前言
- 本文重点对kafka实现Producer的client端的架构原理进行源码分析,以便理解Producer的发送消息API、本地缓存路由信息、基于partition负载均衡、异步批处理思想、内存池等特性;
- 本文基于 kafka-1.1.1、JDK1.8、scala2.11.12、zookeeper-3.4.1的开发环境;
- kafka源码github地址 ,下载完之后,代码模块对应的是clients模块;
- 搭建环境推荐文章:kafka源码阅读环境搭建;
- 本文你可以了解到kafka的Producer的整体架构分析,在理解完整个架构设计后,我们后期对发送消息的API可以更好的深入学习、对你的业务场景可以有兜底方案,以及对一些关键性的配置参数也可以做到"知根知底"。
KafkaProducer
生产者的作用就是负责生产消息,我们开发的服务可以充当生产者或者消费者的角色,充当哪个角色取决于业务场景。Kafka提供KafkaProducer来供生产者把消息发送到Broker,使用起来也很方便,如下的简单例子:
//配置对象
Properties props = new Properties();
//设置broker的地址,可以多个,设置一个也可以,kafka最终会帮我们找到整个集群的元数据信息
props.put("bootstrap.servers", String.join(",", KafkaProperties.KAFKA_SERVER_URLS));
props.put("client.id", "DemoProducer");
//序列化key:一般跟业务属性有关,用来partition负载均衡,当然也可以不用写
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
//序列化value:消息内容
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建实例
KafkaProducer<Integer, String> producer = new KafkaProducer<>(props);
//提供了2个发送消息的API
Integer key = 1;
String value = "abin";
//1、自定义回调函数,消息无论发送成功或者失败(例如收到broker的响应),会执行这个回调对象
DemoCallBack callBack = new DemoCallBack(startTime, key, value);
producer.send(new ProducerRecord<>(topic,key,value), callBack);
//2、无需回调函数
producer.send(new ProducerRecord<>(topic,key,value)).get();
PS:这两个API都是异步发送消息,唯一的区别就是一个有回调函数,一个没有
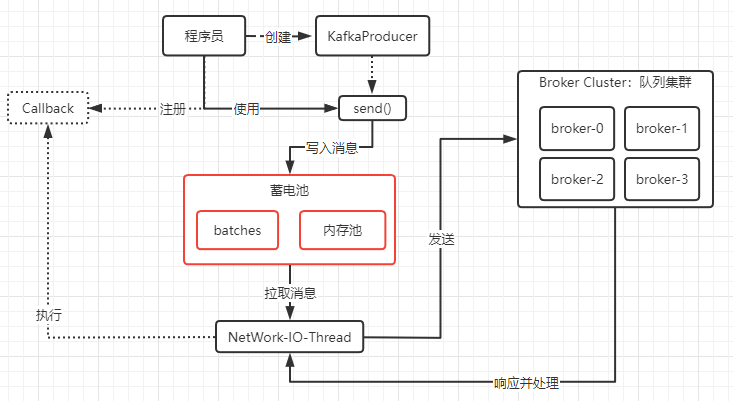
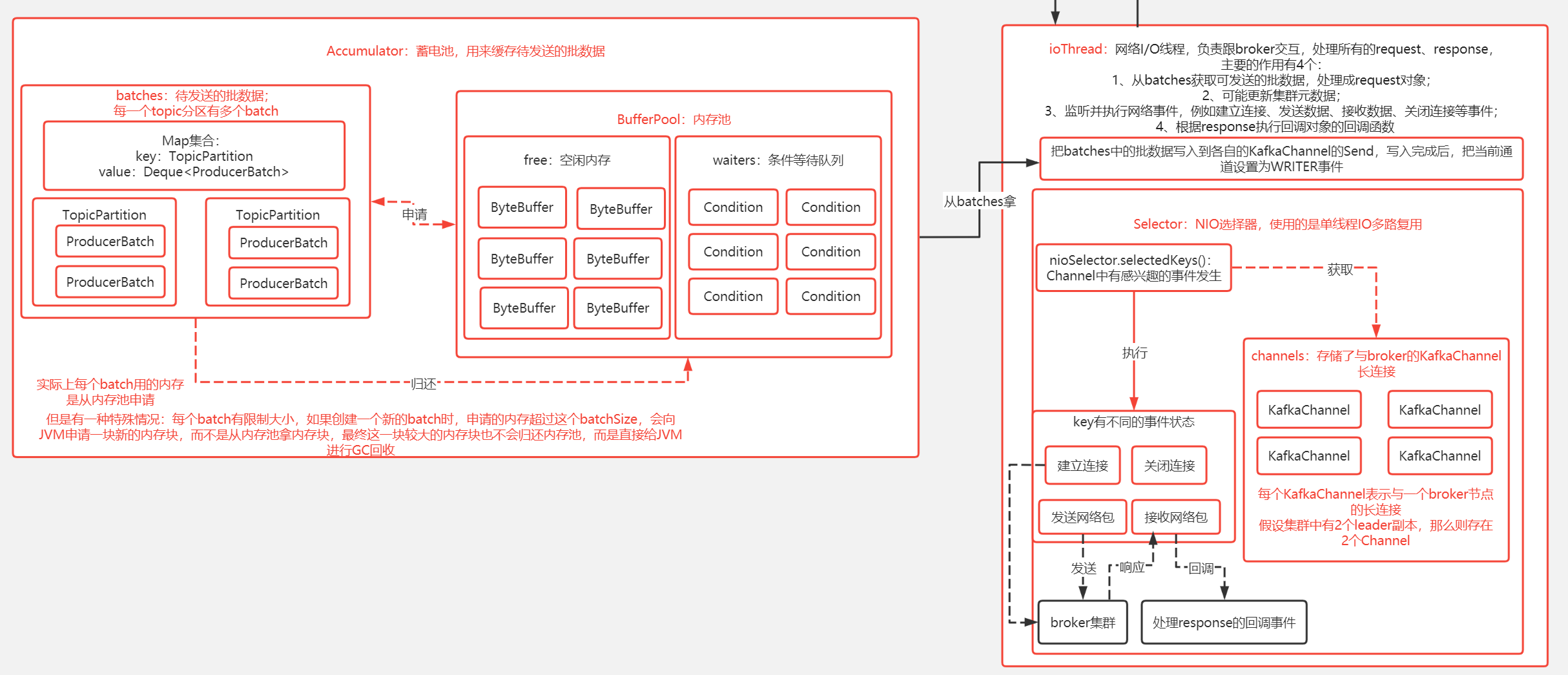
KafkaProducer设计的架构也不难理解,主要2个部分组成,即一个存储待发送的消息池(或者叫蓄电池),还有一条网络I/O线程(单线程),专门处理所有的request、response,这条线程会不断的从蓄电池获取发送消息去发送到broker,并且处理broker的response。本文主要讲本地缓存的元数据、蓄电池(包含批处理思想、内存池)、网络I\O线程(负责处理与broker的所有request和response),这三部分跟我们发送消息到broker有着密切的联系。
KafkaProducer设计的思想并不是每次调用一次send()就会去向Broker发送消息,而是一种基于内存池实现的批处理的池化思想的异步发送,设计这种思想有一定的优势就是多条消息汇总成一次发送,一定程度上是会带来性能上的提升,例如连续内存的申请或写入、网络I/O次数的减少等等。当然弊端也有,例如内存池资源不足时,发送消息会因申请资源不足而进入阻塞等待,即业务线程会阻塞;再者就是发送消息实际上是异步写入到本地缓存的批对象中,存在丢失消息的可能。PS:这里的异步写入从2个维度来说 :第一种维度:对于我们把消息发送到broker,可以说异步的;第二种维度:对于我们把消息写入到蓄电池,是同步的;而我说的异步写入是按第一种维度的说法。
KafkaProducer的网络I/O并没有直接引用Netty这个网络框架,而是作者自己基于JDK提供的原生NIO、I/O多路复用(Selector)实现的单线程I/O多路复用。(此处我想说,大佬就是强)
KafkaProducer的本地缓存了broker集群的元数据,在发送消息的时候可以基于这些元数据对消息进行负载均衡,元数据包括broker的信息(例如IP\Port)、Topic信息(例如某个topic有几个Partition)、Partition信息(例如topic对应的partition是分配到哪个broker)等等。缓存中的元数据并不是实时同步的,而是按一定的时间算法来同步。
如下图的红框:
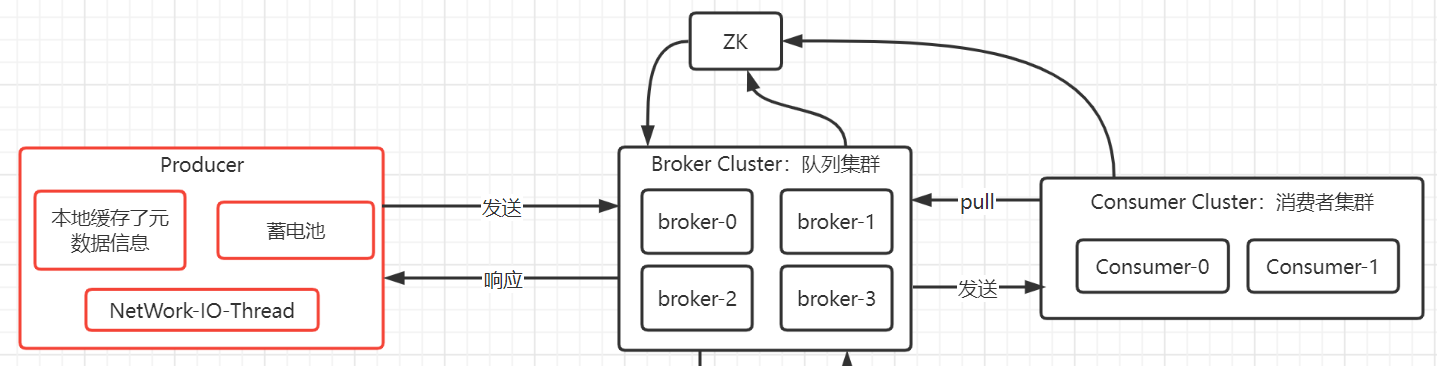
如下图,我们通过创建一个KafkaProducer对象,并且使用send()这个API来发送消息。KafkaProducer对于我们发送的消息,实际上是存储在蓄电池中,而真正执行发送消息是后台的一条网络I/O线程。我们发送消息其实是一个基于内存的异步操作,所以性能很快,由于是异步操作,send()也支持我们注册回调对象,即网络I/0线程收到broker的响应后会执行我们的回调对象,我们可以基于注册的回调对象来做业务处理。
元数据
KafkaProducer的本地缓存了broker集群的元数据,在发送消息的时候可以基于这些元数据对消息进行负载均衡。
通过构造器可以看到创建的元数据对象Metadata:

//说明一下几个入参参数
public Metadata(long refreshBackoffMs, long metadataExpireMs, boolean allowAutoTopicCreation,
