Java集合之一 —— LinkedHashMap
- 本文对LinkedHashMap的讲解是基于JDK1.8版本.
- 本文对LinkedHashMap的学习需要对HashMap、链表、继承、多态基础.
- LinkedHashMap核心作用就是保证了元素的插入顺序、访问顺序
- 直奔主题:LinkedHashMap的底层数据结构是由HashMap + 链表 实现.
插入顺序和访问顺序
插入顺序
理解这个概念之前我们需要知道LinkedHashMap在HashMap的功能代码基础上,多维护了链头(head)和链尾(tail)两个节点,并且每个桶装进去的Node节点也多维护了两个节点(before、after)来连接上下节点,这样形成了一条双向链表,保证了插入顺序.
插入顺序:很简单就可以理解,就是元素插入的顺序,看下面代码执行就可以清楚了.
public class MapTest {
private static final String DIRECTION = " ----> ";
private static final String LINK_DIRECTION = " <----> ";
private static final String HEAD_INFO = " 链表头节点(head) ";
private static final String TAIL_INFO = " 链表尾节点(tail) ";
private static final String SEPARATOR = "-------------------------------";
public static void main(String[] args) {
int size = 15;
Map<String, Integer> hashMap = new HashMap<>();
StringBuilder hashInsertResult = new StringBuilder();
Map<String, Integer> linkedHashMap = new LinkedHashMap<>();
StringBuilder linkInsertResult = new StringBuilder(HEAD_INFO);
// 分别向 HashMap 和 LinkedHashMap 顺序插入 10---->11---->12---->13---->14---->15
for (int i = 10; i <= size; i++) {
hashInsertResult.append(putValue(hashMap, i));
linkInsertResult.append(putValue(linkedHashMap, i));
if (i != size) {
hashInsertResult.append(DIRECTION);
linkInsertResult.append(LINK_DIRECTION);
} else {
linkInsertResult.append(TAIL_INFO);
}
}
// 拼接遍历顺序
int index = 0;
StringBuilder hashQueryResult = new StringBuilder();
StringBuilder linkQueryResult = new StringBuilder(HEAD_INFO);
bufferValue(hashMap, index, hashQueryResult);
bufferValue(linkedHashMap, index, linkQueryResult);
System.out.println(SEPARATOR);
System.out.println("HashMap的插入顺序 : " + hashInsertResult);
System.out.println("HashMap的遍历顺序 : " + hashQueryResult);
System.out.println(SEPARATOR + "\n");
System.out.println(SEPARATOR);
linkQueryResult.append(TAIL_INFO);
System.out.println("LinkedHashMap的插入顺序 : " + linkInsertResult);
System.out.println("LinkedHashMap的遍历顺序 : " + linkQueryResult);
System.out.println(SEPARATOR);
}
private static StringBuilder bufferValue(Map<String, Integer> map, int index, StringBuilder result) {
for (Map.Entry<String, Integer> entry : map.entrySet()) {
result.append(entry.getValue());
if (++index != map.size()) {
if (map instanceof LinkedHashMap) {
result.append(LINK_DIRECTION);
} else {
result.append(DIRECTION);
}
}
}
return result;
}
private static String putValue(Map<String, Integer> map, int value) {
String key = String.valueOf(value);
map.put(key, value);
return key;
}
}
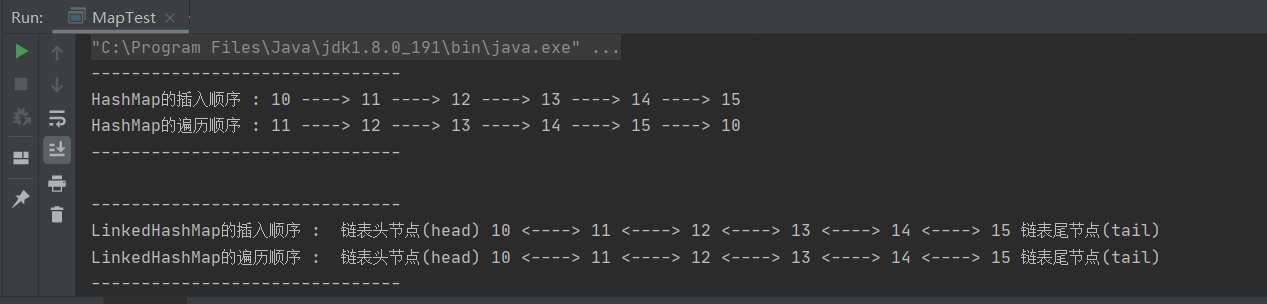
上图我们可以看出,HashMap和LinkedHashMap顺序插入的10到15,但是遍历的结果却不一样了,HashMap遍历的结果顺序改变了,而LinkedHashMap遍历的顺序还是跟插入顺序一样,这就是LinkedHashMap的作用之一,解决了HashMap遍历时插入元素的顺序问题,保证了插入元素的顺序不变.
