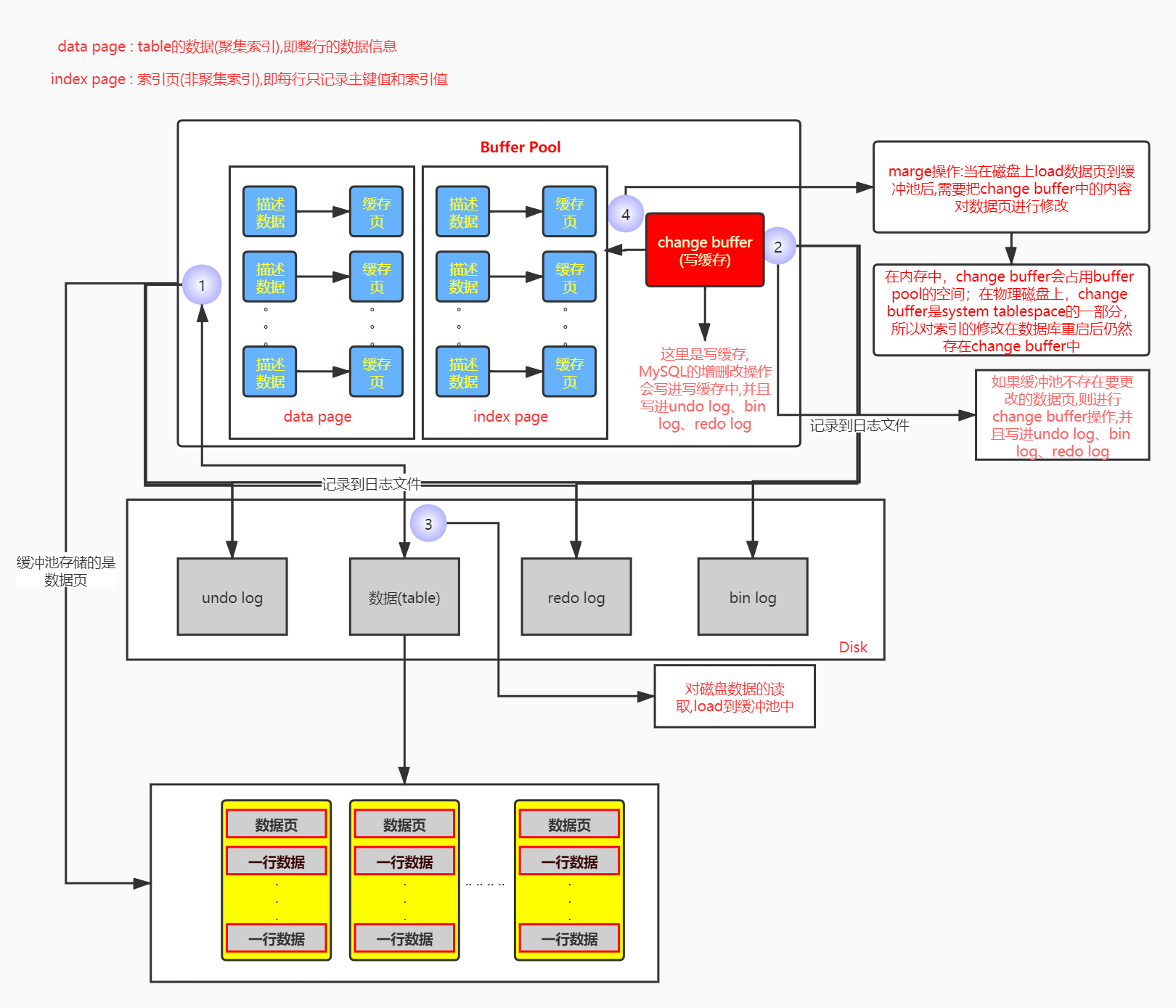
可能看到上面这张流程图,会觉得有点乱,上面流程图的核心关注点是Buffer Pool就行,下面的日志文件本篇文章没有详细说明,会独立写一篇文章.
InnoDB的Buffer Pool
我们知道,MySQL的数据最终是保存在磁盘上,保证了数据的持久性.我们又知道,在对磁盘上的数据进行DML的时候,速度是相当的慢(磁盘的随机读写非常消耗性能),比如一个大的磁盘文件进行DML操作,可能要几百毫秒,也会造成性能低、响应慢等问题;而如果在内存上对数据进行DML的话,速度就可以快了很多;所以,InnoDB的Buffer Pool出来了,在我们对数据库做DML操作的时候,我们不对磁盘进行DML操作,而是对缓冲池(Buffer Pool)里的数据进行DML操作.