boolean topicExpiryEnabled, ClusterResourceListeners clusterResourceListeners) {
//元数据的最快刷新时间间隔,默认值是100ms
this.refreshBackoffMs = refreshBackoffMs;
//元数据的最慢刷新时间间隔,默认值是300000ms,即5分钟
this.metadataExpireMs = metadataExpireMs;
//这个值如果为true,表示如果有个topic消息的请求到broker时,
//此时broker上没有该topic,那么会创建,实际上这个值生产环境大部分是false的
this.allowAutoTopicCreation = allowAutoTopicCreation;
//topic是否会过期
this.topicExpiryEnabled = topicExpiryEnabled;
this.lastRefreshMs = 0L;
this.lastSuccessfulRefreshMs = 0L;
this.version = 0;
//集群信息,这个存储了集群的信息
this.cluster = Cluster.empty();
this.needUpdate = false;
this.topics = new HashMap<>();
this.listeners = new ArrayList<>();
this.clusterResourceListeners = clusterResourceListeners;
this.needMetadataForAllTopics = false;
}
Cluster集群信息
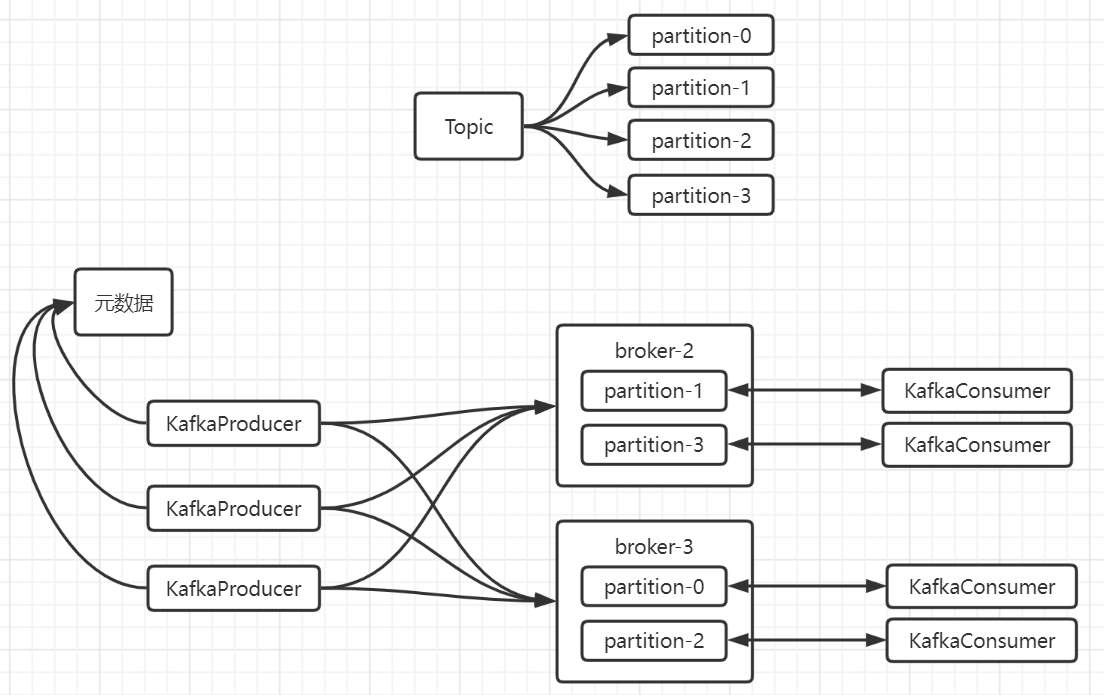
重点看一下Cluster,因为它记录了集群信息:kafka有个分区概念,即支持topic多个partition,这样可以达到并发写入消息的效果,并且partition不止与topic存在绑定关系,还跟broker绑定在一起,假设我在2个leader的broker节点集群中创建某个topic,将这个topic设置为4个partition,那么并不是在每个broker都为这个topic分配4个partition,而是把这4个partition分配到这2个broker节点。如下图:
如果理解了partition、topic、node这些概念,本地缓存的元数据信息就可以很清晰:

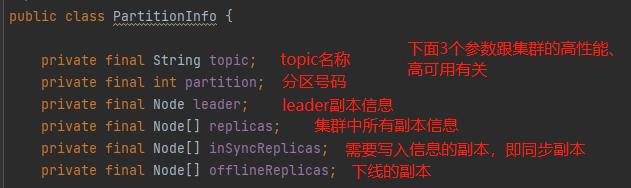
Node:

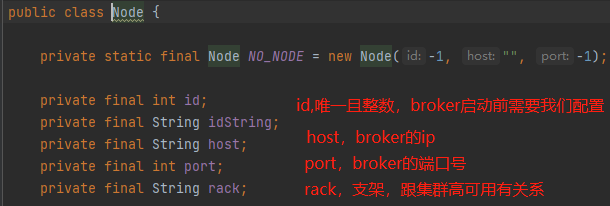
Cluster:
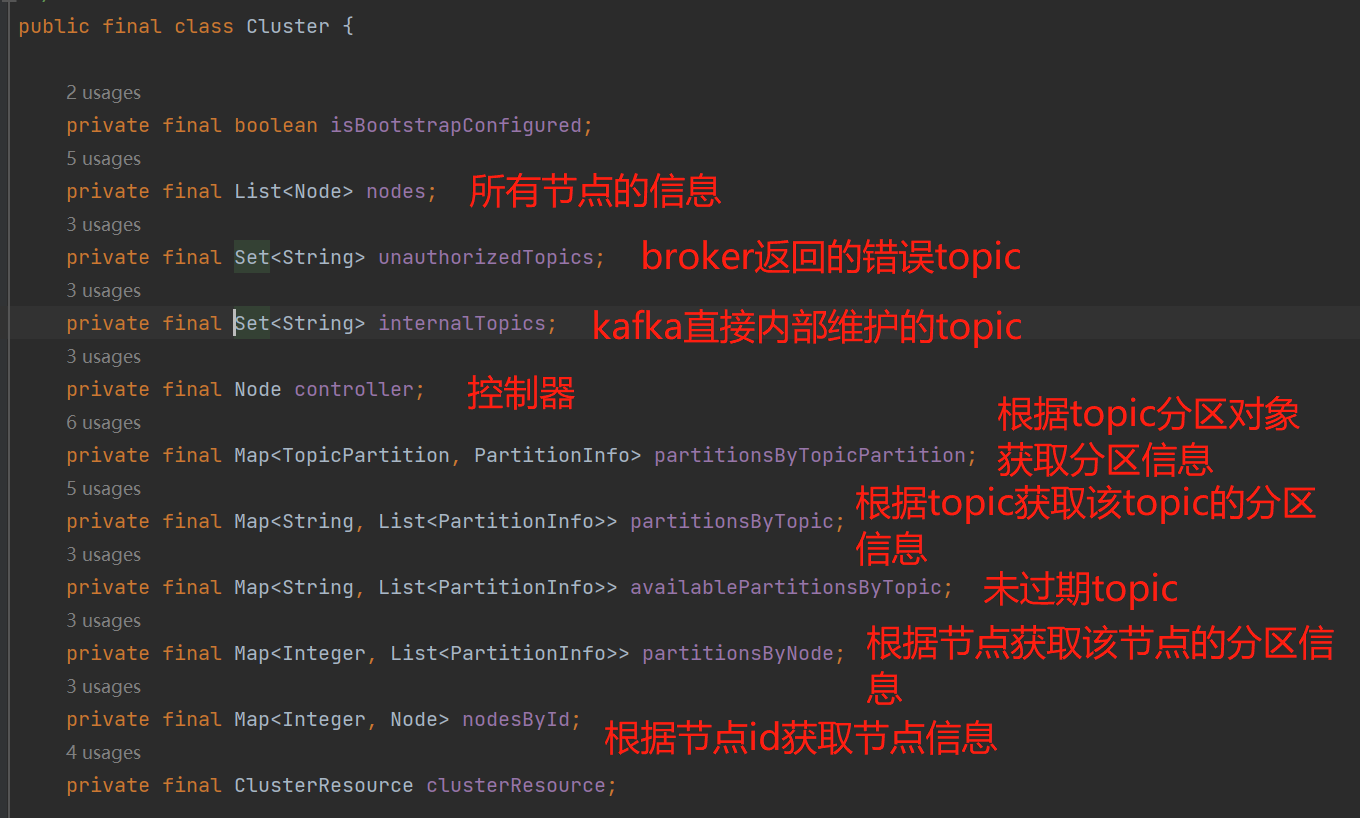
小结一下:每个topic可以设置不同数量的partition,并且在多leader副本节点的集群中,partition会分配在不同的节点中,以此来达到高性能的并发写入消息。本地缓存的元数据维护着每个topic对应partition信息以及partition是分配到哪个node。
Cluster集群信息刷新机制
本地缓存的元数据多久会进行刷新:网络I/O线程在每次对套接字进行实际的读写前都会根据 needUpdate 、 refreshBackoffMs、metadataExpireMs 来判断是否刷新元数据;PS:对套接字进行实际的网络I/O写操作,是已经准备好发送到broker的数据,如下图:
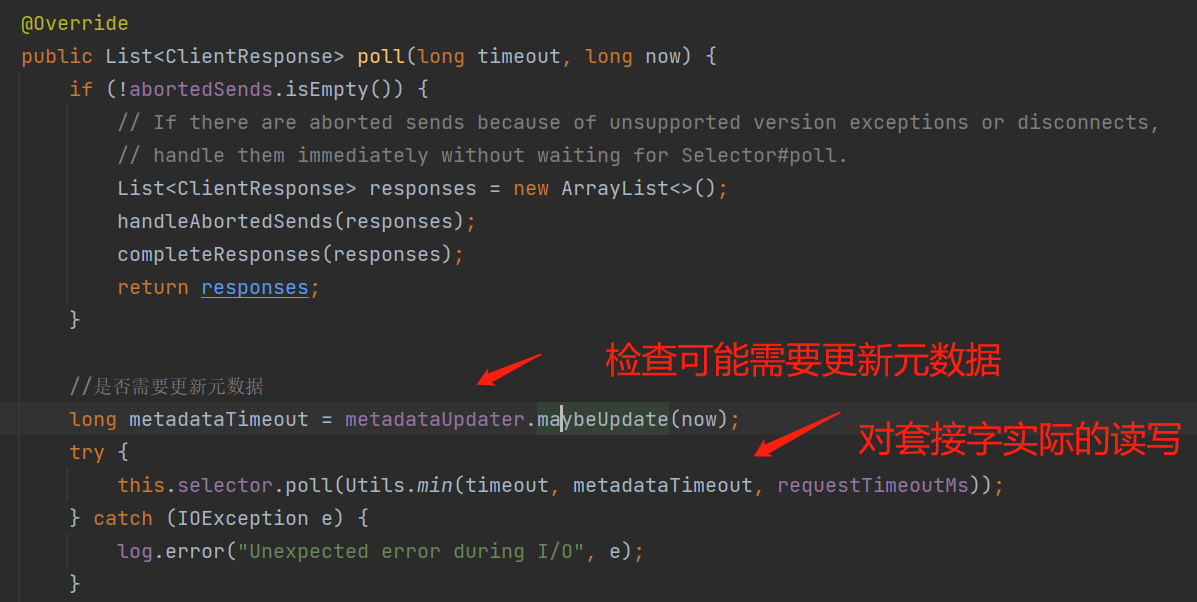
判断可能需要向broker发送刷新元数据的请求:
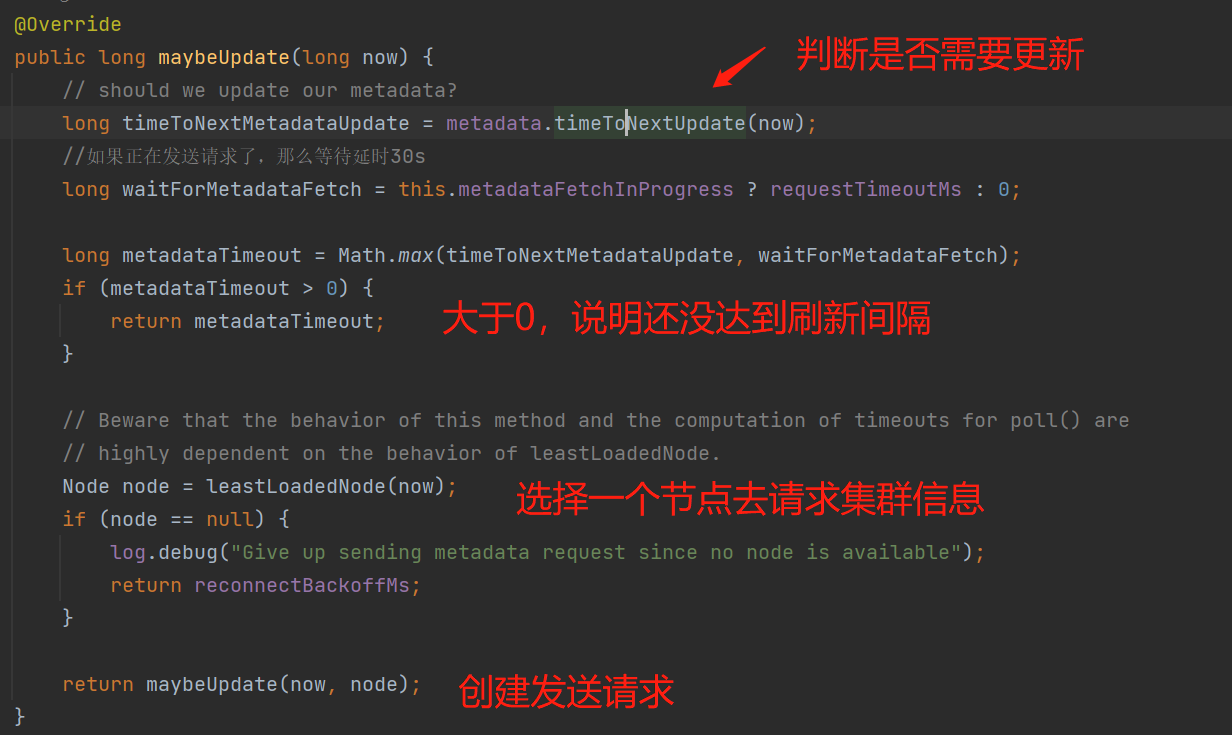
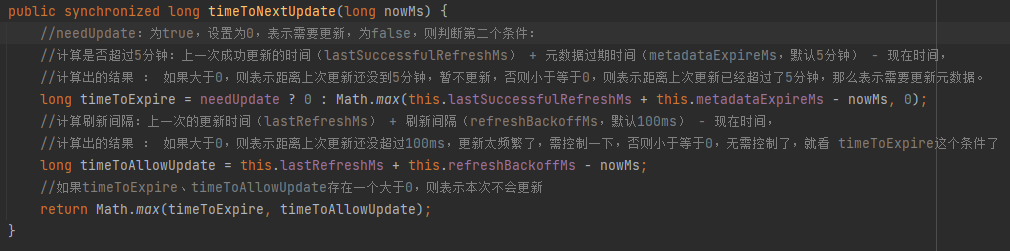
needUpdate:生产者在一些有感知的的场景下,需要强制刷新元数据,例如发送消息时,某个topic不在缓存的元数据中,那么需要强制更新一下,这个时候把needUpdate设置为true,表示不需要等到5分钟了 或者 发送消息时,手动传入的partition不存在缓存的元数据中,也需要强制刷新;
元数据默认最多5分钟(metadataExpireMs)的存活时间:上一次成功刷新的时间 + 元数据过期时间(metadataExpireMs,默认5分钟) - 现在时间 如果大于0,那么表示距离上次的刷新时间还没超过5分钟;
元数据默认保持最少100ms的更新间隔时间,避免了在某些失败场景下在紧密循环中重复发送请求。
讲几个例子:
- 新增一个broker节点,给某个topic新增2个partition,那么生产者是无感知的,此时生产者发送消息还是可以基于本地缓存的元数据进行负载均衡,但是某一时刻,发现距离上次刷新元数据已经超过了5分钟,那么就会触发更新请求,此时就会拿到最新的集群信息刷新到本地缓存;
- broker新增一个新的topic,生产者发送消息到这个新的topic,此时生产者是有感知的,因为他自己本地缓存的元数据确实没有这个新topic的元数据,那么此时他会把needUpdate设置为true,无需等到5分钟,而是判断100ms的刷新间隙和超时间隙(上一次更新还没响应,30s)。
当确实需要更新元数据请求时,会优先寻找比较空闲的节点去拉取元数据信息:
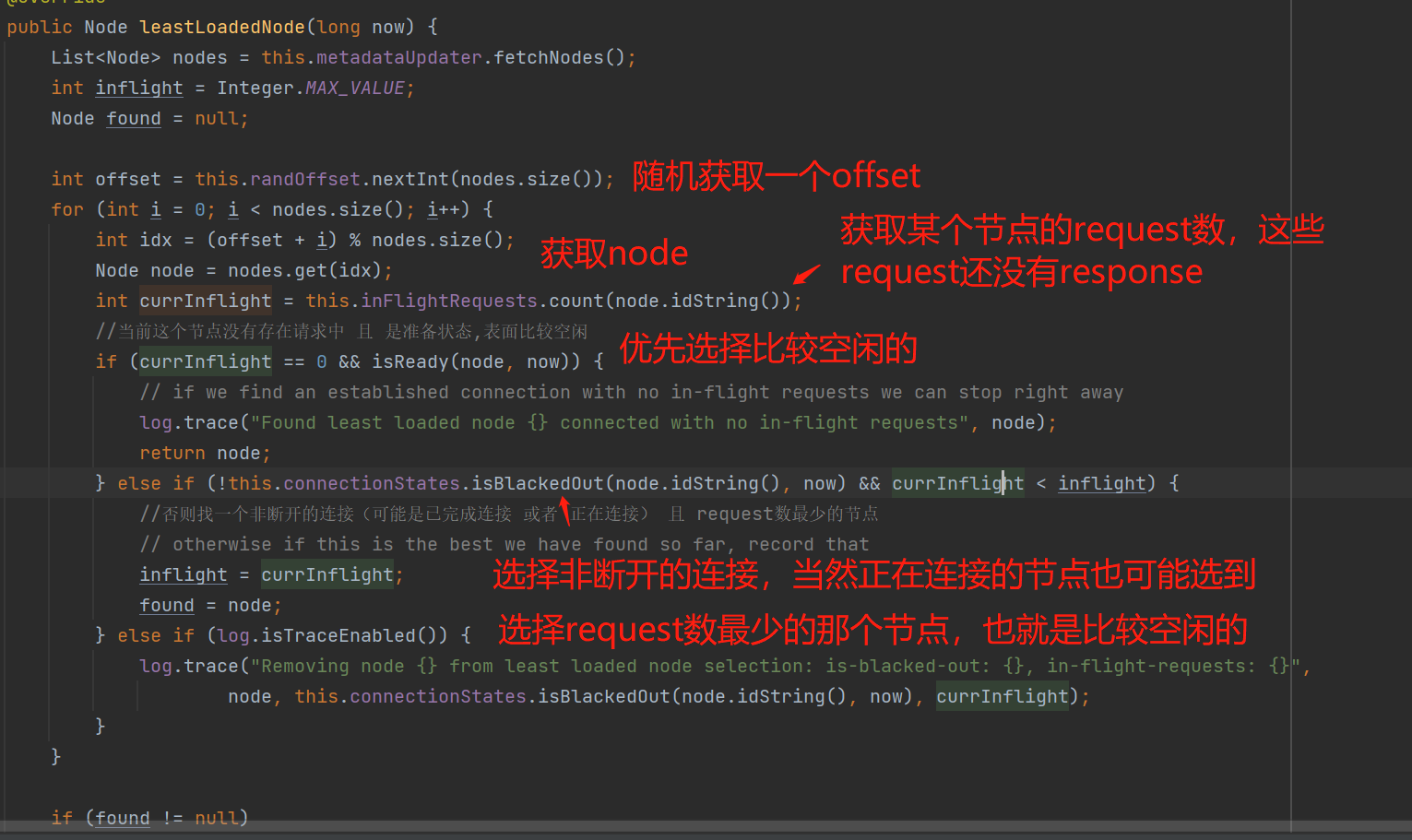
小结一下:本地缓存的元数据的刷新时间最快是100ms的间隙,最慢是5分钟的间隙,而当发现当前存在已经发送更新元数据的请求时,会等待30s(requestTimeoutMs)后才给发送下一次的更新元数据请求,即不会出现重复的请求。
蓄电池、批处理、内存池
KafkaProducer设计的思想并不是每次调用一次send()就会去向Broker发送消息,而是一种基于内存池实现的批处理的池化思想的异步发送,如下图:
简化版:

实际版:
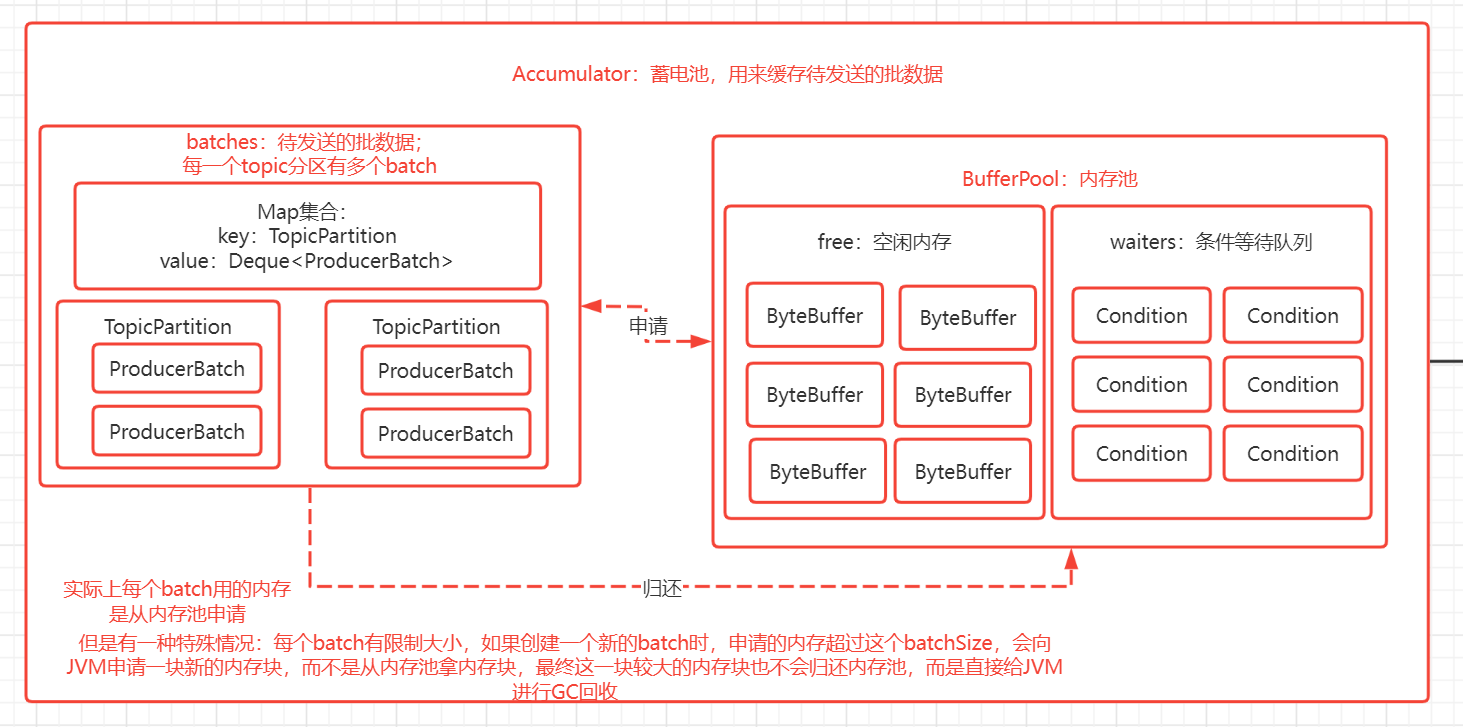
蓄电池
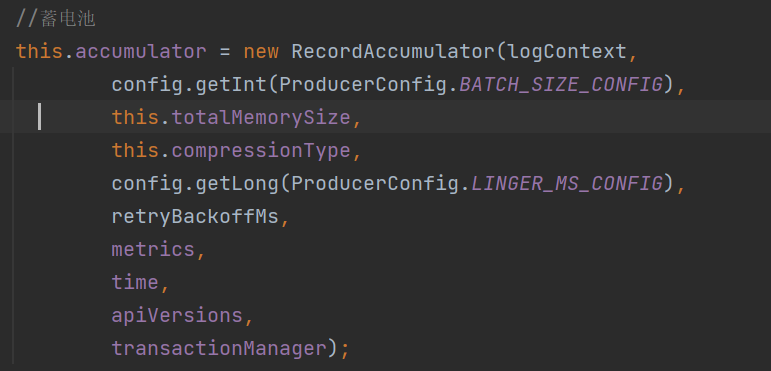