访问顺序
LinkedHashMap由变量 accessOrder 来维护是否开启访问顺序,默认是不开启访问顺序的.
访问顺序:理解起来也很简单,访问到的元素将会被移到链尾(tail变量,也就是说链尾的元素总是最新的),那怎么样的操作才属于访问元素呢:put的时候容器中出现相同对象key的时候会把该元素移到链尾(当然,没有相同的对象会把元素加到链尾中)、get方法查找到存在元素的时候也会把该元素移到链尾中.
public class MapTest2 {
private static final String LINK_DIRECTION = " <----> ";
private static final String HEAD_INFO = " 链表头节点(head) ";
private static final String TAIL_INFO = " 链表尾节点(tail) ";
public static void main(String[] args) {
int size = 15;
// 开启访问顺序
Map<String, Integer> linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
StringBuilder linkInsertResult = new StringBuilder(HEAD_INFO);
// 分别向 HashMap 和 LinkedHashMap 顺序插入 1---->2---->3---->4---->5......
for (int i = 10; i <= size; i++) {
linkInsertResult.append(putValue(linkedHashMap, i));
if (i != size) {
linkInsertResult.append(LINK_DIRECTION);
} else {
linkInsertResult.append(TAIL_INFO);
}
}
// 调用put 、 get
int index = 0;
linkedHashMap.put("10", 10);
linkedHashMap.get("12");
StringBuilder linkQueryResult = new StringBuilder(HEAD_INFO);
bufferValue(linkedHashMap, index, linkQueryResult);
System.out.println("LinkedHashMap的插入顺序 : " + linkInsertResult);
System.out.println("LinkedHashMap的遍历顺序 : " + linkQueryResult);
}
private static void bufferValue(Map<String, Integer> map, int index, StringBuilder linkQueryResult) {
for (Map.Entry<String, Integer> entry : map.entrySet()) {
linkQueryResult.append(entry.getValue());
if (++index != map.size()) {
linkQueryResult.append(LINK_DIRECTION);
} else {
linkQueryResult.append(TAIL_INFO);
}
}
}
private static String putValue(Map<String, Integer> map, int value) {
String key = String.valueOf(value);
map.put(key, value);
return key;
}
}
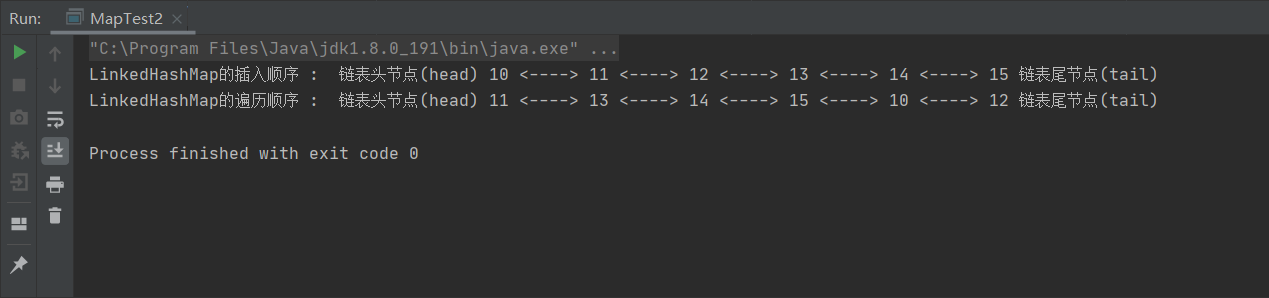
上图我们可以看出,LinkedHashMap开启了访问顺序,并且调用get、put后,访问到的元素会重新排序到链尾中.
LinkedHashMap存储结果图

LinkedHashMap : 简单的自我介绍
LinkedHashMap的底层是由HashMap、双向链表实现,使用继承的方式复用了HashMap的功能;为什么要继承呢?原因很简单:HashMap通过哈希算法 和 位运算 计算出索引值,该索引值就是插入到数组的位置,并且通过链表法来避免哈希冲突,因为索引值是不确定的,那么遍历元素的时候就不能保证元素的插入顺序了,LinkedHashMap的作用一就是体现在这里,就是来保证元素的插入顺序.
LinkedHashMap在HashMap的基础上,多维护了三个全局变量: 分别是 双向链表的头节点(head) 、 双向链表的尾节点(tail) 、 是否开启访问顺序(accessOrder);并且你还记得 HashMap的静态内部类 Node节点吗,回顾一下,HashMap容器存储的元素对象实际上是Node节点,同样的,LinkedHashMap也继承了这个对象的属性,并且在这个对象的基础上增多了两个属性,分别是 before(连接上一个节点) 、 after(连接下一个节点),通过这两个属性来维护双向链表.