既然知道数据库的DML操作是对缓冲池里执行了一堆DML操作,那么缓冲池的数据是更新了,但是这个时候如果数据库突然宕机了,那么内存里更新好的数据不是都没了吗?所以MySQL引入了日志文件机制(日志文件:redo log),你在对缓冲池里的数据进行增删改的时候,他会把增删改的记录写入日志文件中.(redolog,本篇文章暂不详细说明,会独立一个文章专门说明日志文件)
Buffer Pool 是数据库的一个内存组件(核心组件,很重要),默认128MB,它是有一定大小的,不可能无限大,且存储了大量的数据页(MySQL的存储单位是数据页,磁盘上、缓冲池存储的都是数据页,因为是把磁盘上的数据页直接加载到内存中).
描述信息 : 大体可以认为是用来描述这个缓存页,比如包含如下的一些东西:这个数据页所属的表空间、数据页的编号等;每个缓存页都会对应一个描述信息,这个描述信息本身也是一块数据,在Buffer Pool中,每个缓存页的描述数据放在最前面,然后各个缓存页放在后面.
数据页 : MySQL的每一张表都有不同的字段,每张表的每条数据是以 行数据 存放着,而上面又说MySQL是以数据页为存储单位,其实就是数据页里面存放着很多行数据,也就是说,我们的磁盘上、缓冲池里会存放许多个数据页,而每个数据页都存放着许多行数据.
现在我们知道了缓冲池是用来减少对磁盘的DML操作(减少磁盘的随机读写操作),提高数据库的高性能和高并发能力,并且缓冲池跟磁盘上存储的都是数据页(对应的缓冲池中也可以叫缓存页).
了解完Buffer Pool 我们现在来看看MySQL如何设置Buffer poll的其中的参数:
// 缓冲池的大小 默认128MB
innodb_buffer_pool_size
// 查看缓冲池大小
show VARIABLES like "%buffer_pool_size%";
Buffer Pool的Change buffer
通过上一小节我们可以知道,对MySQL的增删改操作的时候,Buffer Pool会帮我们做缓存操作,减少磁盘的读写操作,提高数据库性能和并发能力,而这个能力是Buffer Pool的写缓存(change buffer)提供的,也就是说Buffer Pool 里面还包含了一个写缓存(Change buffer).
写缓存只对非唯一普通索引页有效,即在对非唯一普通索引页更新操作的时候,如果缓冲池中存在数据(数据页),则直接修改缓冲池中的数据页,反之从磁盘把该数据页写入到写缓存中;当查询该数据页的时候,如果缓冲池中存在数据(数据页),则直接返回给执行器,反之,需要进行一次磁盘读操作,把在磁盘读取到数据页载入到缓冲池中;查询数据的时候,需要查看该数据页是否在写缓存有存在记录,如果有,则需要跟写缓存进行marge操作后返回给执行器.
marge操作 : 当相关的索引页被载入到buffer pool中后,会确认该索引页是否纪录存放于Change buffer中,如果有,则将Change buffer中该页的纪录合并到该索引页中.