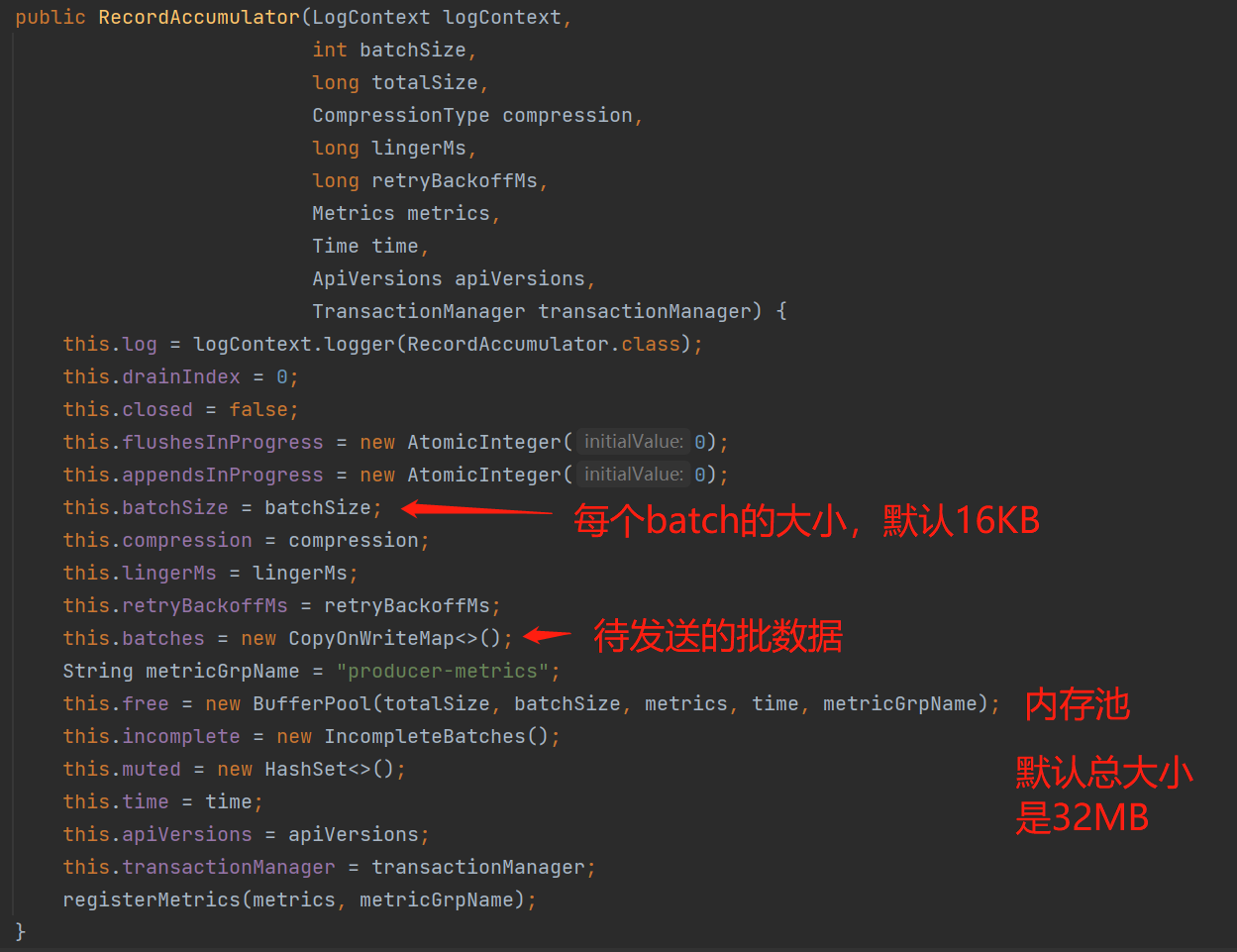
蓄电池:KafkaProducer采用蓄电池的概念来表示批处理、内存池思想,即池中存储着有待发送的批数据;生产者发送消息其实可以理解成往蓄电池中"蓄电"操作,而后台的网络I/O线程把消息发送到broker是蓄电池的"放电"操作。通过构造器可以看到创建的蓄电池对象RecordAccumulator:
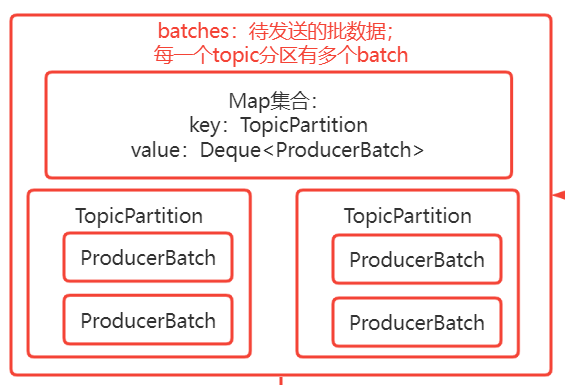
批处理
批处理思想:KafkaProducer采用批处理的思想,即我们发送的消息其实是写入到batches(如上图),batches是按Topic的partition的粒度把当前Topic的每个partition的批数据(ProducerBatch)映射缓存起来;当我们每次发送的消息,会根据当前topic的partitions进行负载均衡策略选择一个partition,然后从batches获取到当前Topic的partition的ProducerBatch的队列集合(每个TopicPartition有多个ProducerBatch),消息会被写入到最后一个ProducerBatch(当然可能这个ProducerBatch处于关闭状态(可以认为是拒绝写入状态,即这个批准备被发送到broker) 并且 内存不够了 ,那么会重新创建一个新的ProducerBatch来存储)。
蓄电池的"蓄电"操作:当我们调用send()来发送消息时,KafkaProducer是如何将消息放入到蓄电池的bathes:
- 1、创建TopicPartition:根据元数据进行负载均衡计算该消息要发送到的topic的partition;
- 2、写入到蓄电池,具体步骤从第3步骤开始;
- 3、尝试将消息写入到TopicPartition的ProducerBatch队列中:从batches中获取当前TopicPartition的批数据队列中队尾的ProducerBatch,然后把消息追加进这个ProducerBatch;
- 如果当前TopicPartition有批数据 并且 这个批数据队列中队尾的ProducerBatch处于非关闭状态,并且再判断一下是有足够的空间写入,那么把消息追加进这个ProducerBatch,本次的发送消息就结束了:
- 如果当前TopicPartition没有批数据 或者 有批数据,但是这个批数据队列中队尾的ProducerBatch处于关闭状态,或者 非关闭状态,需要再判断一下如果没有足够的空间可写入,那么需要创建一个新的ProducerBatch,即第4步骤;
- 4、创建一个新的ProducerBatch,创建前需要先从内存池中申请内存来使用,如果在限定的时间内申请到内存,那么接下来就是把发送消息写入到这个新的batch,写入后这个batch会从队列的末端加入:
- 如果内存不足的话,会进入超时等待,默认等待最长时间是1分钟,超时等待后会抛出超时异常;在超时等待过程中,可能会被唤醒,即其他线程向内存池归还内存块后,发现存在等待线程的话会进行唤醒操作,例如网络I/O线程会处理response的请求后归还内存,并且发现存在等待线程的话,会唤醒等待资源的线程;
- 如果内存充足的话,正常情况下是直接从BufferPool申请,特殊情况是当前申请的内存超过batchSize,或者 申请一块batchSize大小的内存块,而池中却没有已创建好的内存块,那么需要进行一次JVM申请内存的操作。
1、创建TopicPartition

TopicPartition的数据结构如下:
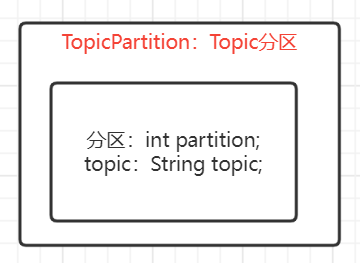
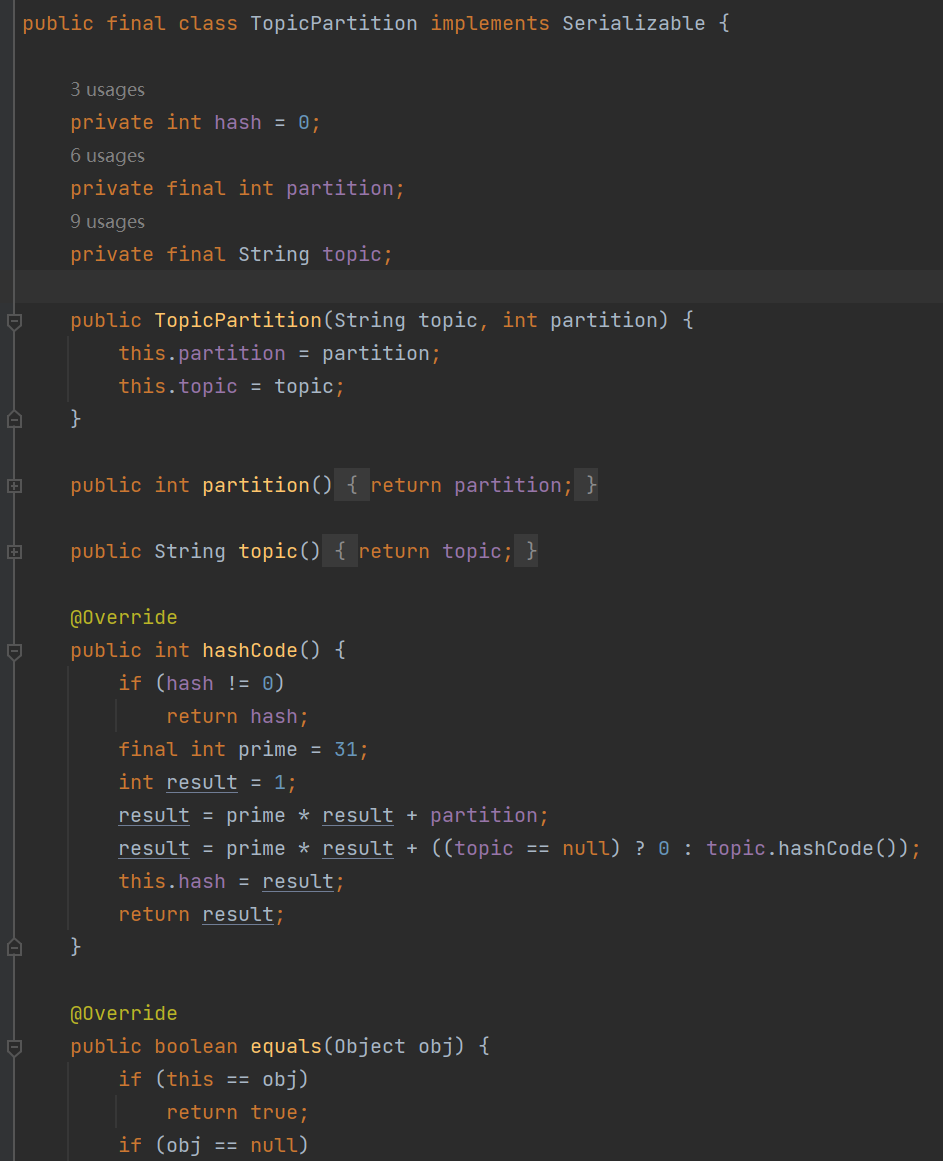
支持自定义负载均衡规则:实现Partitioner,重写partition()这个API即可。

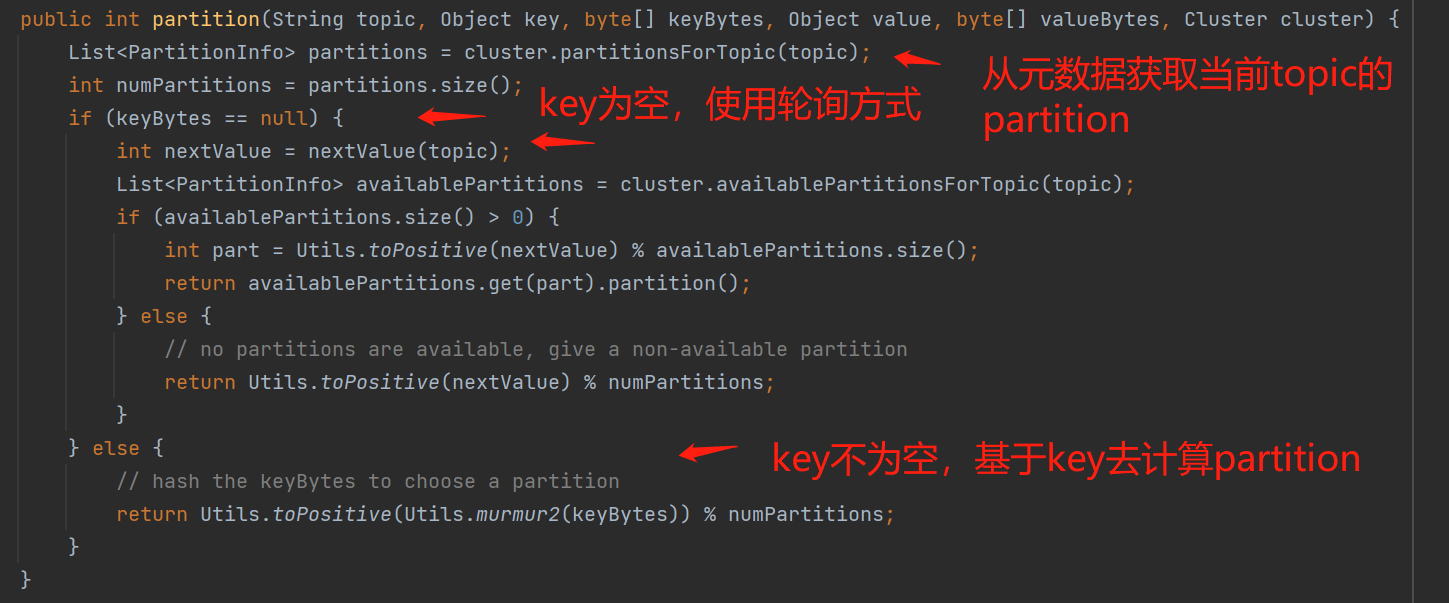
kafka的默认规则(DefaultPartitioner):如果发送的消息的key为空,那么基于轮询的方式进行负载均衡;否则key不为空,那么基于key计算出一个32位哈希值与分区数进行取余:
2、写入到蓄电池
通过调用RecordAccumulator的append()把发送消息添加到蓄电池,具体步骤从第3步骤开始:

3、尝试将消息写入到TopicPartition的ProducerBatch队列中
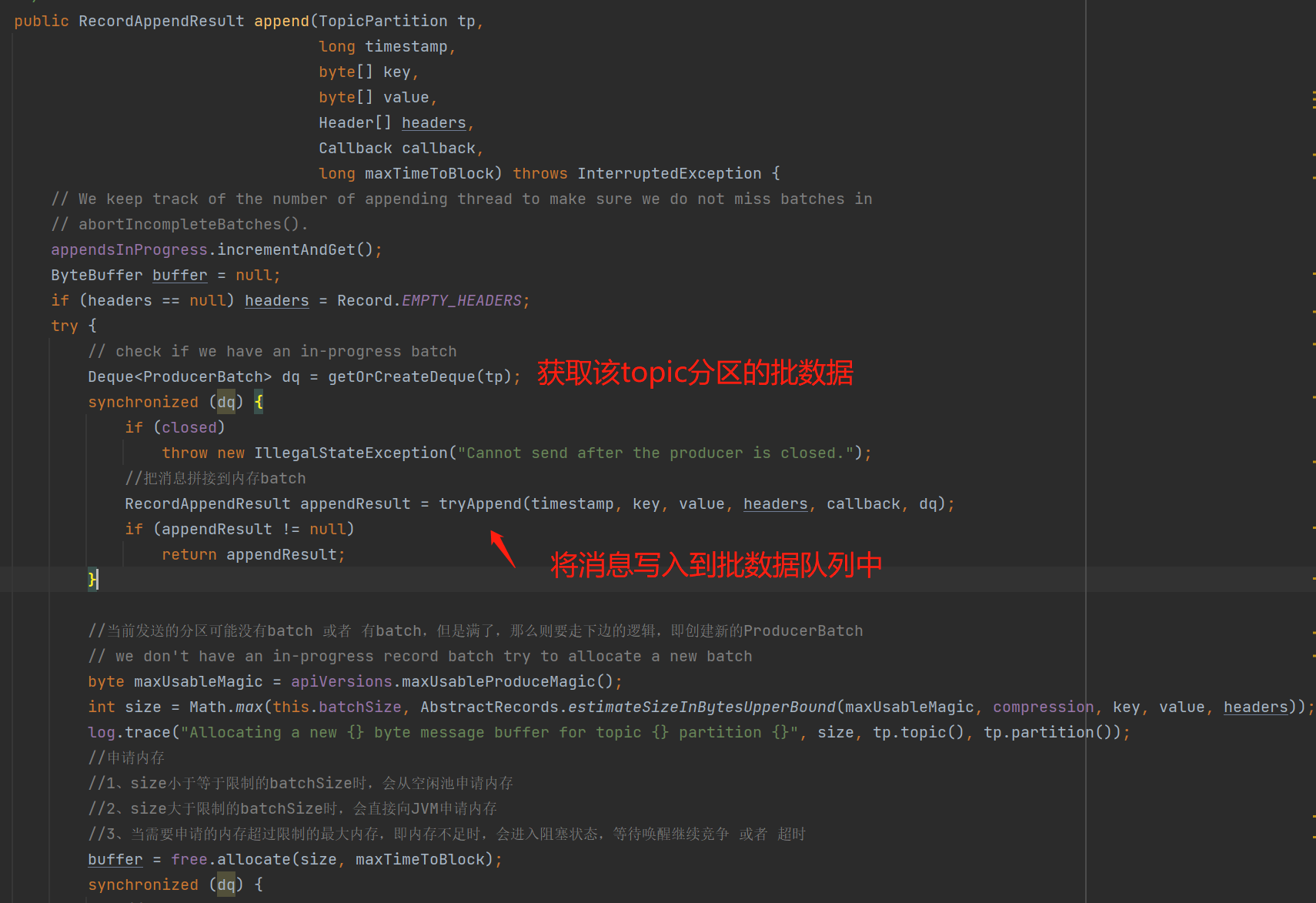
具体看看tryAppend():这个方法返回为null的话,那么表示写入失败,需要创建一个新的ProducerBatch来写入消息。

PS:上图的last.tryAppend()表示尝试把发送消息拼接到该batch中,具体判断逻辑要结合看下面的第4步骤比较清晰。
小结一下:我们发送的消息,会被写入到batches这个Map集合,这个集合的映射关系是将每个topic的partition和ProducerBatch队列映射起来,即消息会被写入到TopicPartition的ProducerBatch队列中,而写入的规则也很简单,会取该队列中队尾的ProducerBatch来写入。当然有可能因为该ProducerBatch没有足够的空闲内存 或者 处于关闭状态(只要之前被触发过一次没有足够的空闲内存,这个batch就会被设置为关闭状态,或者 即将发送到broker的也会被设置为关闭状态)而写入失败,具体判断规则要看看第4步骤的last.tryAppend()。
4、创建一个新的ProducerBatch,并把发送消息写入到这个新batch,写入后这个batch会从队列的队尾加入
第3步骤中如果当前的TopicPartition没有批数据 或者 从批数据队列中队尾的ProducerBatch写入失败,需要创建一个新的ProducerBatch来存储我们的发送消息:
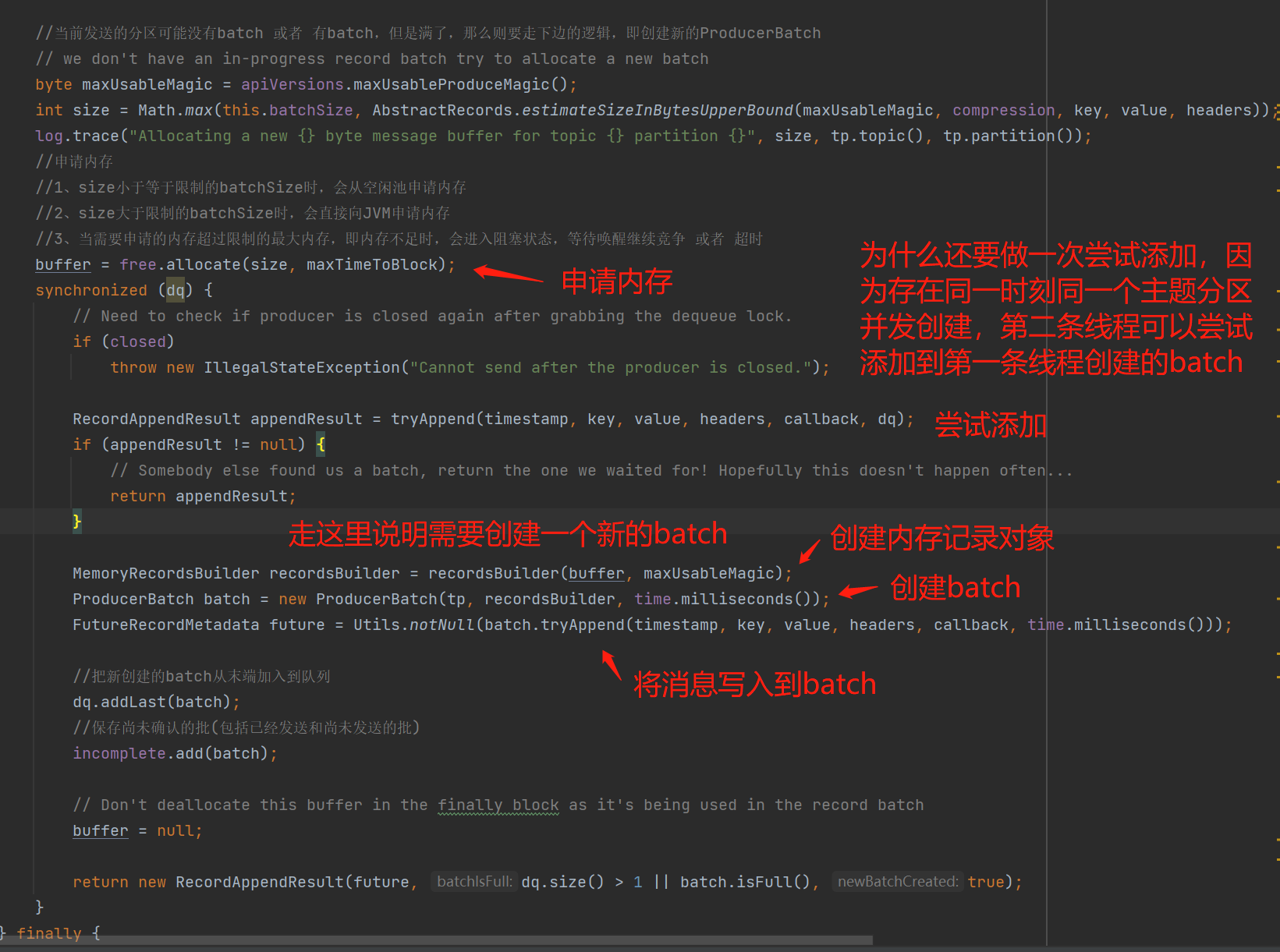