全局变量
// 继承了HashMap
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
// 继承了 HashMap的Node节点 同样新增了before, after来维护双向链表
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
// 双向链表头节点 : head
transient LinkedHashMap.Entry<K,V> head;
// 双向链表尾节点 : tail
transient LinkedHashMap.Entry<K,V> tail;
// 是否开启访问顺序,默认无参构造器是关闭的,需要自己开启
final boolean accessOrder;
.......
}
构造器(5个)
1. 传入 桶(数组)的数量 和 负载因子
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
2. 传入 桶(数组)的数量 HashMap默认负载因子为 0.75f
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
3. 无参构造器 HashMap默认 桶(数组)的数量为 16 负载因子为 0.75f
public LinkedHashMap() {
super();
accessOrder = false;
}
4. 把多个Map容器的元素整合到一个容器中
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
5.传入 桶(数组)的数量 、 负载因子 、是否开启访问顺序,该构造器是唯一一个开启访问顺序的
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
添加元素
LinkedHashMap的put方法实际上是调用了HashMap的put方法;回顾一下HashMap在put方法,实际是对Node节点对象来存储维护的,HashMap添加的元素不存在容器中时,需要创建(new)Node节点添加到容器中;同样的,在LinkedHashMap中,当put的元素不存在容器中时,LinkedHashMap也需要创建Node节点,只是创建(new)Node的时候是调用自己的方法创建节点,这就是多态的魅力之一.
我们来看看该方法的代码做了什么操作:
// 创建新的节点 重点是 linkNodeLast(p) 方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
// 创建Node节点
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 维护双向链表
linkNodeLast(p);
return p;
}
// 比HashMap 多了双向链表的维护的操作
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
// 获取尾节点元素
LinkedHashMap.Entry<K,V> last = tail;
// 把添加进来的元素p连接到尾节点中
tail = p;
// 判断添加进来前的尾节点元素为空的话 说明该双向链表是空的
if (last == null)
head = p;
else {
// 判断添加进来前的尾节点元素不为空的话 说明该双向链表是存在元素的,需要连接起来
// 当前添加的元素p 的上一个节点连接上添加进来前的尾节点元素 : before
p.before = last;
// 添加进来前的尾节点元素的下一个节点连接上当前添加的元素p : after
last.after = p;
}
}
HashMap的put方法执行到最后还会执行 afterNodeInsertion方法 ,这个方法的意思就是是否淘汰最旧的元素,什么是最旧的元素:我们知道,如果我们开启访问顺序的话,那么经常访问到的数据将会被移动到链尾,这里可以称这些数据为"热点数据";反之,不经常访问的数据就在链头中,所以链头存放的是最旧的元素,称这些数据为"冷数据". 具体也可以了解LRU算法,MySQL的LRU算法等.
1.HashMap的 afterNodeInsertion 方法 : 是空的,多态,实际上LinkedHashMap调用的是自己的方法
void afterNodeInsertion(boolean evict) { }
2.LinkedHashMap 的afterNodeInsertion 方法
void afterNodeInsertion(boolean evict) { // possibly remove eldest
// 核心是 removeEldestEntry(first)方法
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
3. removeEldestEntry 方法 : 在LinkedHashMap中,该方法总是返回false,所以LinkedHashMap添加数据的时候不会淘汰旧的元素(链头的元素)
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
get(Object key) 方法
1. 根据key值获取value值
public V get(Object key) {
Node<K,V> e;
// getNode方法 调用的是HashMap的getNode方法
if ((e = getNode(hash(key), key)) == null)
return null;
// 重点是 afterNodeAccess 方法
// 是否开启访问顺序
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
// 把访问到的元素移到链尾中
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 开启了访问顺序 且 当前链尾真好不是需要移动的数据
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
LinkedHashMap通过afterNodeAccess方法来把访问到的元素移到链尾中.
我们再来看看HashMap的put方法中的一段代码:
// e!=null 说明容器中存在put进去的Node节点 需要移动到链尾中
if (e != null)
{
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 维护访问顺序
afterNodeAccess(e);
return oldValue;
}
结束语
其实只要对HashMap的底层数据结构有比较深的理解,对于LinkedHashMap的理解也会易如反掌;另外不知你是否知道LRU算法,我们可以运用LinkedHashMap实现LRU算法;MySQL也使用了LRU算法,只是MySQL对LRU算法做了优化.
HashSet是用组合的方式使用了HashMap;我们知道,HashMap的key键值对象必须重写equals方法和hashcode方法来保证同一个对象(或者不可变对象,例如String),而HashSet就利用了这个特性,来达到add元素的时候HashSet容器中是没有重复元素的.
LinkedHashSet:LinkedHashSet其实更简单了,底层使用的是HashSet 和 LinkedHashMap,保证了元素不可重复和插入顺序.
HashSet、LinkedHashMap、LinkedHashSet 都是围绕HashMap来实现,所以掌握HashMap的底层原理是至关重要的.
希望看完这篇文章的你有所收获!