什么时候才会进行marge操作?
- 1、查询的时候数据不在缓冲池中,这个时候需要进行一次磁盘读操作,当读取到数据页的时候将数据页载入到缓冲池中,会确认该索引页是否纪录存放于change buffer中,如果有,这个时候就需要进行marge操作;
- 2、Master thread 每秒或每10s会进行操作
- 3、Change Buffer Bitmap页追踪到该辅助索引页已无可用空间时
- 4、当mysql关闭时会触发进行操作
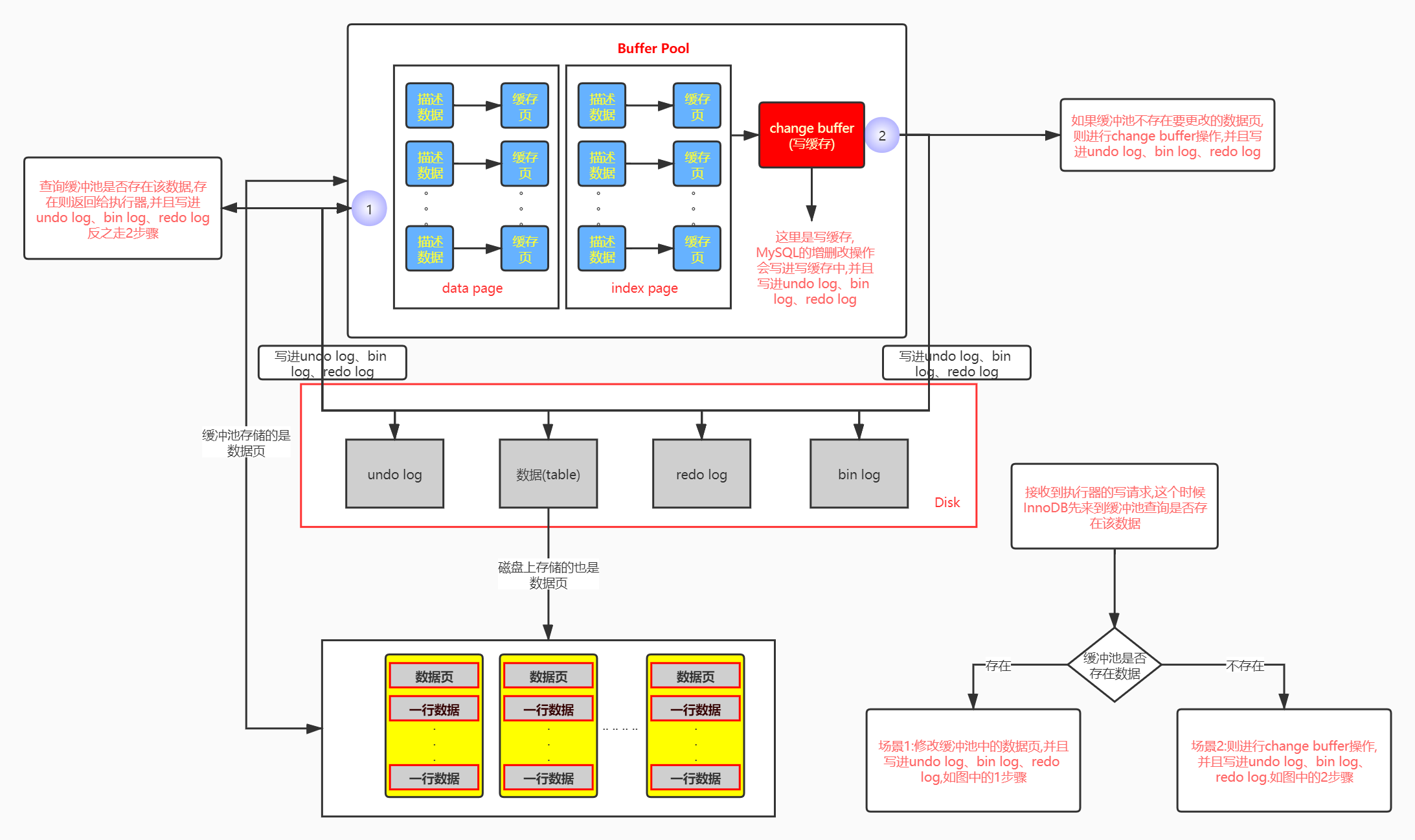
不同DML操作的场景
读请求场景
- 读请求场景:首先,InooDB存储引擎接收到执行器的查询请求,这个时候会先来到缓冲池查询是否存在该数据 :
1.读请求场景1 : 缓冲池存在数据页,返回给执行器.如图中的1步骤
2.读请求场景2 : 缓冲池不存在数据页,需要进行一次磁盘读操作,就是要到磁盘中读取数据,如果磁盘存在数据(数据页),则把数据页载入(load)缓冲池中(3步骤),并且确认该索引页是否纪录存放于change buffer中,如果有,然后在缓冲池中对数据页进行marge操作(2步骤),最后返回给执行器.如图中的1、3、2步骤
两种读场景可以看看下图 : 读请求场景中没用到change buffer,看名称就知道change buffer只提供给增删改操作作缓存.

写请求场景
- 写请求场景:首先,InooDB存储引擎接收到执行器的写请求,这个时候InnoDB先来到缓冲池查询是否存在该数据 :
1.写请求场景1 : 缓冲池存在数据页,修改缓冲池中的数据页,并且写进undo log、bin log、redo log,如图中的1步骤
2.写请求场景2 : 缓冲池不存在数据页,则进行change buffer操作,并且写进undo log、bin log、redo log.如图中的2步骤
两种写场景可以看看下图 : 你会发现,每次的写操作不用去进行磁盘上数据的操作了.
小结及疑问
1.Change buffer的应用场景是什么 : 事务进行数据写操作后不会立刻查看的场景(写多读少),因为如果立刻查看会频繁的触发merge操作
2.为什么Change buffer只对非唯一普通索引有效(聚集索引和唯一索引无效) : 聚集索引和唯一索引都是唯一性的,在写操作的过程中,数据库要判断数据是不是唯一性,需要通过磁盘数据的读取来判断,所以写缓存对他们无效.
3.当Buffer Pool内存空间满了,怎么办?
4.日志文件是什么,起到了什么作用?
结束语
本文的主角是Buffer Pool及change buffer,本文中所有图中的下面有涉及到的日志文件内容暂不详细说明,关注点是在缓冲池和写缓存,后面将继续学习bin log、undo log、redo log、事务机制、事务隔离、锁机制等.
- 原创不易
- 希望看完这篇文章的你有所收获!
相关参考资料
- MySQL技术内幕InnoDB存储引擎【书籍】