上图可看到当创建一个新的ProducerBatch前,会先申请内存,成功申请内存后,第一步还是再一次尝试拼接到批数据队列中的队尾中,如果成功了,那么申请的内存也没有用到,会走finally归还到内存池中;但是如果确实还是失败了,那么会真正的创建ProducerBatch和MemoryRecordsBuilder来写入消息,MemoryRecordsBuilder看名称就可以大概知道,是一个针对内存缓存区进行记录操作的对象,而ProducerBatch就是批数据的一个对象,实际上真正的操作是基于MemoryRecordsBuilder。
看看ProducerBatch和MemoryRecordsBuilder,再看看申请内存的具体逻辑:
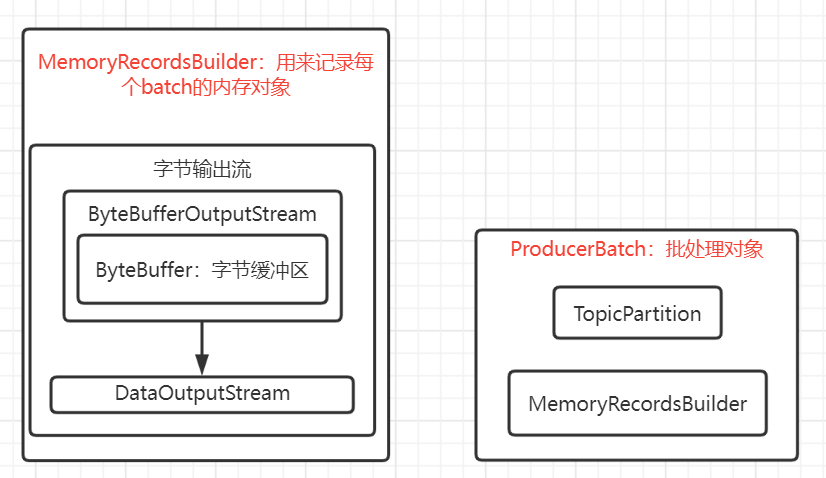
MemoryRecordsBuilder:用于记录发送消息数据的内存记录对象;
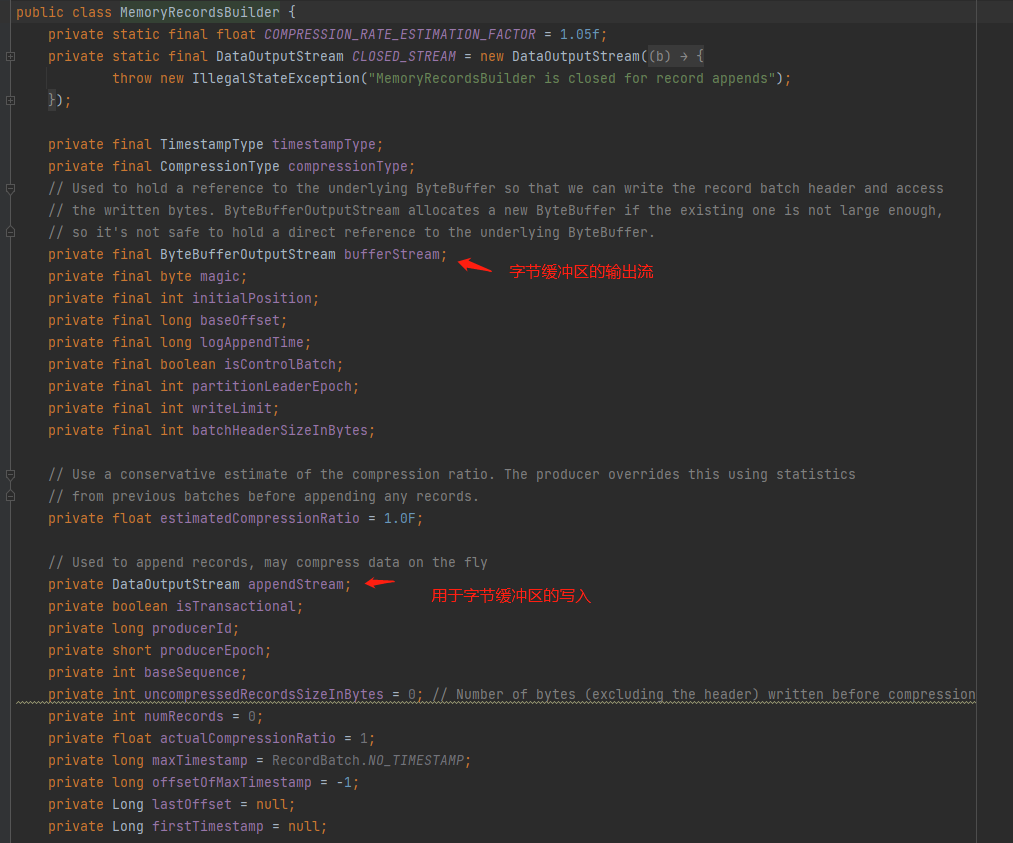
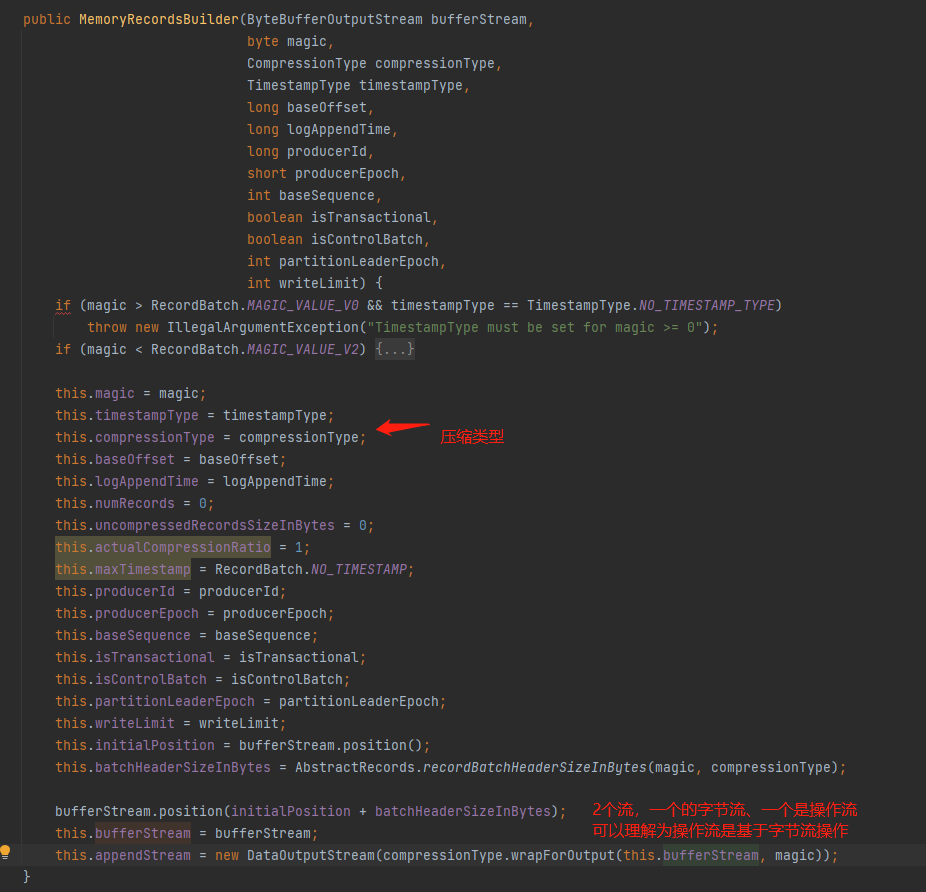
上图的ByteBuffer就是我们从内存池申请到的内存对象,即字节缓冲区。
ProducerBatch:批数据对象。
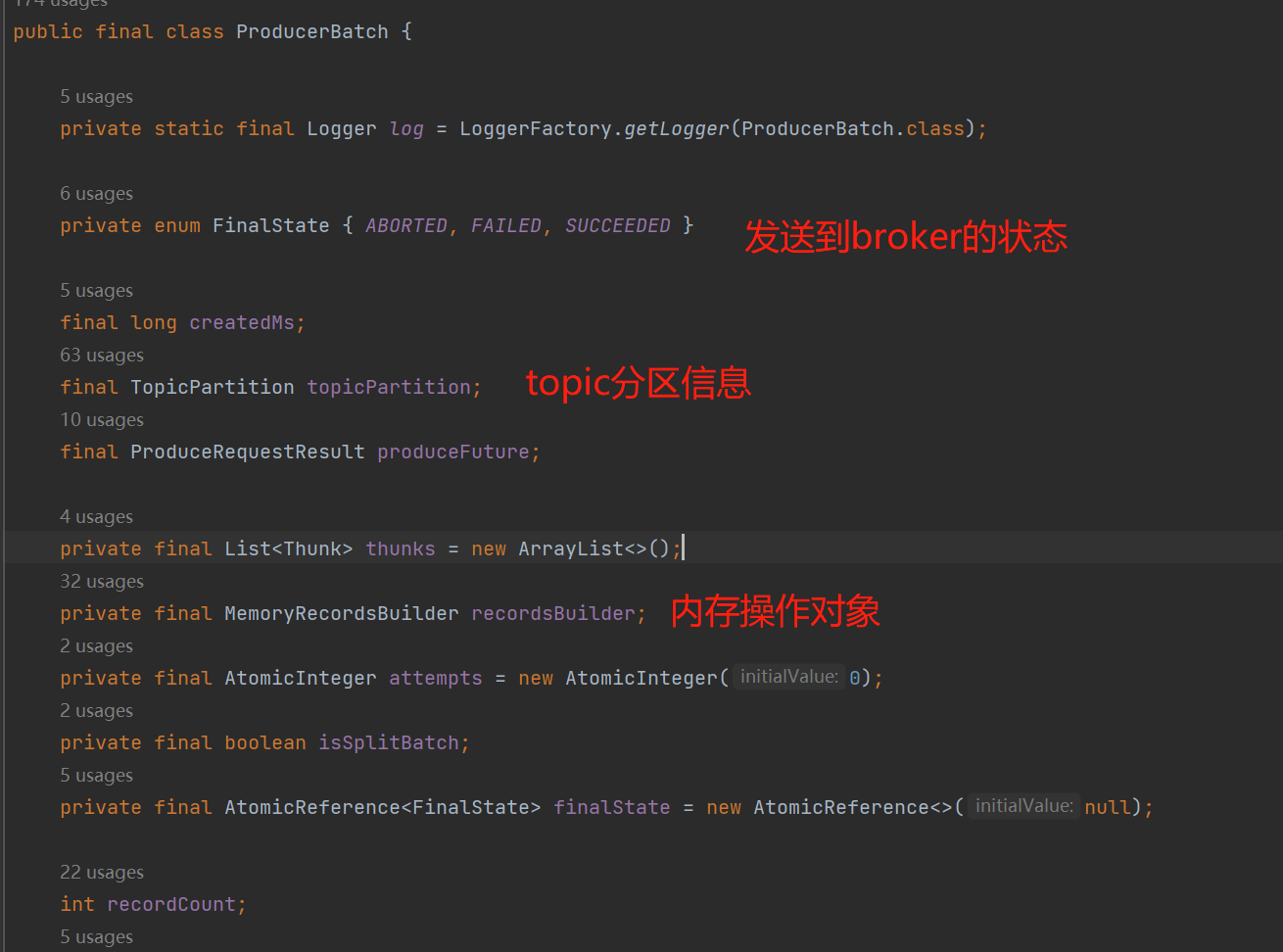
理清了ProducerBatch、MemoryRecordsBuilder的结构,那么再回头看看last.tryAppend():实际上是把我们发送的消息写入到MemoryRecordsBuilder这个内存记录对象。
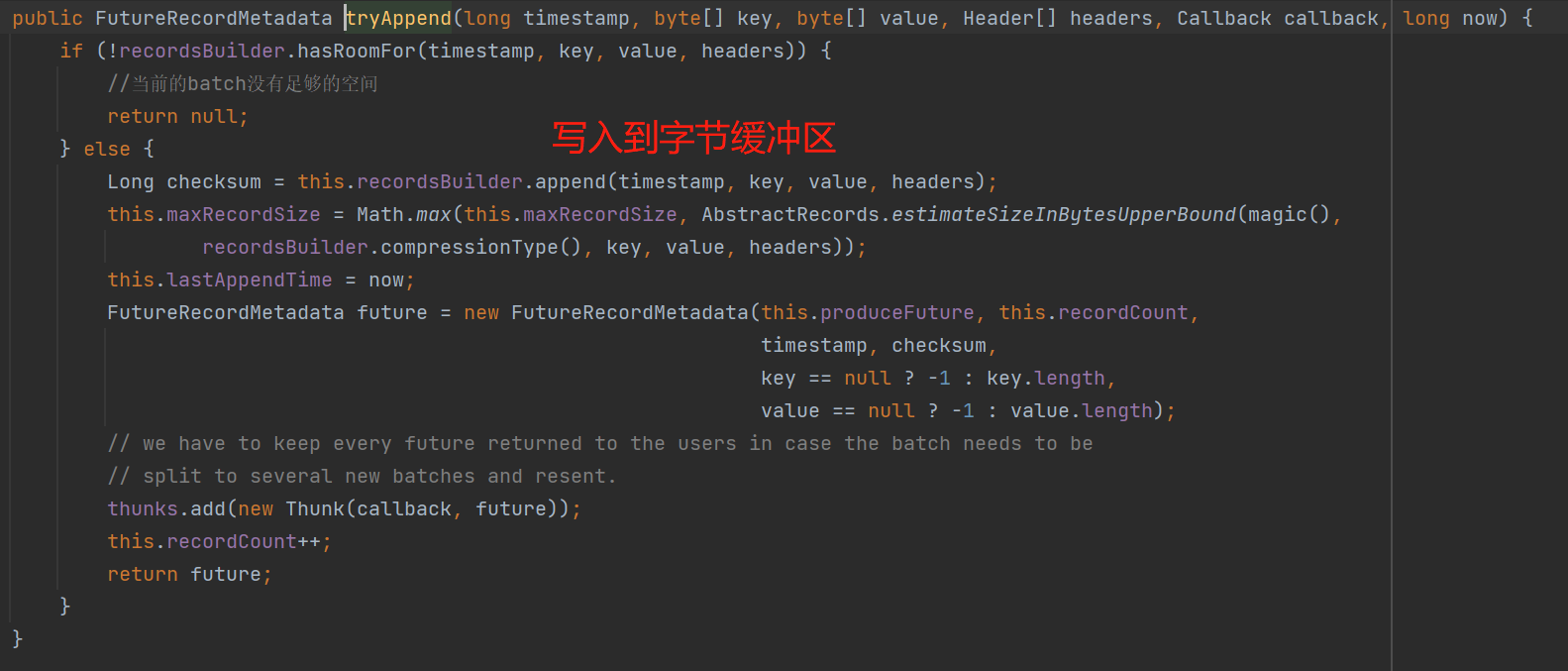
最终调用如下图的API,即通过操作流写入到ByteBuffer中:
小结一下:我们发送的消息,会写入到ProducerBatch,实际上是MemoryRecordsBuilder通过DataOutputStream数据操作流对ByteBufferOutputStream的字节缓存区(ByteBuffer)进行操作,DataOutputStream是一个数据操作流,而操作的字节缓存区是ByteBufferOutputStream的ByteBuffer,所以最终我们的消息其实是写入到ByteBufferOutputStream的ByteBuffer这个字节缓存区中。
可能你有疑惑一:为什么申请内存后第一步还是尝试拼接到批数据队列中的队尾,而不是直接创建一个新的batch来写入,因为走到这里确实是因为写入失败需要创建一个新batch来存储。下面我模拟了一个场景来解释一下,如下流程图,可能有点乱,但是你跟着数字顺序看应该会比较清晰:
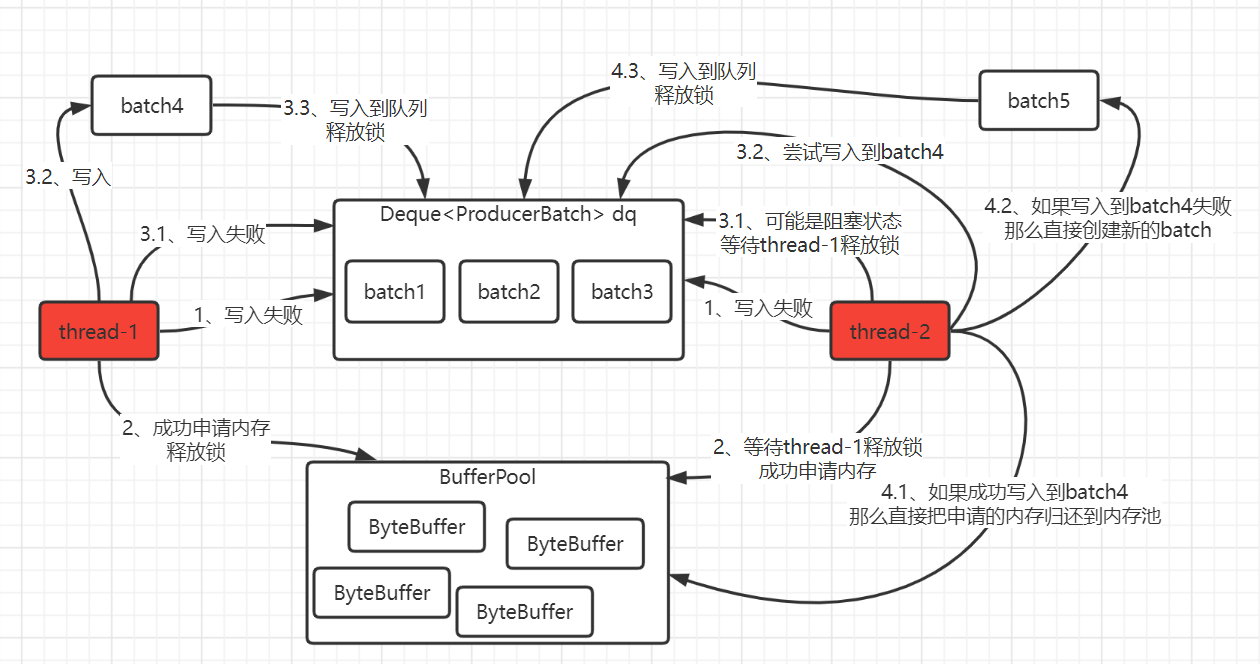
假设场景:2条线程(如图中thread-1、thread-2)在同一时刻要对同一个TopicProducer的batch队列写入消息,并且都写入失败了,那么都需要创建一个新的batch来写入消息:
- 第1步骤:thread-1、thread-2都写入batch3失败,那么都需要创建一个新batch来写入消息,创建新的batch前是先从内存池申请内存,如下第2步骤;
- 第2步骤:thread-1、thread-2从内存池中申请内存,由于锁的原因,所以同一时刻只有一条线程执行申请内存,这里假设thread-1优先拿到锁,那么优先申请到内存,thread-2会等待thread-1释放锁后唤醒继续申请内存池的资源;申请到内存的线程会开始把发送消息写入batch,具体看第3步骤;
- 第3步骤:申请到内存的线程,那么尝试拿到batch队列的锁,拿到锁就有资格对这个batch队列来写入数据,写入数据的第一步是尝试把发送消息加入到batch队列,并不是创建一个新batch来写入消息;现在假设thread-1优先拿到锁,将尝试加入到batch队列的batch3,在上图这个2条线程的场景中,肯定是失败的(3.1步骤),那么会创建一个新的batch4来写入消息(3.2步骤),写入后把batch4放入到batch队列的尾部中,并且释放锁,至此thread-1的任务就完成了;由于thread-1已经处理完成,释放了锁,thread-2会被唤醒(3.1步骤),进行尝试写入到batch4(3.2步骤),写入有2种结果,要么batch4足够的内存、要么没有足够的内存,具体的看第4步骤;
- 第4步骤:
- 4.1:第一种情况就是thread-1新创建的batch4,有足够的空闲内存供我用,那么我就不用创建一个新的batch了,直接写入到batch4就行,写入成功后,由于刚刚申请的内存没用到,那么直接归还给内存池;
- 4.2~4.3:另一种情况就是thread-1新创建的batch4的空闲内存也不够我用,那么我自己就创建一个新的batch5来写入消息,并且把batch5写入到队列末尾中。
通过上面的场景,第4步骤的逻辑应该可以知道为什么把发送消息写入batch队列失败后进行申请内存后,是优先尝试把发送消息写入到batch队列,而不是直接创建一个新的batch来写入发送消息。
可能你有疑惑二:申请内存这句代码为什么不是在确实需要创建一个新的batch的时候再去执行申请内存,而现在是无论需不需要创建新的batch(很大概率需要),都会优先申请内存:
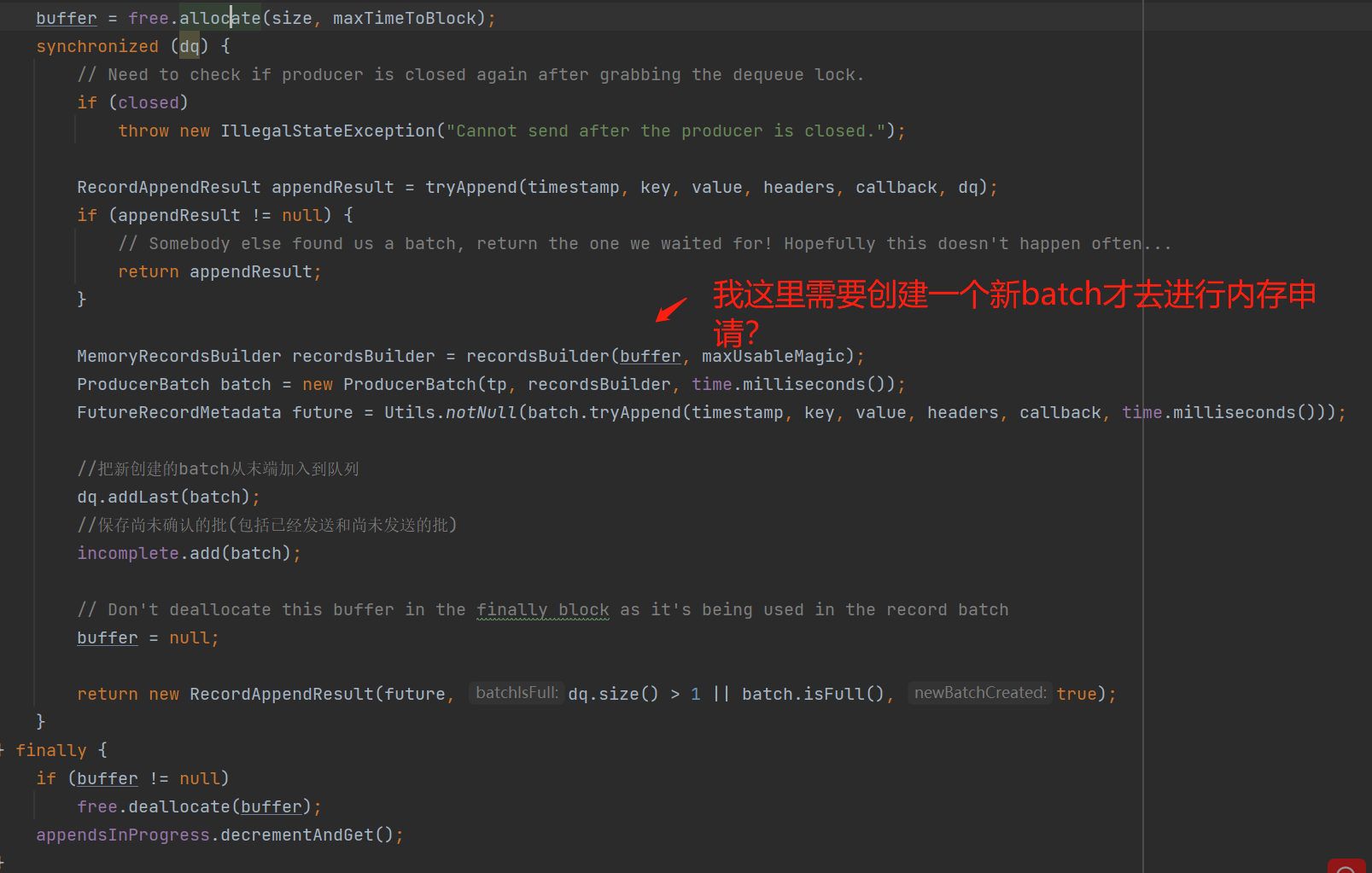
后来细想了一下,我的想法设计并不合理:因为向内存池申请内存这个操作有用到一个锁,而且操作batch队列也用到另一个锁,如果把申请内存这个操作也挪到操作batch队列的锁代码块中,那么可能会出现一条线程可能同时拿2个不同的锁,这应该不是一个很好的代码规范,所以如果有遇到一条线程需要不同作用锁的设计场景,建议尽量还是分离开来。
小结一下:
- batches缓存了每个TopicPartition的批数据(是个队列,有多个batch),实现了批处理的思想;
- 我们发送的消息会拼接到一个个的ProducerBatch,ProducerBatch实际上是使用MemoryRecordsBuilder这个内存记录对象来记录发送消息。
- 当需要创建一个ProducerBatch前会先从内存池申请内存。PS:相关逻辑可以看看下面的内存池这一目录。
内存池
