要删除的结点
return 0;
}
zslDeleteNode --- 删除结点
# zslDeleteNode()
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
1. // 根据保留的降层结点来删除
for (i = 0; i < zsl->level; i++) {
1.1 // 如果降层结点的forward指向的是删除的结点
if (update[i]->level[i].forward == x) {
1.1.1 // span-1
update[i]->level[i].span += x->level[i].span - 1;
1.1.2 // 与删除结点x的forward连接
update[i]->level[i].forward = x->level[i].forward;
} else {
1.1.3 // 降层结点的forward指向的不是删除的结点,span-1
update[i]->level[i].span -= 1;
}
}
2. // 处理backward
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
3. 重新计算level
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
4. 元素个数-1
zsl->length--;
}
范围查询
- zslFirstInRange() : 从头结点查找指定范围中包含的第一个最小节点
# zslFirstInRange()
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
// 检查范围查询的参数
if (!zslIsInRange(zsl,range)) return NULL;
1. // 从最高层开始查询
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
1.1 // 查找第一个最小值的结点 : 如果小于min,则降层或者前进来继续查找
while (x->level[i].forward &&
!zslValueGteMin(x->level[i].forward->score,range))
x = x->level[i].forward;
}
// 最小值
x = x->level[0].forward;
serverAssert(x != NULL);
// 判断当前查询的第一个最小值如果大于max,也是返回NULL
if (!zslValueLteMax(x->score,range)) return NULL;
return x;
}
int zslValueGteMin(double value, zrangespec *spec) {
return spec->minex ? (value > spec->min) : (value >= spec->min);
}
int zslValueLteMax(double value, zrangespec *spec) {
return spec->maxex ? (value < spec->max) : (value <= spec->max);
}
- zslLastInRange() : 从头结点查找指定范围中包含的最后一个最大节点
# zslLastInRange()
zskiplistNode *zslLastInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
if (!zslIsInRange(zsl,range)) return NULL;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
// 查找最后一个最大值的结点 : 如果小于max,则降层或者前进来继续查找
while (x->level[i].forward &&
zslValueLteMax(x->level[i].forward->score,range))
x = x->level[i].forward;
}
serverAssert(x != NULL);
// 判断当前查询的最后一个最大值如果小于min,也是返回NULL
if (!zslValueGteMin(x->score,range)) return NULL;
return x;
}
结束语
- 本文对跳表的结构进行了分析,从而有了初步的认识;
- Redis作者为什么不使用红黑树、B树之类的平衡树 :
- 虽然跳表是以空间换时间的数据结构,红黑树不需要额外的空间,但是跳表并不是特别耗内存,只需要调整下节点到更高level的概率,就可以做到比B树更少的内存消耗;
- 有序集合可能面对大量的范围查询操作,跳表作为单链表遍历的实现性能不亚于其他的平衡树;
- 实现和调试起来比较简单.
- Redis的作者antirez也曾经亲自回应过这个问题
- Java 的HashMap为什么使用的是红黑树,而不是跳表 :
- HashMap 的设计并不是有序的,跳表需要元素之间存在排序关系,否则就无法跳跃查找;
- TreeMap相对应的并发容器 ConcurrentSkipListMap 就是使用的跳表;
- 跳表的平衡性关键是由每个节点插入的时候,它的索引层数是由随机函数计算出来的,而且随机的计算不依赖于其它节点,每次插入过程都是完全独立的.这样,就和普通链表的插入一样,查找到插入点位置后,只需要一次操作就可以完成结点插入,时间复杂度为 O(logn).
- 原创不易
- 希望看完这篇文章的你有所收获!
相关参考资料
- Redis设计与实现【书籍】