内存池(如下图的BufferPool)中的free存储着已经创建好的空闲ByteBuffer,在正常情况下,当需要创建一个ProducerBatch的时候,会先提前跟BufferPool拿一块大小为batchSize的内存块(BufferPool规定了池中每个内存块都是batchSize的大小)来使用,如果free有已经创建好的,那么直接从free拿即可;而特殊情况是:如果创建一个新的ProducerBatch需要的内存超过这个batchSize,由于池中每个ByteBuffer都是batchSize大小,那么不能从free拿已经创建好的内存块,而是需要进行一次JVM申请内存块的操作,并且这个超过batchSize的内存块在用完后最终也不能归还到free,而是直接交给JVM进行GC回收。PS:KafkaProducer默认设置内存池的大小是32MB,并且每个batchSize默认是16KB大小。
当内存池的资源不足时,需要申请内存的线程会进入超时等待状态,等待有内存被归还时就会被唤醒继续竞争内存资源。(如下图的waiters)

如上图:内存池中维护着一些已经创建好的字节缓冲区;一些需要申请资源的线程在资源不足的情况下会进入挂起等待状态,一个Condition你可以理解成对应一条阻塞等待线程。
内存池的数据结构,如下图:
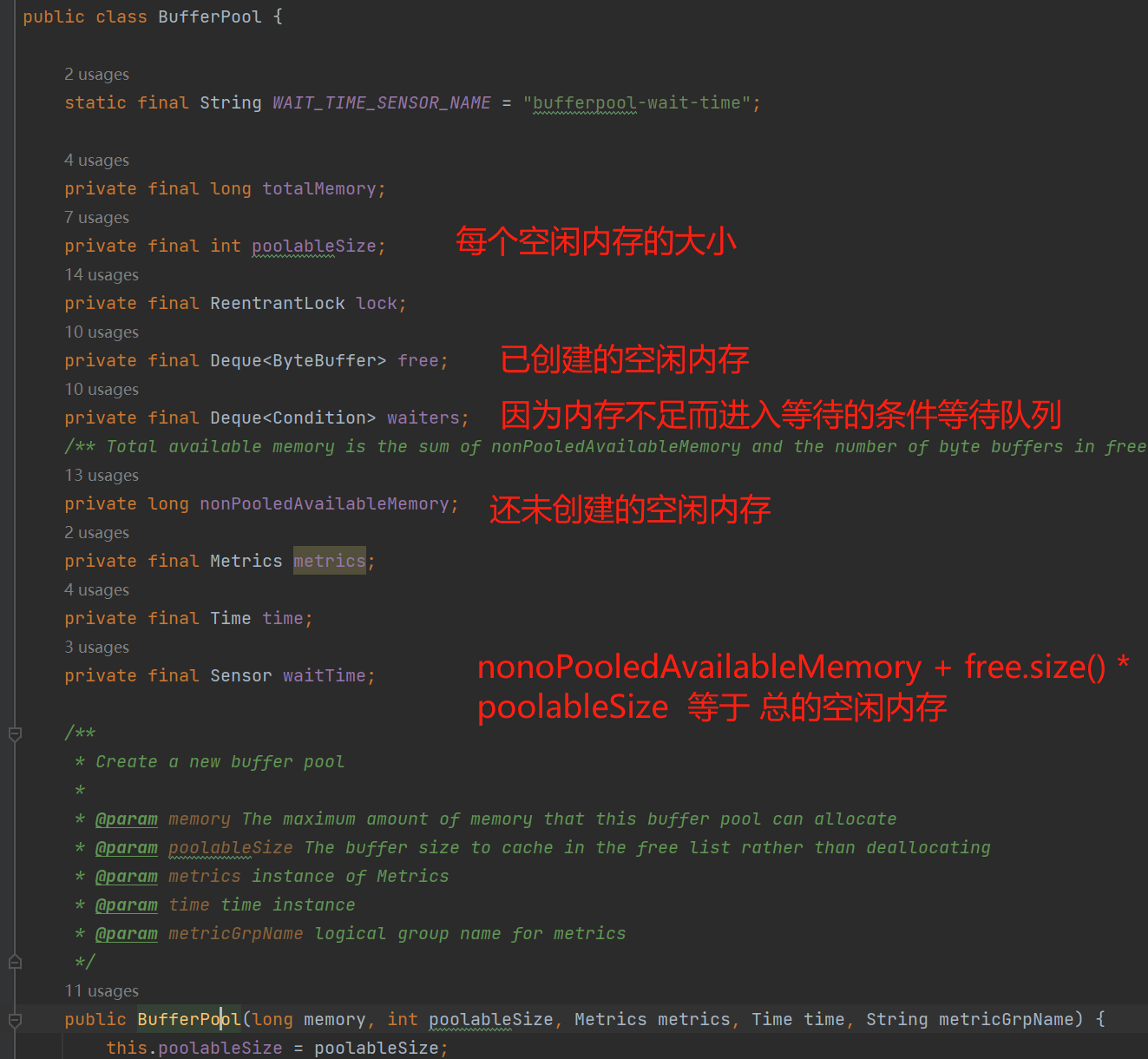
为什么有这个内存池?内存池的优势就是内存资源的控制与复用:
- 内存资源复用的优势:当需要申请内存时,无需执行一次内存申请操作,而是向内存池获取即可,这样也可以避免了频繁的创建、销毁进而导致堆内存中存在大量的垃圾对象。
- 内存资源控制的优势:当系统资源比较稀缺时,也可以防止OOM。
当然内存池是一把双刃剑,也有劣势:
- 内存资源复用的劣势:我们知道,内存的申请都是"一步到位",即连续内存,这也是为什么Kafka默认规定了池中每一块内存块都是16KB的大小,在大部分场景下,我们发送的消息都是小于16KB,但是在某一天由于一名"不成熟"的程序员发送了一条大于16KB的消息,那明显池中单个ByteBuffer不够使用,怎么办?2个方案:第一种方案就是:把发送的消息进行拆分成N个小于等于16KB的消息,然后向内存池申请N个内存块来使用,这个方案需要两端配合,即客户端要拆分,服务端要合并(可能还包括顺序问题),极其复杂,所以这个是一个不建议、不合理的设计方案;第二种方案就是:大于16KB的消息不向内存池拿ByteBuffer了,而是从JVM申请一块新的内存块,我需要100KB的内存就申请一块100KB的内存,简单粗暴,Kafka就是采用这种方案,但是如果我们很频繁的去发送大于batchSize的消息,那么这种情况就需要进行一次JVM申请内存的操作,用完也不会把内存块归还到free,所以内存池资源复用的优势就很难发挥出来了,这个问题我们应该避免,例如调大batchSize值 或者 减小发送消息的大小。
- 内存资源控制的劣势:当内存池的资源不足时,需要内存资源的线程怎么办呢?2个方案,第一种方案就是:直接执行一次JVM申请内存的操作,无需等待,那么这个内存池的概念就不复存在了;第二种方案就是:业务线程会挂起进入阻塞等待状态,等待有资源归还时会被唤醒继续竞争内存资源,Kafka就是采用这种方案,但是对于业务线程会进入阻塞状态,所以我们应该尽量避免这种情况,因为kafka设计的初衷是异步批处理写入这种高性能思想,所以如果可以的话,尽可能的调大内存池的容量。
接下来看看申请内存的逻辑,buffer = free.allocate(size, maxTimeToBlock),即向内存池申请内存,由于这个函数的幅度较大,所以我截成多张图片来显示 :
申请内存的逻辑其实很简单,作者做的设计也很巧妙:
- 第1步骤:根据当前申请的内存容量判断是否可以从free拿内存块:
- 如果当前申请的内存容量等于batchSize,那么再判断当前free中是不是存在空闲内存块:
- 如果free中有空闲内存块,直接从free拿一块来使用,那么本次的申请内存操作就结束了;
- 如果free中没有空闲内存块,那么可能需要通过JVM申请一个batchSize大小的内存,如下第2步骤;
- 如果当前申请的内存容量超过batchSize,不向free拿内存块了,而是需要通过JVM申请一个新的内存块,如下第2步骤;
- 第2步骤:申请前需要判断当前内存池的空闲内存容量是否充足:this.nonPooledAvailableMemory + free.size() * batchSize = 总空闲内存
- 空闲内存充足:如果 总空闲内存 大于等于 当前要申请的内存容量,那么允许从JVM申请内存,无需阻塞等待,则执行第3步骤;
- 空闲内存不充足:如果 总空闲内存 小于 当前要申请的内存容量,那么需要挂起、阻塞当前线程,并进入等待阻塞队列(waiters),等待被唤醒:
- 被唤醒后有2种不需要向JVM申请内存的情况:一种情况是当前申请的内存容量是batchSize 并且 free有内存块(阻塞期间其他线程归还了),那么从free拿;另一种情况是在限定的等待时间内不能获取到本次申请内存的容量,则抛出超时异常;
- 被唤醒后有2种需要向JVM申请内存的情况:前提条件:在限定的等待时间内能获取到本次申请内存的容量,那么,一种情况是超过batchSize的申请,这种肯定需要进行一次JVM申请内存的操作;另一种情况是等于batchSize的申请,但是free为空;这两种情况会执行第3步骤;
- 第3步骤:执行JVM申请内存操作。
1、根据当前申请的内存容量判断是否可以从free拿内存块
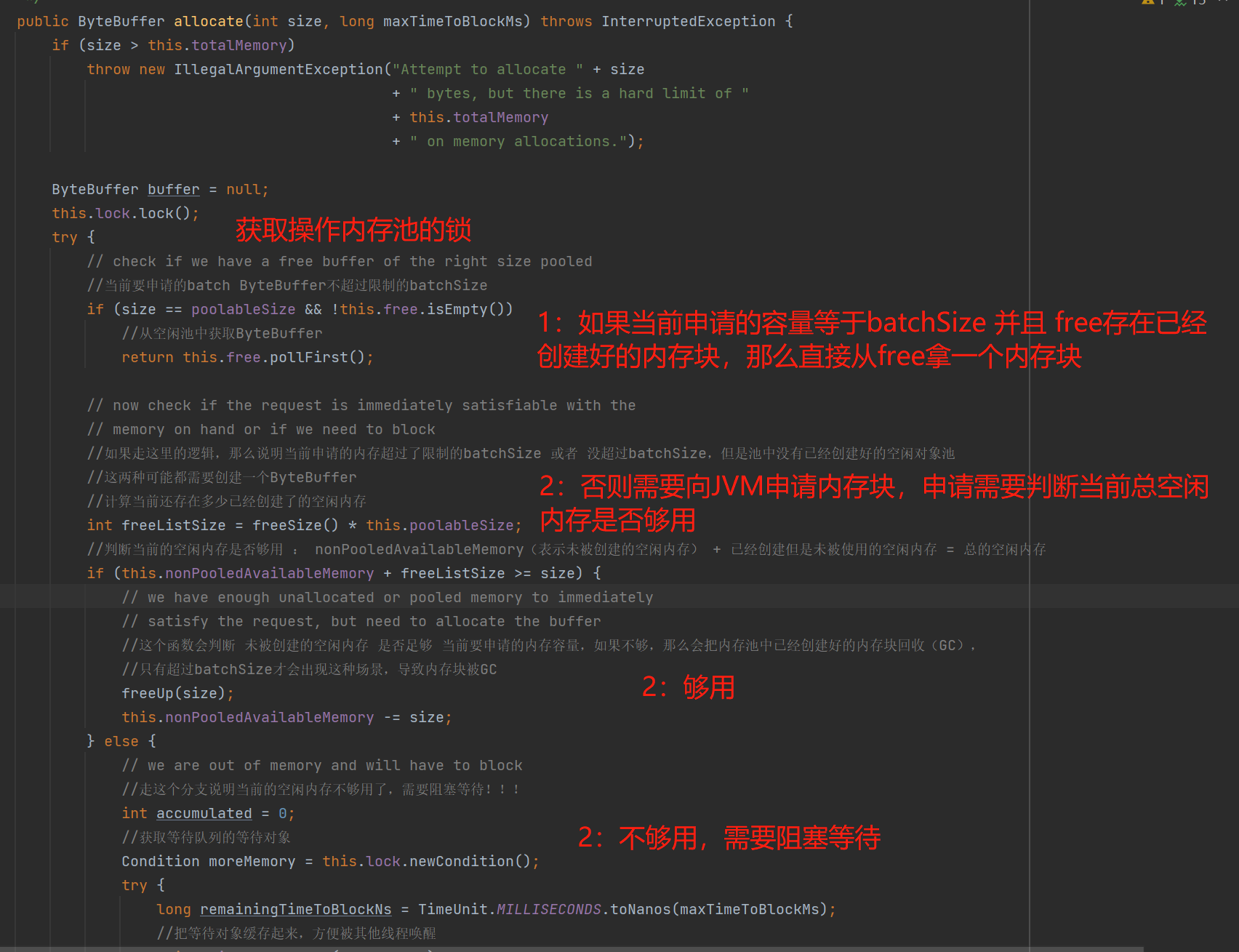
如上图:当第1步骤是从free拿ByteBuffer,那么本次申请内存的流程就结束了,无需从JVM申请内存这一操作。但是如果超过batchSize 或者 等于batchSize ,但free没有已经创建好的ByteBuffer,那么需要往下走,判断当前内存池的空闲内存容量是否充足,如下的第2步骤。
2、申请前需要判断当前内存池的空闲内存容量是否充足
走第2步骤的逻辑,说明当前不能从内存池拿内存块,需要向JVM申请内存,申请前需要判断当前的空闲内存容量是否充足,这个步骤有2个逻辑的代码块,即空闲内存充足或者空闲内存不充足。
1、先看空闲内存容量充足的代码块 :this.nonPooledAvailableMemory + freeListSize >= size 为true时,表示当前空闲内存容量足够。
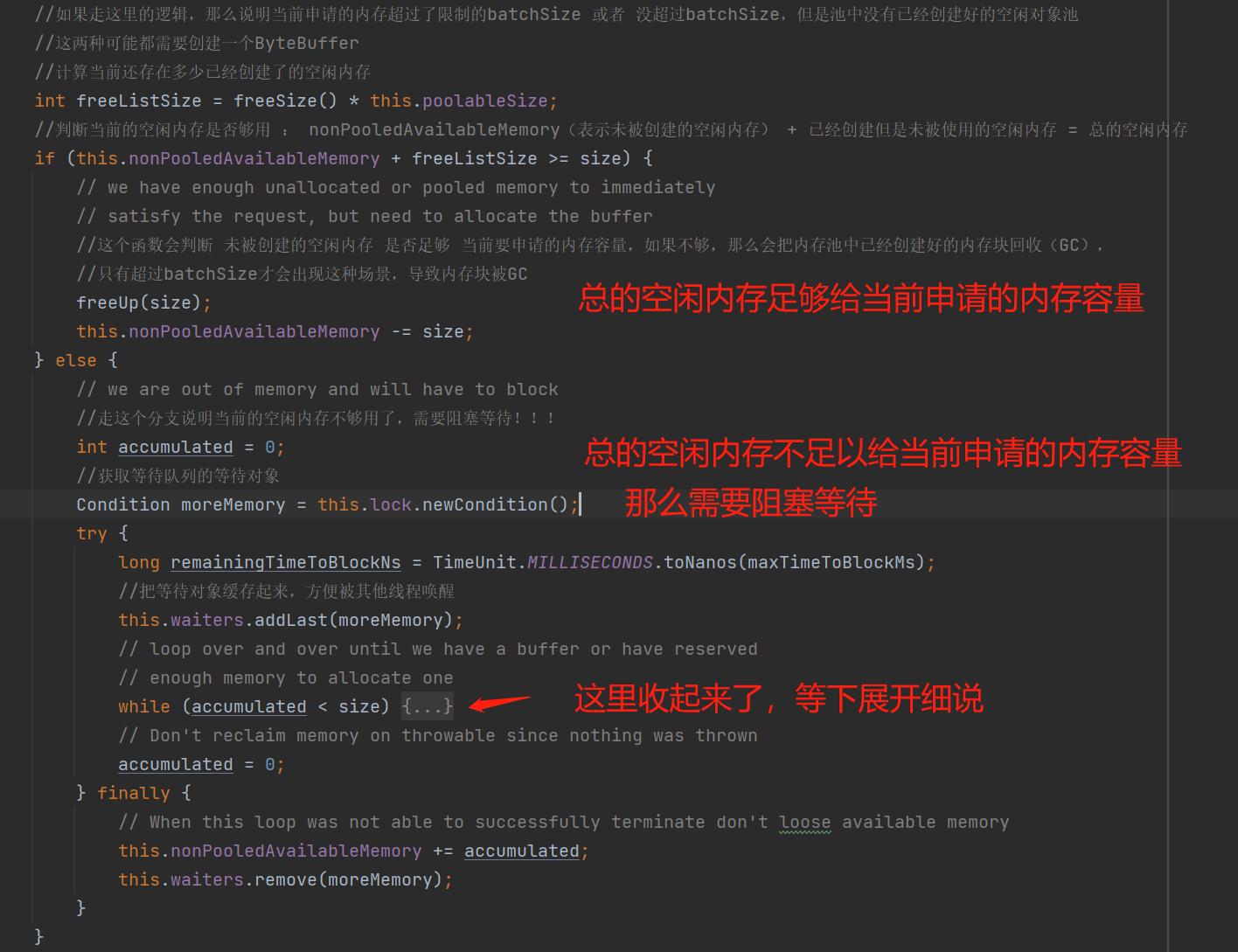
freeUp(): 这个API很好理解,它会判断内存池中如果存在已创建的空闲内存块 并且 未创建的空闲内存不足够给当前申请的内存容量使用,那么需要把内存池中的一些已创建的空闲内存块回收(GC),以达到当前申请的内存容量。说白了就是未创建的空闲内存不够,由于申请内存都是要连续内存,所以需要从内存池中回收已经创建的内存块。

2、空闲内存容量不充足的代码块:this.nonPooledAvailableMemory + freeListSize >= size 为false时,表示当前空闲内存容量不够。
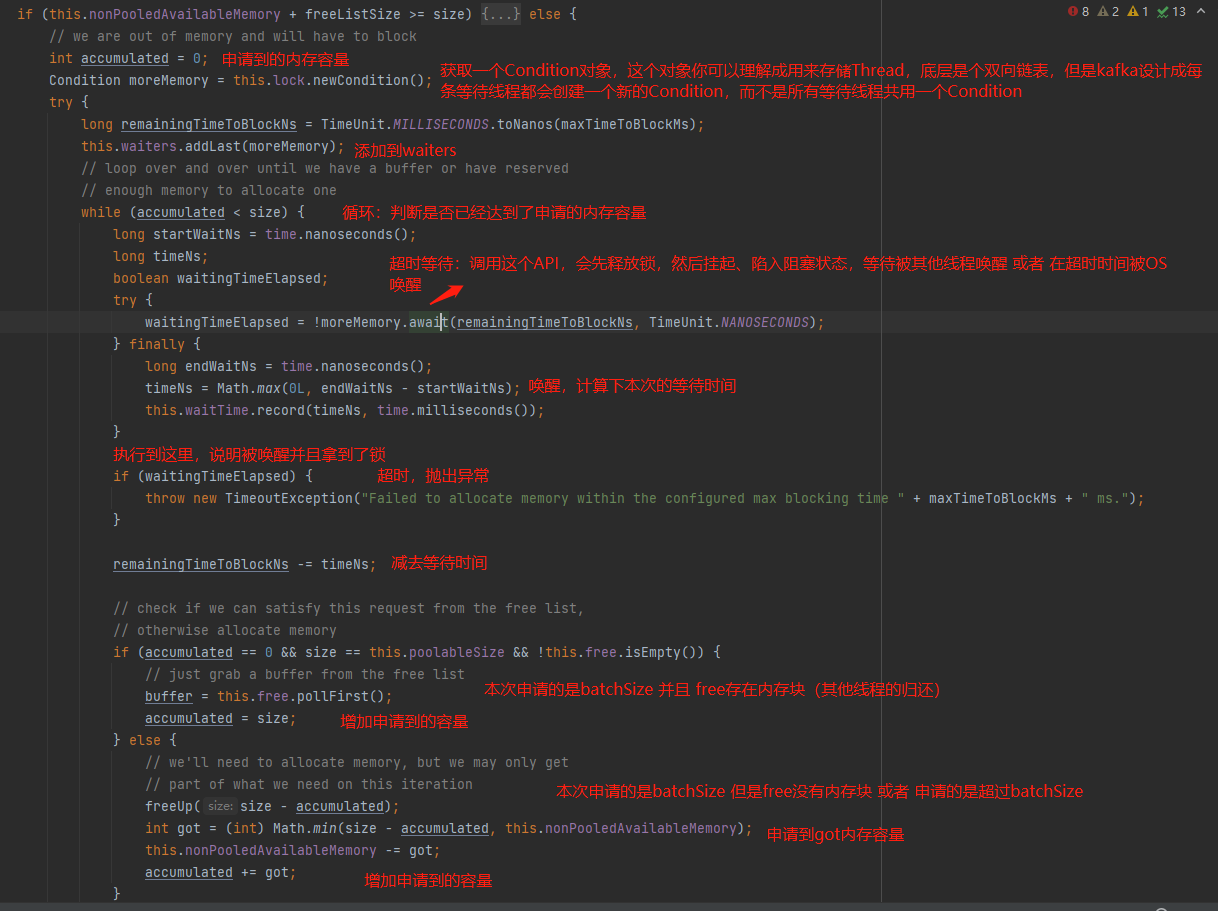
如上图,创建一个Condition,然后调用await(),这个API的作用就是先释放锁,挂起当前线程并进入阻塞状态,等待被其他线程归还内存的时候唤醒或者阻塞时间到了被OS唤醒。当在限定时间内被其他线程唤醒时,会继续竞争内存资源;当在限定的时间被OS唤醒时,会抛出超时异常。
模拟个内存资源不足的场景:假设目前只有16KB的总空闲内存容量,且已经创建存放在free中,此时Thread-1需要申请一个18KB的内存块来使用,发现资源不足,那么会挂起进入阻塞状态,并且入队(waiters):
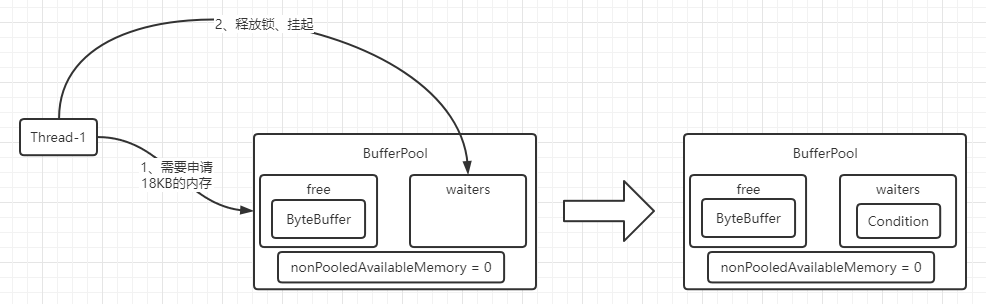
Thread-1阻塞挂起等待其他线程的唤醒,或者超时时间到,被OS唤醒。
假设此时Thread-2归还16KB的内存块,并且发现waiters存在等待的线程,那么会帮忙唤醒一下:
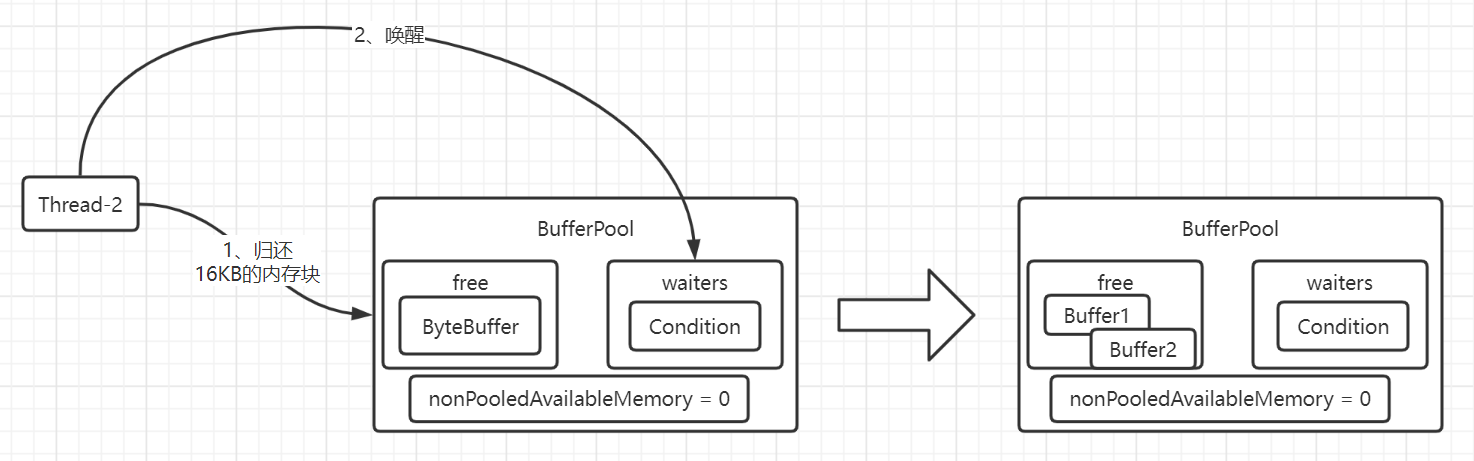
Thread-1被Thread-2唤醒后,首先是尝试竞争锁,竞争到锁才有资格继续拿资源(这一块是AQS相关的知识点),现在假设它是拿到锁的,拿到锁后就开始申请资源,如下图的第1步骤:
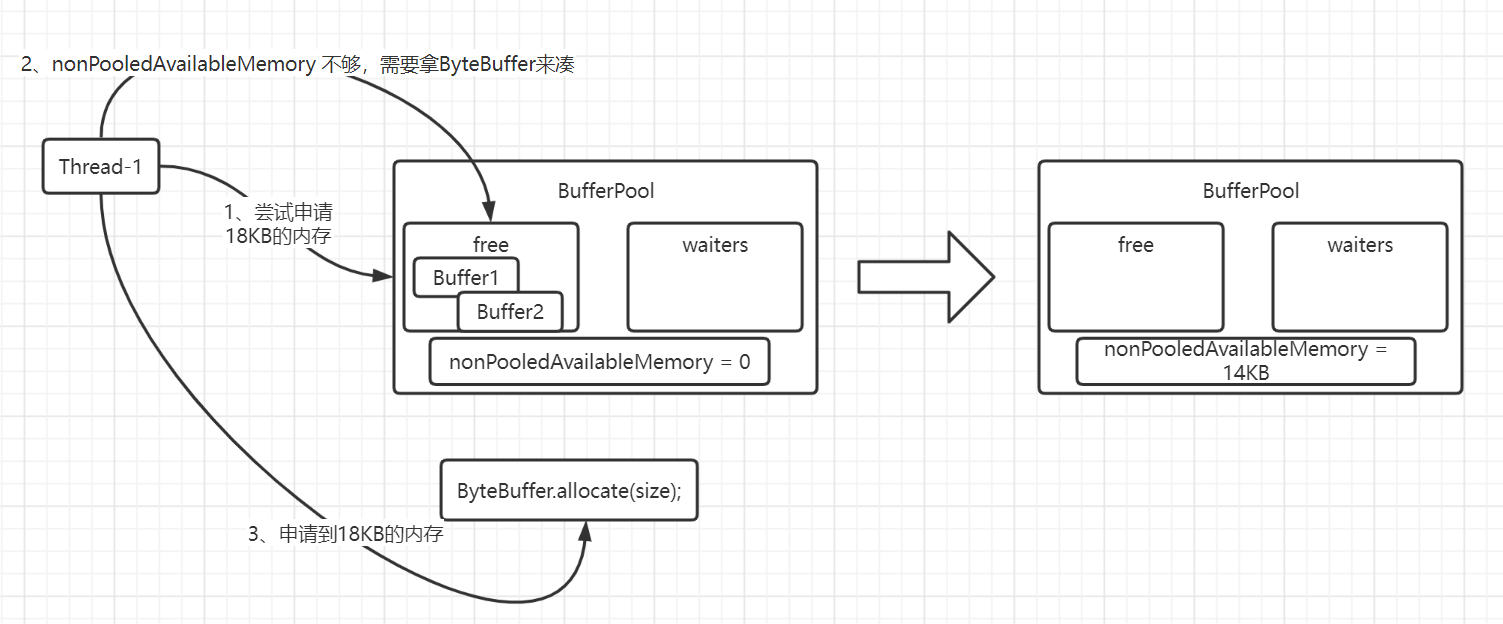
通过这个场景小结一下:内存资源不足时,使用Condition是一种巧妙的设计。
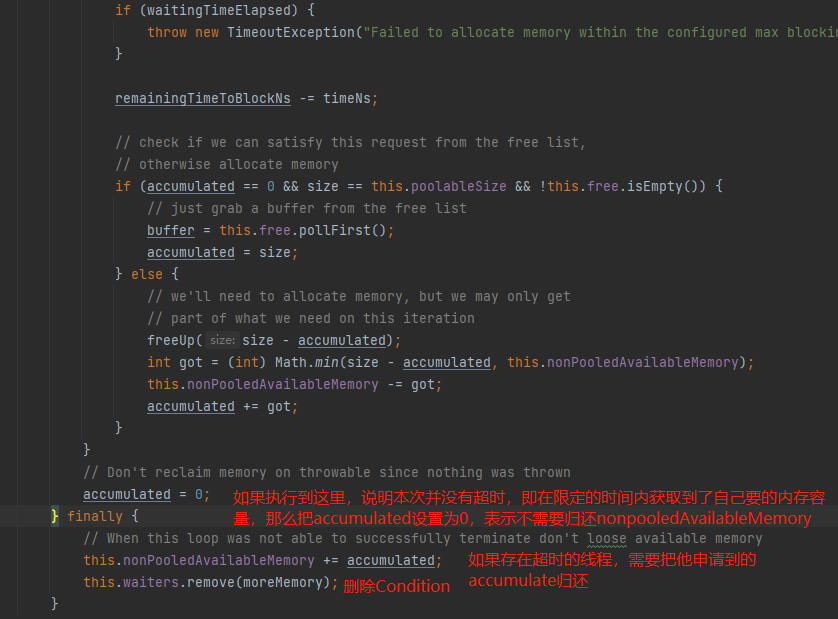
接下来看看 当业务线程退出while循环,线程就会释放锁,在释放锁前它还检查了是否存在空闲资源 并且 存在等待线程,那么会执行唤醒操作,最后向JVM申请内存的操作:
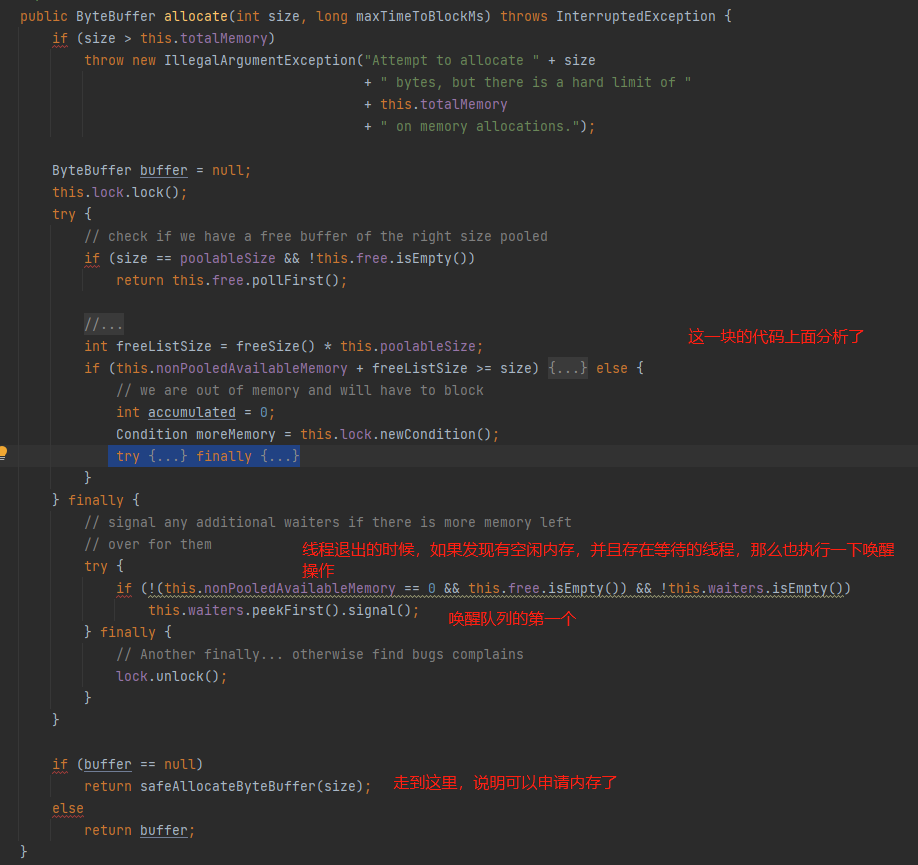
3、执行JVM申请内存操作
如下图:buffer不为空只有一种情况,那么就是阻塞期间刚好有其他线程向free归还内存块,而被唤醒的线程刚好需要一块batchSize大小的内存块,那么从free拿就行了,其他的情况(非超时)都是需要向JVM申请一块内存:

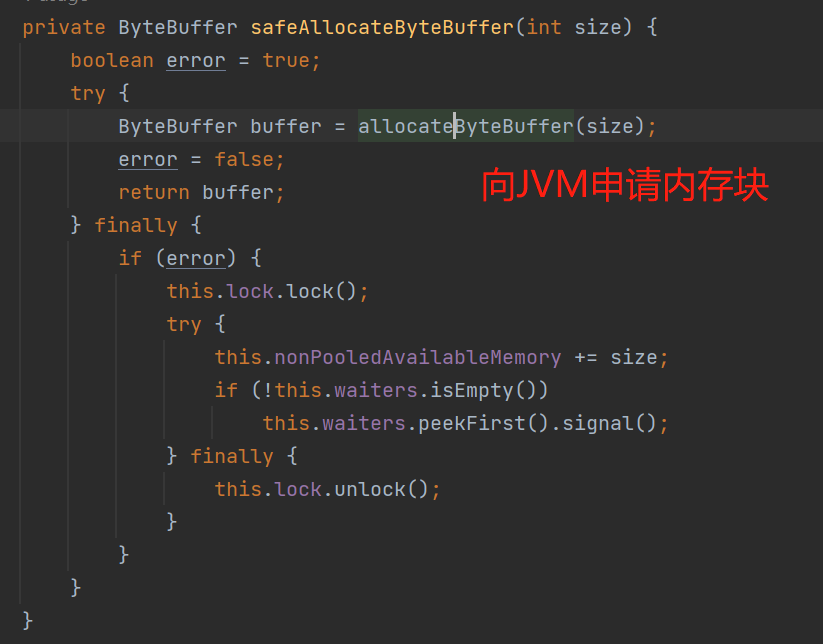

小结一下申请内存的设计亮点:
- 当申请到大于batchSize时,由于不能使用free中的内存块,所以需要向JVM申请一块更大的内存来使用,简单粗暴。
- 当内存资源不足时:
- 采用Condition来挂起阻塞线程,等待有资源时会被唤醒;
- 采用超时机制来避免死锁或者无限等待状态(减少申请大内存块的线程可能会陷入饥饿);
- 每条线程因资源不足时需要进入等待,都会创建一个各自新的Condition,而不是设计成一个Condition来维护所有的阻塞线程,并且采用先进先出的队列来存储这些Condition,一定程度上可以减少申请大内存块的线程陷入饥饿状态的概率。
网络I/O
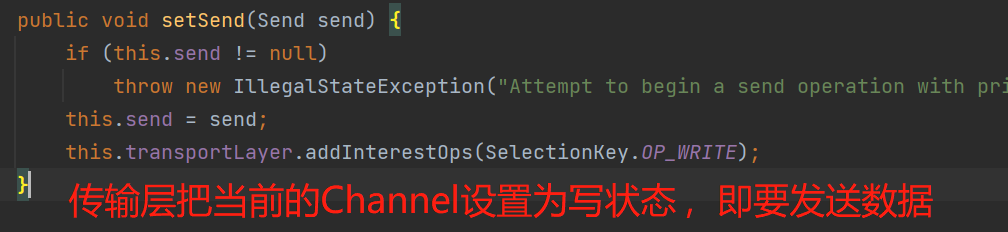
网络通信有一个很重要的概念:通道(Channel),即客户端与服务端成功建立连接后,会通过Channel来实现两端之间的数据传输,而kafka中的KafkaChannel就是所谓的网络通道,如下图KafkaChannel的三个重要属性:
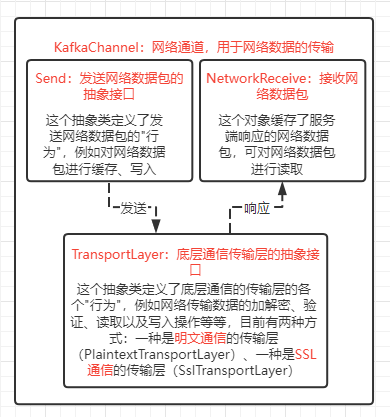
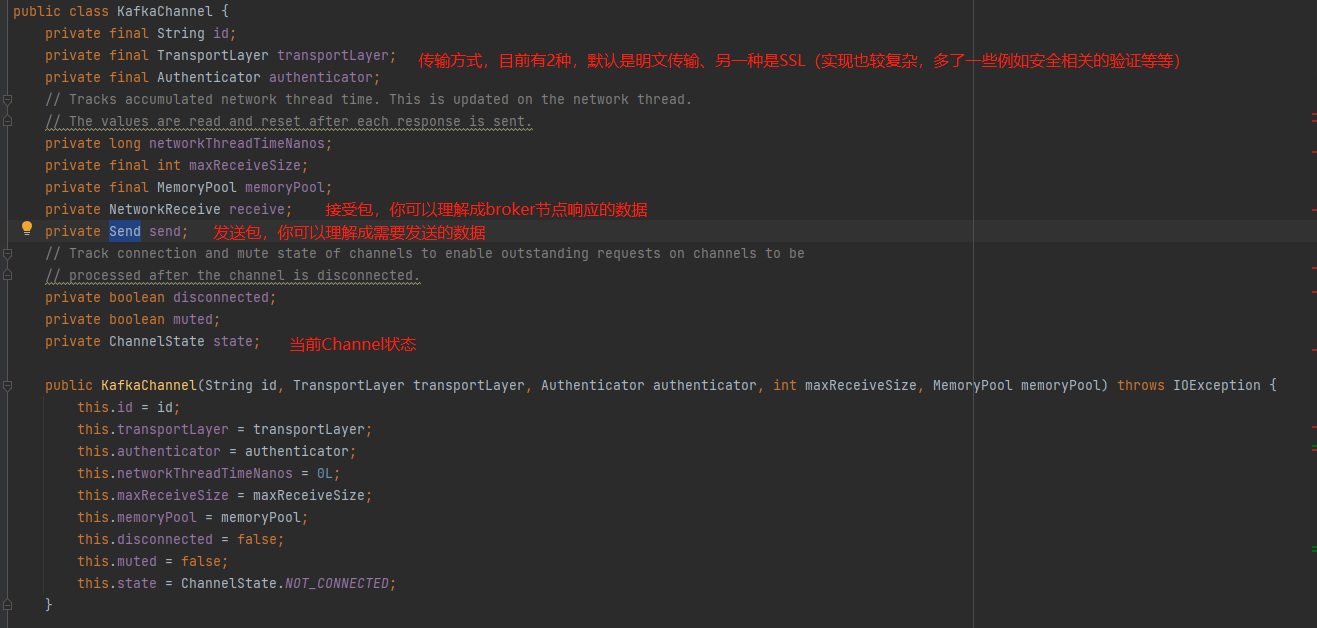
如上图中,每个Channel都使用Send来保留需要发送的数据,NetworkReceive来保留接收到的响应数据,并且传输层TransportLayer来进行数据的传输。
KafkaProducer设计的Channel读写数据都是基于ByteBuffer,从Send的实现类就可以看出(Send是一个抽象接口):每个实现类有不同的写入方式,但是最终都是把数据写入到ByteBuffer。
例如我们的创建一个request请求,实际上需要创建一个NetworkSend,最终是把发送数据写入到ByteBuffer中:
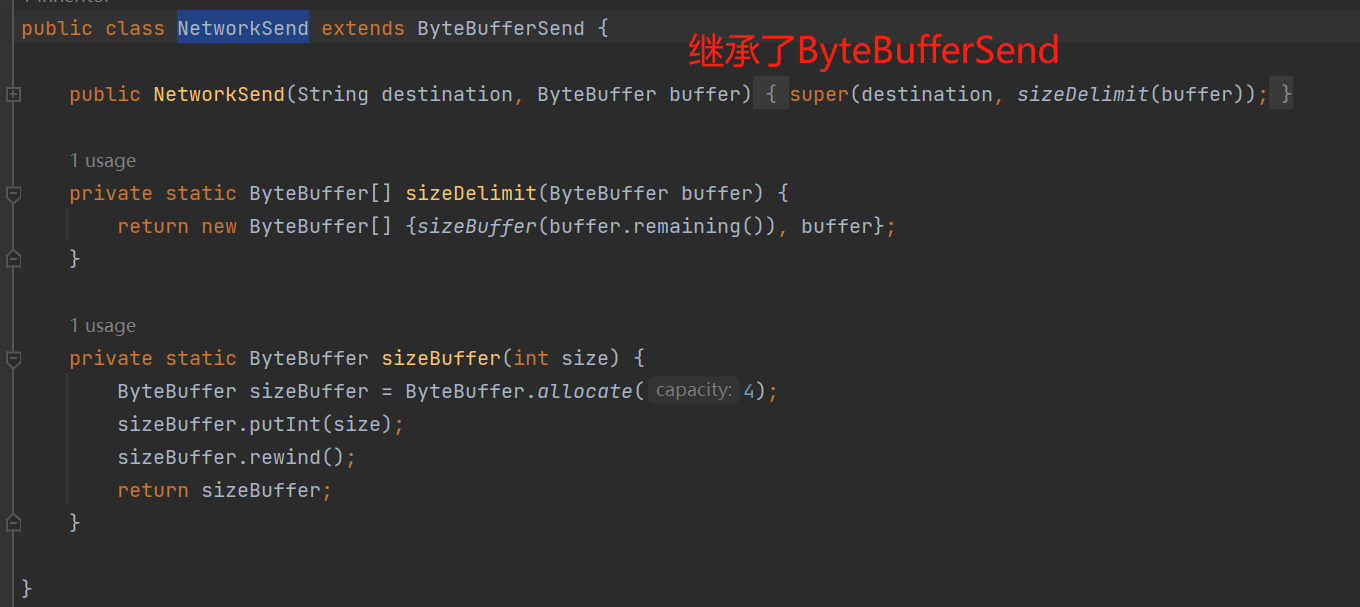
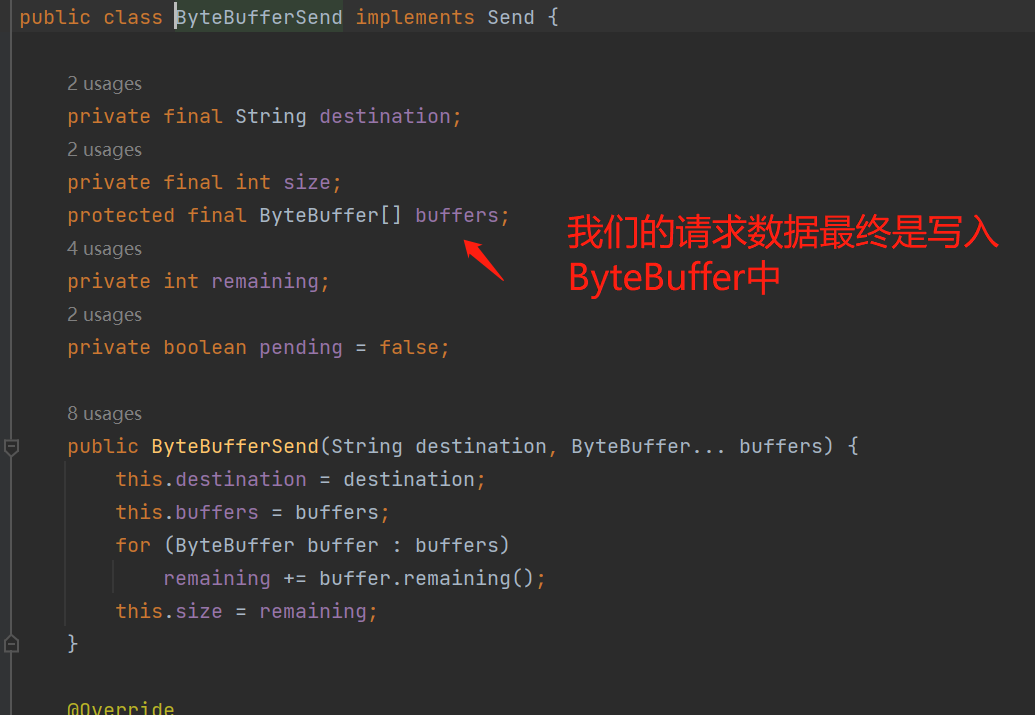
接收到的响应数据也是同样一个道理,写入到NetworkReceive,实际上是写入到ByteBuffer中:
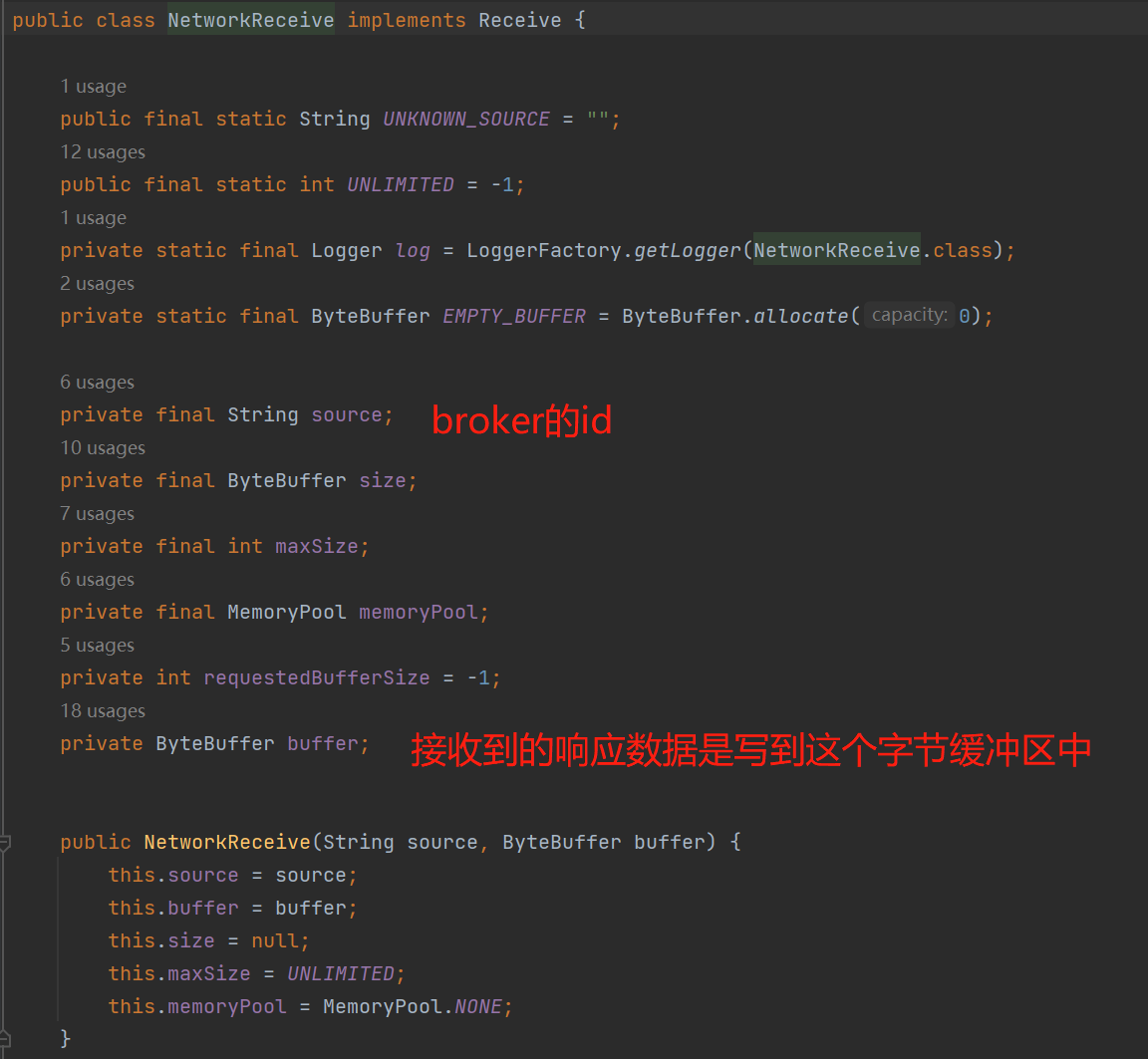
对于Send数据包的发送 或者 响应的数据包写入到NetworkReceive,都是通过传输层TransportLayer来操作:
如上图,目前提供了2种传输方式,一种的明文传输(PlaintextTransportLayer)、一种是SSL传输(SslTransportLayer),PlaintextTransportLayer实现简单,应用于安全性较低的场景,例如内网环境,而SslTransportLayer实现就很复杂了,应用于安全性高的场景,例如把Kafka暴露在外网。
默认是使用明文传输,相关参数是security.protocol,并且目前支持三种方式。如下图:
PS:目前了解到的SASL是用于认证,SSL主要用于对传输的数据进行加密,即一个是认证层,一个是安全传输层,网络安全传输相关知识本篇文章的不去深究了,后期有时间再深入学习一下。
网络I/O的相关设计
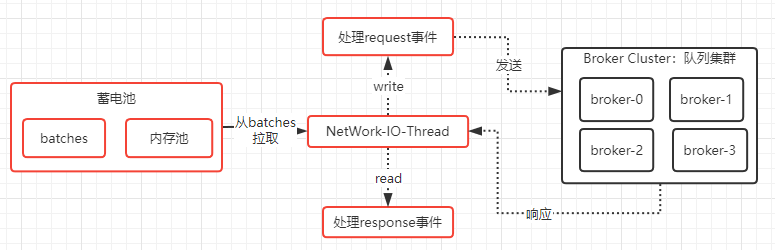
KafkaProducer直接使用Java的原生NIO(Buffer,Channel和Selector)实现的网络I/O,并且网络架构采用的是单线程I/O多路复用,也就是采用一条线程来处理所有的request、response。
回顾上面发送消息的原理,即我们的业务线程发送的消息其实是异步写入到一个蓄电池的batches中,然后就完事了,业务线程并没有把消息发送到broker,而实际上把batches的消息发送到broker是网络I/O线程的工作。如下图的NetWork-IO-Thread:
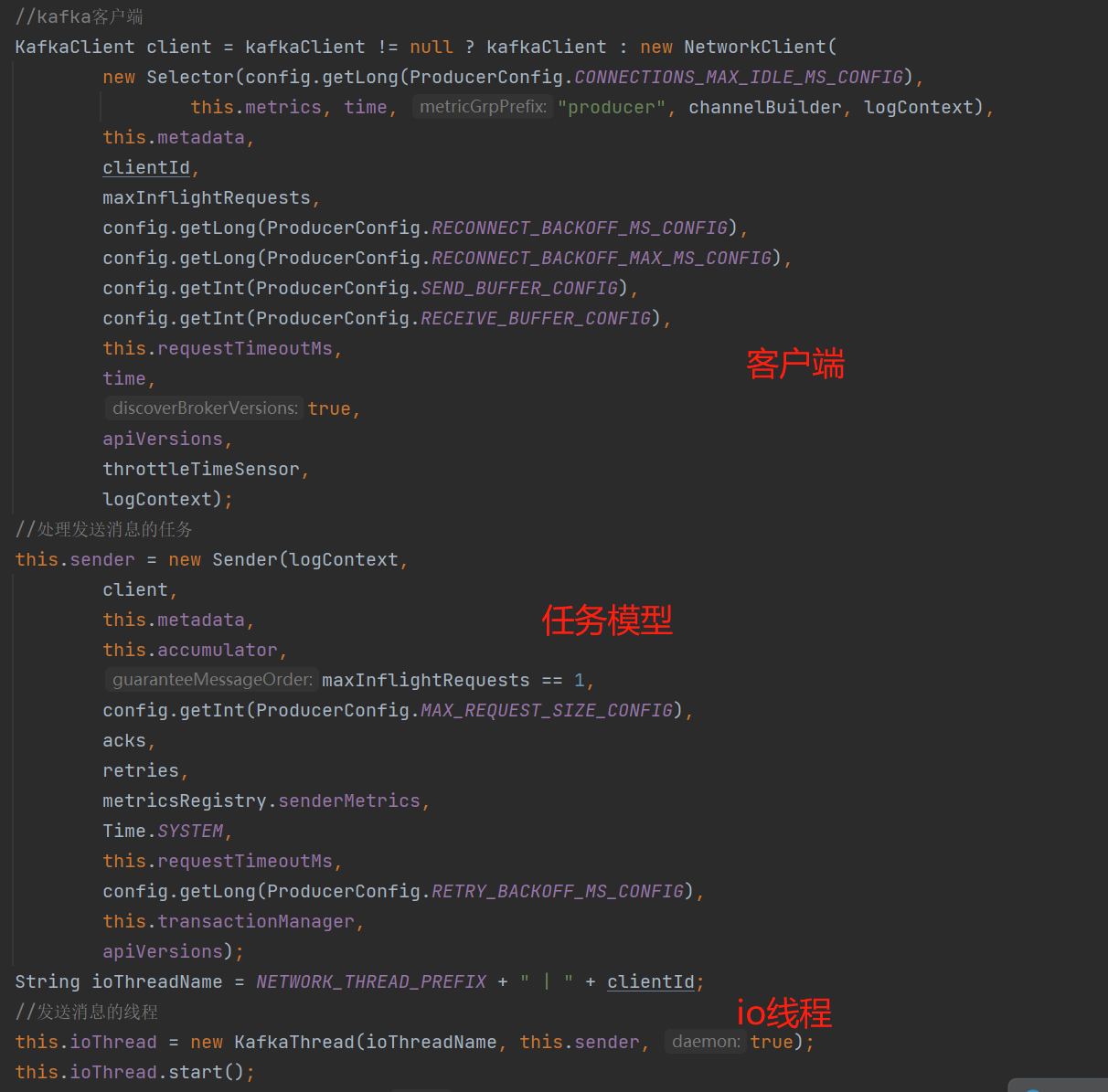
从KafkaProducer构造函数我们可以看到创建了一个KafkaClient客户端对象,用于与broker打交道、还创建了一条KafkaThread的网络I/O线程和这条线程的Sender任务模型。如下图:
这几个对象的组合关系如下图:
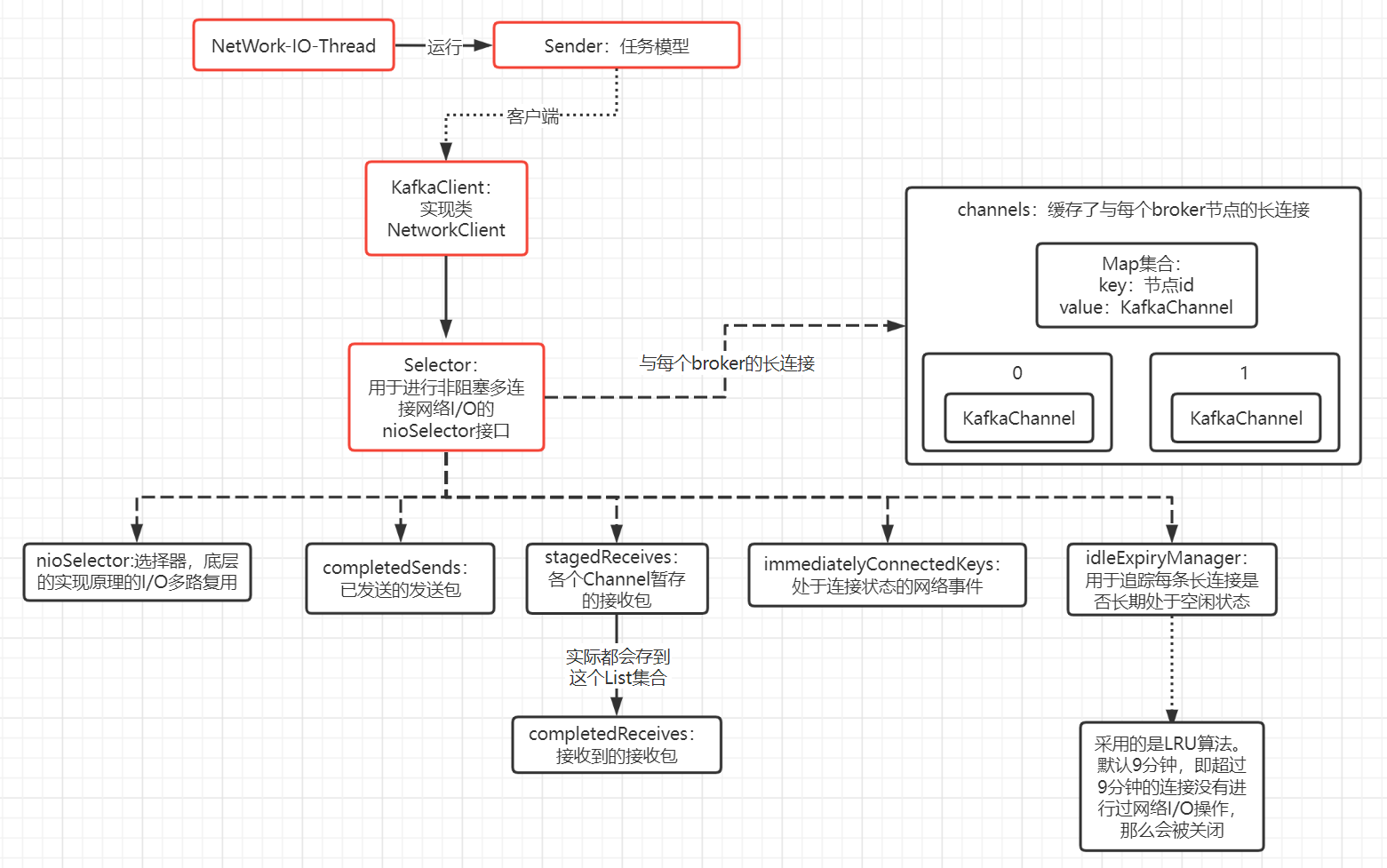
从上图可以知道,IO线程依赖于客户端的Selector完成的一系列的网络I/O操作,所以Selector是最核心的一个类,与网络I/O有着密切的关系。
KafkaClient客户端对象
KafkaClient:客户端对象主要用来与broker的交互,实际上是通过Selector。如下图构造器创建时的代码:
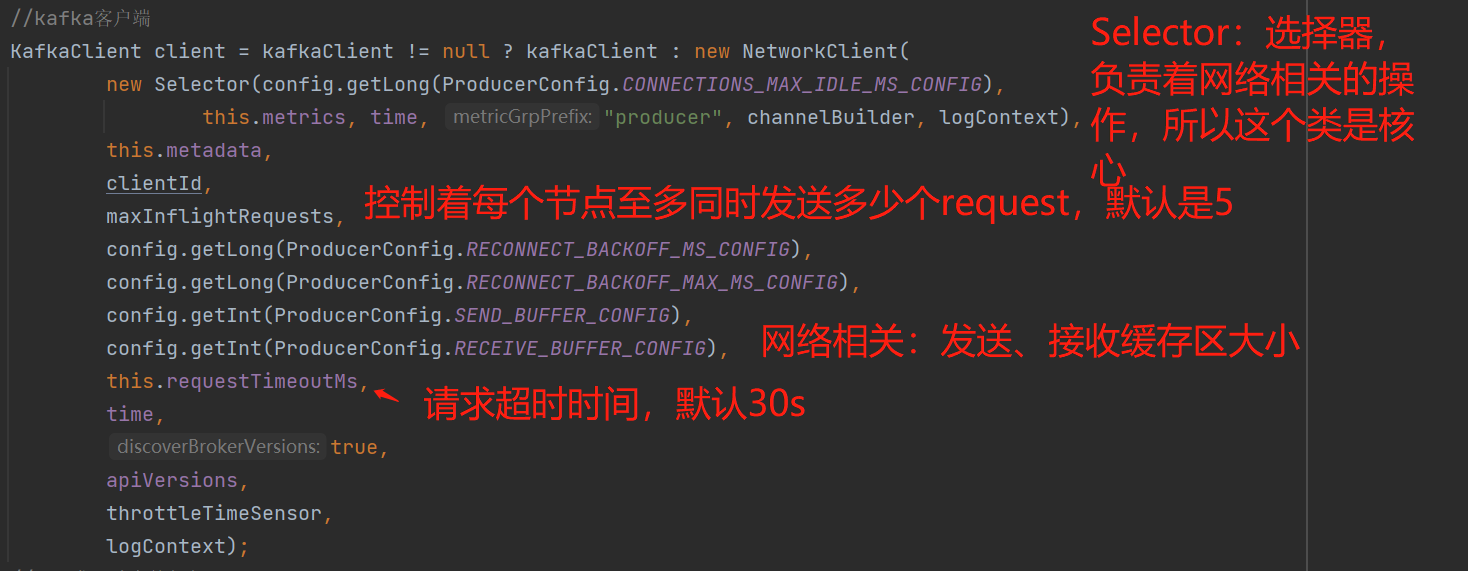
看看构造器的一些属性:
private NetworkClient(MetadataUpdater metadataUpdater,
Metadata metadata,
Selectable selector,
String clientId,
int maxInFlightRequestsPerConnection,
long reconnectBackoffMs,
long reconnectBackoffMax,
int socketSendBuffer,
int socketReceiveBuffer,
int requestTimeoutMs,
Time time,
boolean discoverBrokerVersions,
ApiVersions apiVersions,
Sensor throttleTimeSensor,
LogContext logContext) {
if (metadataUpdater == null) {
if (metadata == null)
throw new IllegalArgumentException("`metadata` must not be null");
//使用默认的更新元数据实现类
this.metadataUpdater = new DefaultMetadataUpdater(metadata);
} else {
//如果kafka提供的更新元数据算法不符合你的场景
//你可以根据自己的场景自定义一个更新元数据的实现类
this.metadataUpdater = metadataUpdater;
}
//选择器,这个类是网络代码的核心,负责着网络相关的代码
this.selector = selector;
this.clientId = clientId;
//缓存了各个broker连接的request数(待发送的request和已发送的request,但还未response)
//默认是每个broker同时支持maxInFlightRequestsPerConnection个request,即5个
this.inFlightRequests = new InFlightRequests(maxInFlightRequestsPerConnection);
this.connectionStates = new ClusterConnectionStates(reconnectBackoffMs, reconnectBackoffMax);
//TCP发送缓冲区的大小
this.socketSendBuffer = socketSendBuffer;
//TCP接收缓冲区的大小
this.socketReceiveBuffer = socketReceiveBuffer;
this.correlation = 0;
this.randOffset = new Random();
this.requestTimeoutMs = requestTimeoutMs;
this.reconnectBackoffMs = reconnectBackoffMs;
this.time = time;
this.discoverBrokerVersions = discoverBrokerVersions;
this.apiVersions = apiVersions;
this.throttleTimeSensor = throttleTimeSensor;
this.log = logContext.logger(NetworkClient.class);
}
重点看看Selector:负责着网络I/O的相关操作,实际上是维护了Selector选择器(这个对象的底层思想是I/O多路复用)、长连接、已发送的数据包、broker响应的数据包、追踪每个Channel的最后操作网络I/O的时间等等,反正网络操作相关的基本都是它负责。
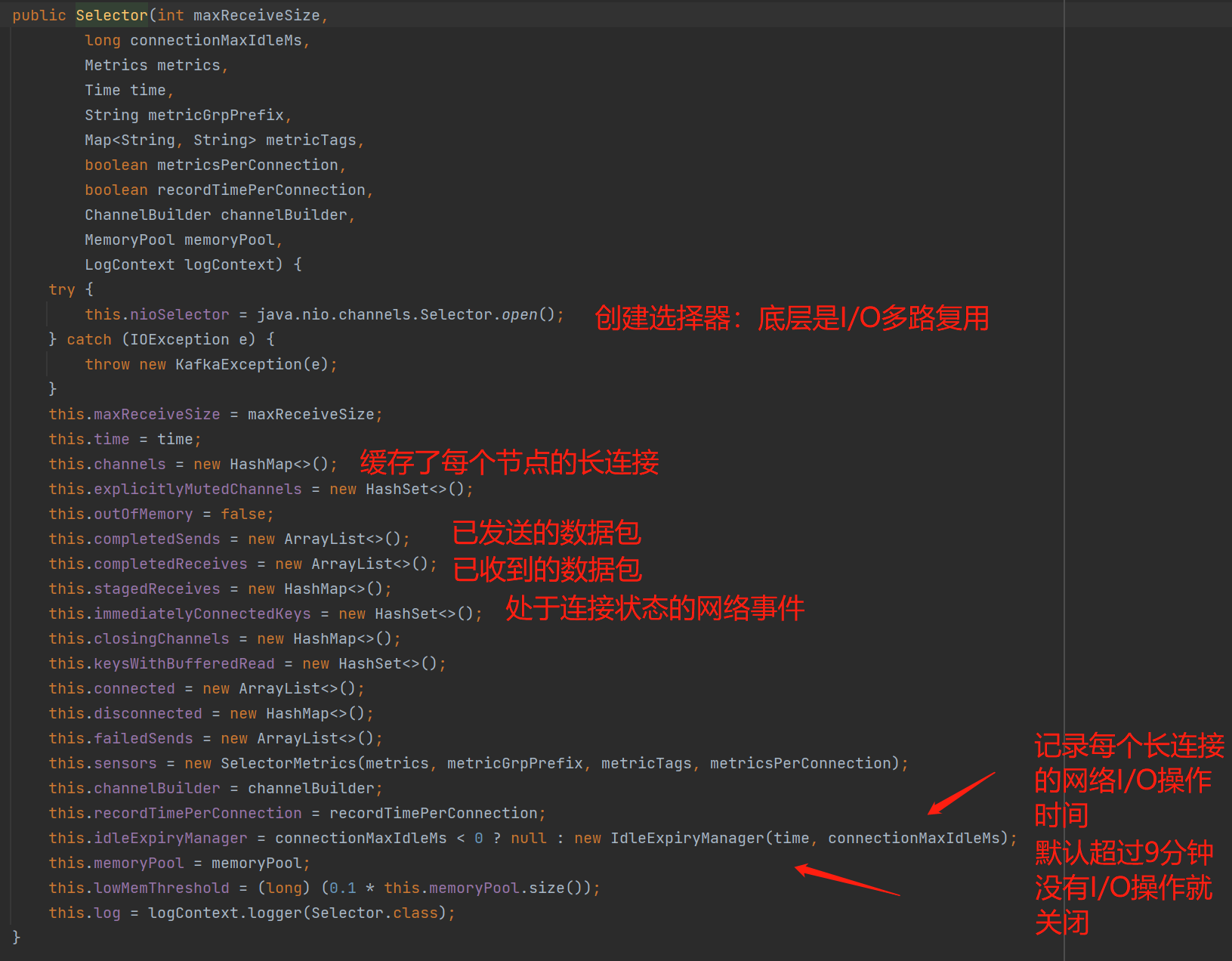
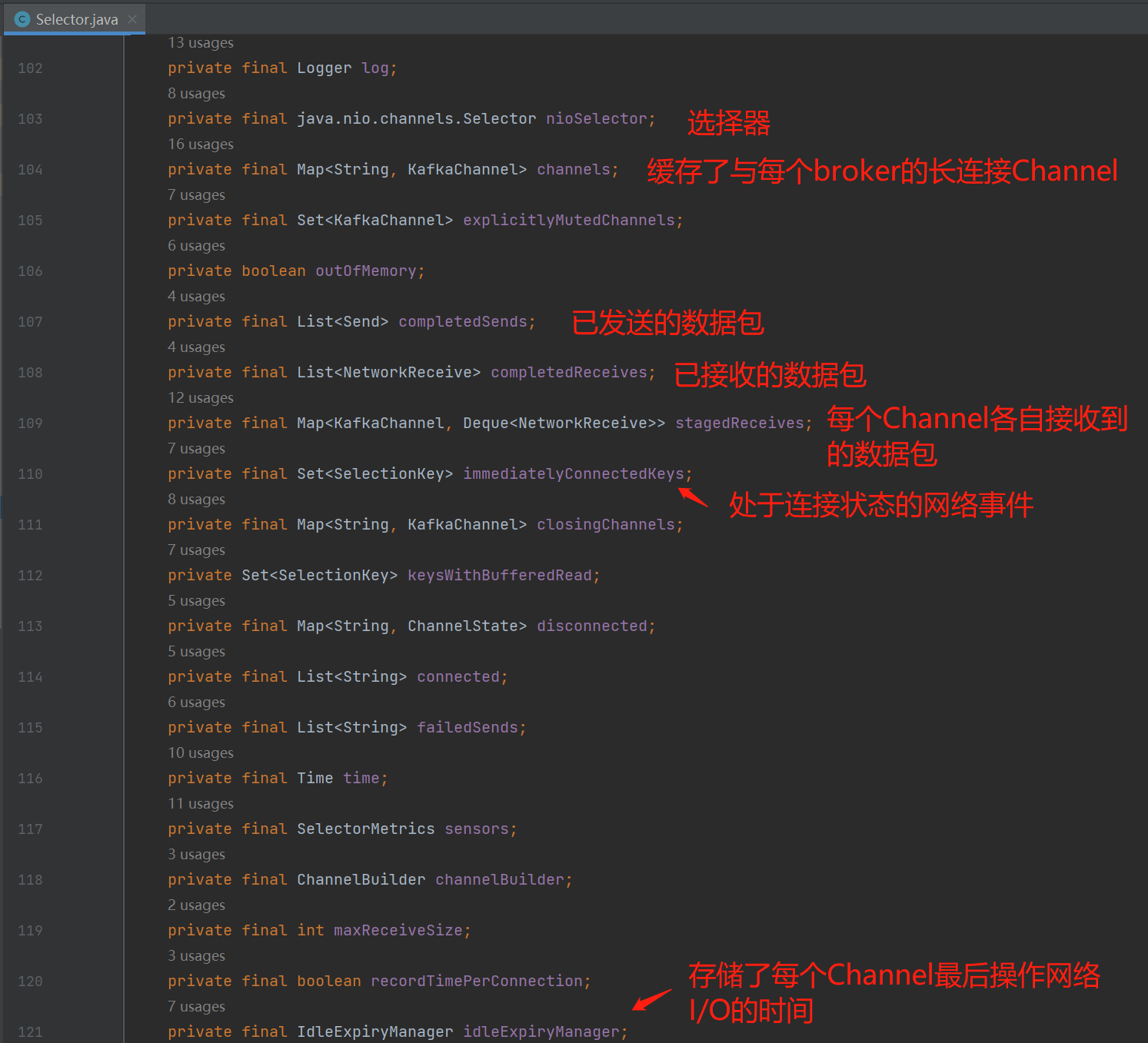
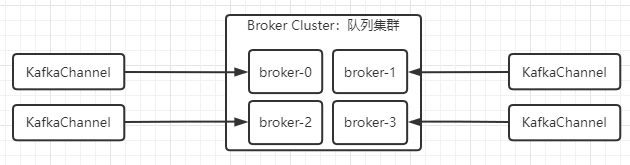
如上图的channels缓存着与每个broker保持的KafkaChannel,KafkaProducer设计的是长连接思想,目的是未了减少频繁的创建、销毁连接带来的性能消耗。而设计的是与集群中每个broker保持一条长连接,如下图,会存在4个KafkaChannel对象 :
KafkaThread网络IO线程
KafkaThread:网络I/O线程,执行的任务模型是Sender,所以核心还是看Sender。如下图构造器创建时的代码:
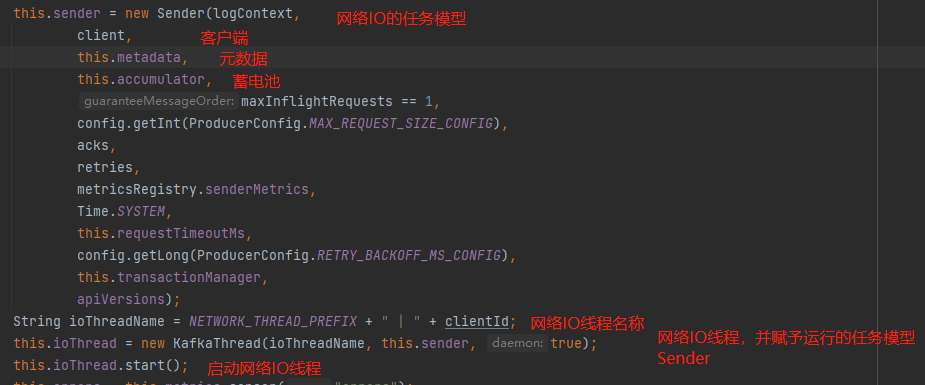
Sender:网络I/O线程运行的任务模型,先看构造器的一些属性:
public Sender(LogContext logContext,
KafkaClient client,
Metadata metadata,
RecordAccumulator accumulator,
boolean guaranteeMessageOrder,
int maxRequestSize,
short acks,
int retries,
SenderMetricsRegistry metricsRegistry,
Time time,
int requestTimeout,
long retryBackoffMs,
TransactionManager transactionManager,
ApiVersions apiVersions) {
this.log = logContext.logger(Sender.class);
//客户端
this.client = client;
//蓄电池
this.accumulator = accumulator;
//元数据
this.metadata = metadata;
//是否保持顺序发送,当控制每个broker只能同时发送一个request时,这个条件会触发
this.guaranteeMessageOrder = guaranteeMessageOrder;
//请求的最大字节,默认1MB
this.maxRequestSize = maxRequestSize;
this.running = true;
//acks,默认1,即broker只成功把消息写入leader副本即可响应
this.acks = acks;
//重试机制,默认不重试,即broker响应失败时,不进行重试
this.retries = retries;
this.time = time;
this.sensors = new SenderMetrics(metricsRegistry);
//请求超时时间,默认30s
this.requestTimeout = requestTimeout;
//重试间隙时间,默认是100ms,避免频繁重试
this.retryBackoffMs = retryBackoffMs;
this.apiVersions = apiVersions;
this.transactionManager = transactionManager;
}
Sender实现了Runneble接口,所以具体还是看看重写的run()函数:

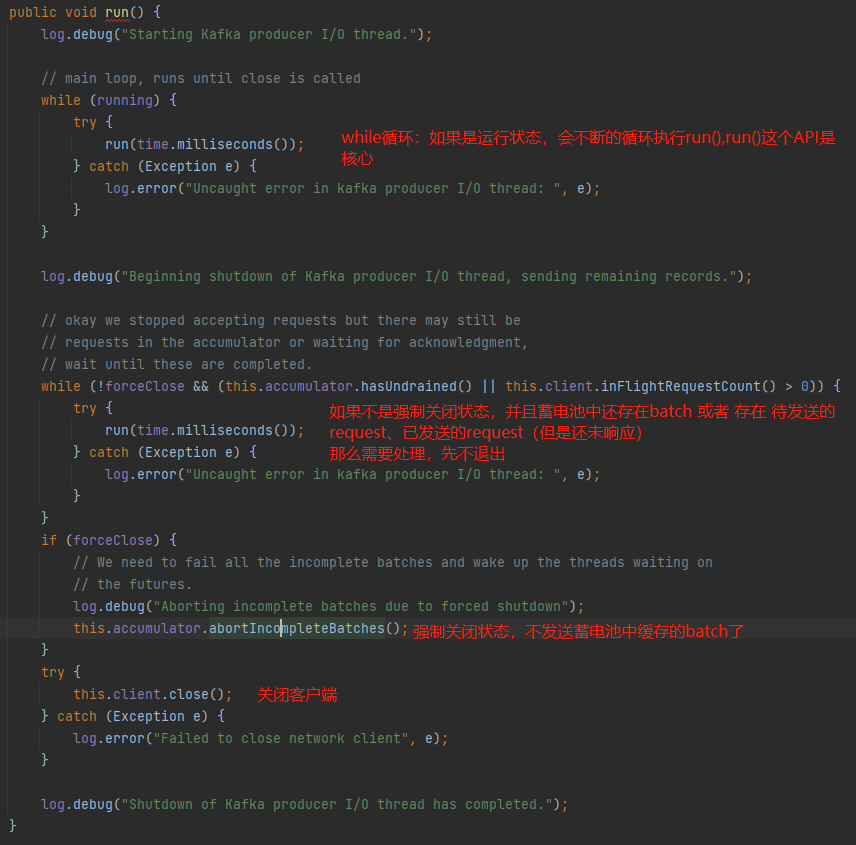
重点还是看run()这个API(又套了一层):
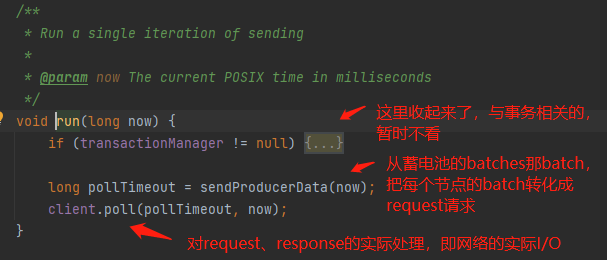
这个API主要做2件事:
- 第1件事:把当前蓄电池中的每个broker的批数据转换成request对象,用于发送请求,如上图的sendProducerData(now);
- 第2件事:处理当前所有的网络I/O读写事件,如上图的client.poll(pollTimeout, now)。
sendProducerData()
这个API会从蓄电池中的batches拉取消息,为每个broker的批数据转换成request请求,具体步骤如下:
- 第1步骤:遍历batches,根据一定的算法检测哪些broker的确需要发送清理ProducerBatch;
- 第2步骤:基于第1步骤检测到需要发送批数据的节点,再检测一下这些节点是否已经准备好发送;
- 第3步骤:基于第2步骤再次检测后确认的节点,从batches遍历收集这些节点的批数据;
- 第4步骤:清理掉蓄电池batches一些过期ProducerBatch,这里的清理掉是指直接清理,并不会发送到broker,所以这也是消息丢失场景该注意的地方;
- 第5步骤:基于第3步骤获取到每个节点的批数据,给每个节点创建request请求对象。
第1步骤:遍历batches,根据一定的算法检测哪些broker的确需要发送清理ProducerBatch:

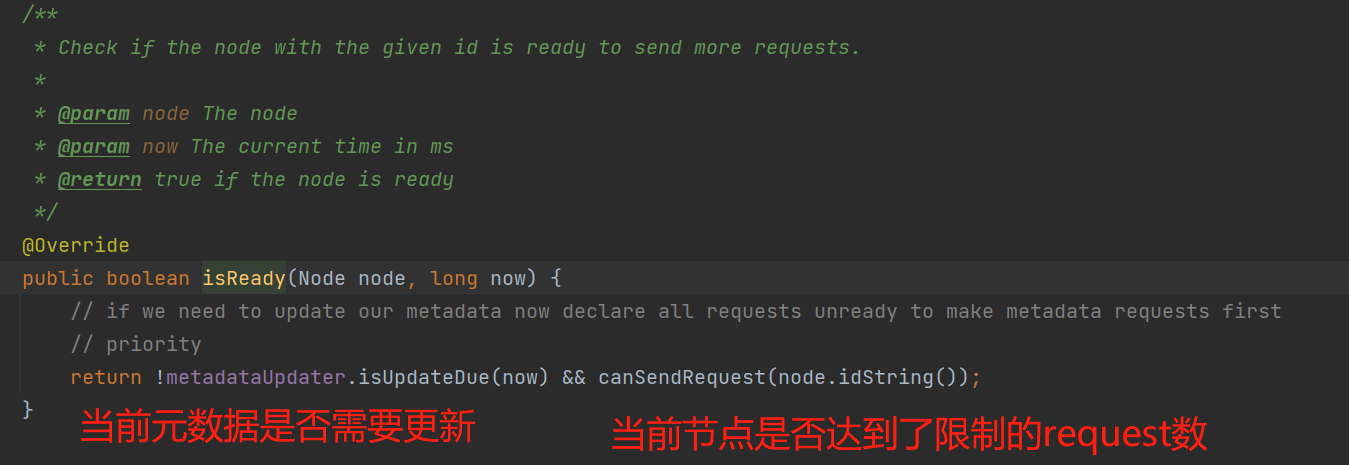
ready()具体看看下图:
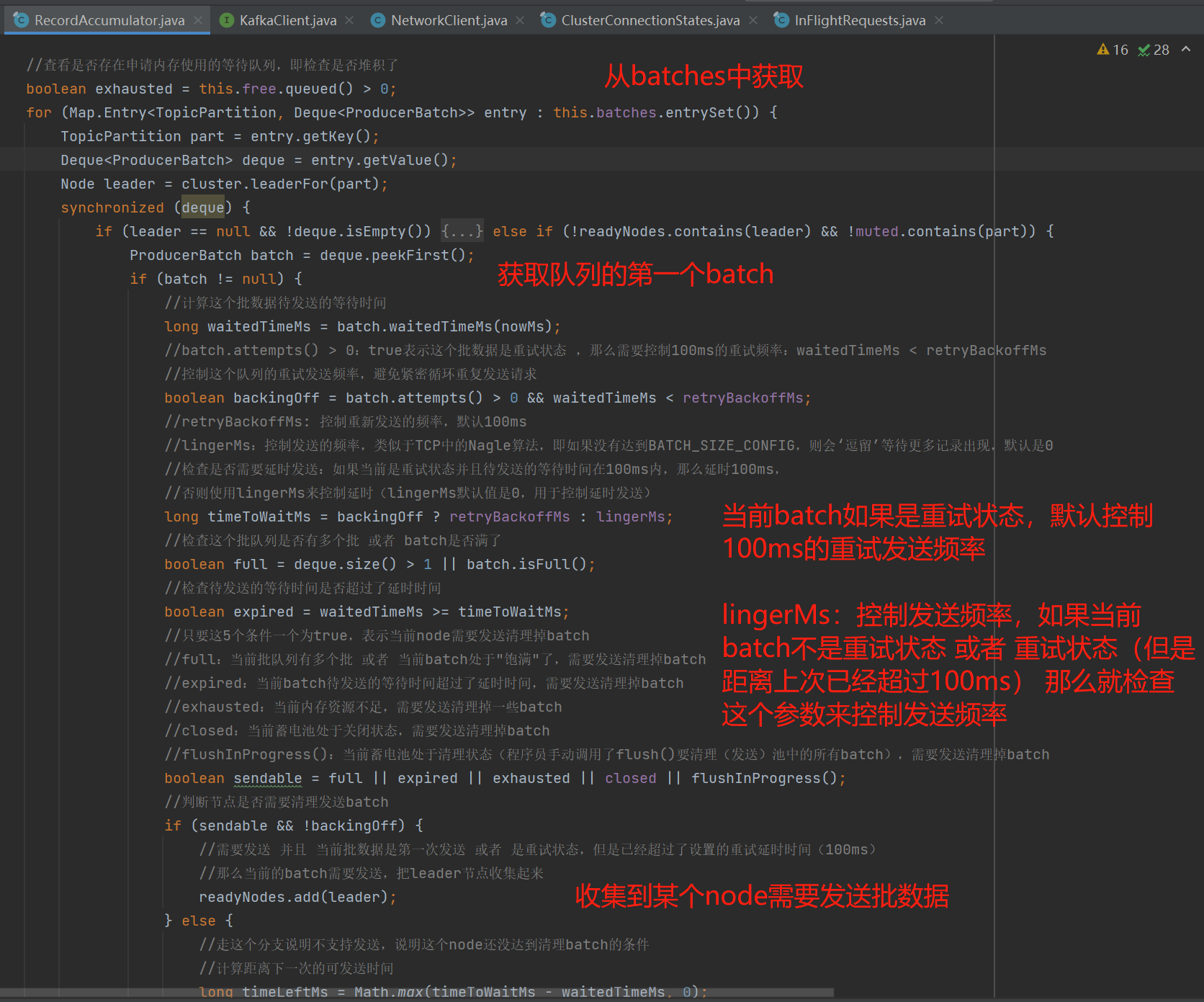
如上图ready()这个API会根据检测算法收集到哪些节点存在批数据需要发送:
- 获取批队列的第一个ProducerBatch(最早的那一个),根据这个批来判断是否确实需要发送批数据;
- 检测算法涉及几个判断元素,并且存在2个核心配置参数:
- retryBackoffMs(控制重试的发送频率,默认是100ms,对应的参数是retry.backoff.ms)、lingerMs(控制发送频率,默认是0ms,即不控制,对应的参数是linger.ms)
- 当前批处于重试状态,会控制批数据待发送的等待时间超过100ms再发送;
- 当前批处于重试状态 且 批数据待发送的等待时间超过100ms,那么会判断lingerMs来控制发送频率;
- 当前批处于非重试状态(第一次发送),那么会判断lingerMs来控制发送频率。
- 当前分区的批数据在2个以上,或者 只有1个(满了),那么需要发送批数据;
- 当前内存池中存在等待队列(内存资源不足),那么需要发送批数据;
- 当前蓄电池处于关闭状态,那么需要发送批数据;
- flushInProgress():当前蓄电池处于清理状态(程序员手动调用了flush()要清理(发送)池中的所有批数据),那么需要发送批数据;
- 以上5个条件只要一个为true,表示当前broker需要发送清理掉batch,并且在重试状态的情况下还是会控制下重试发送的频率。
- 本次收集到哪些broker是需要发送批数据。
第2步骤:基于第1步骤检测到需要发送批数据的节点,再检测一下这些节点是否已经准备好。如下图:
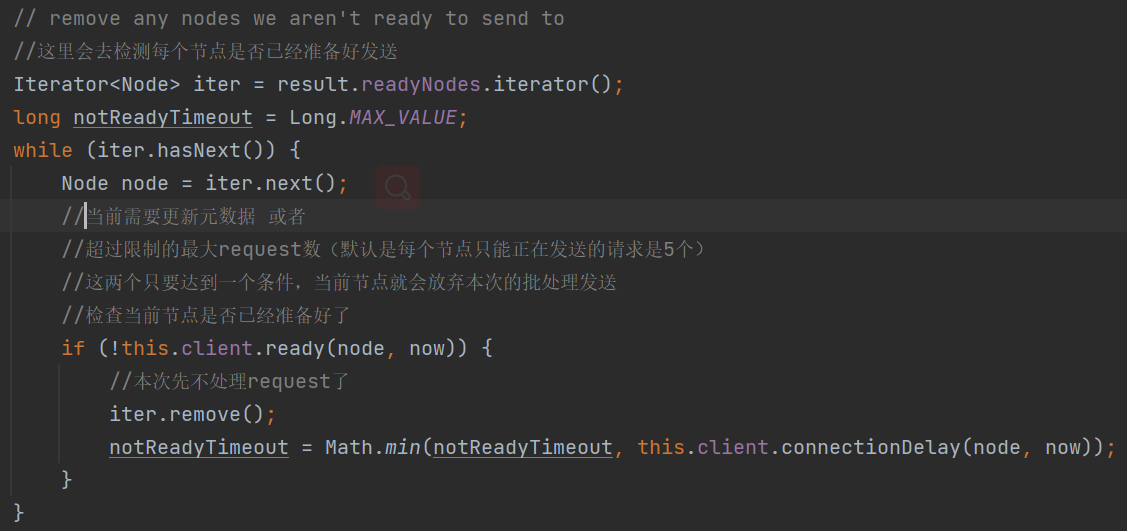
如何检测节点是否已经准备好,如下图:
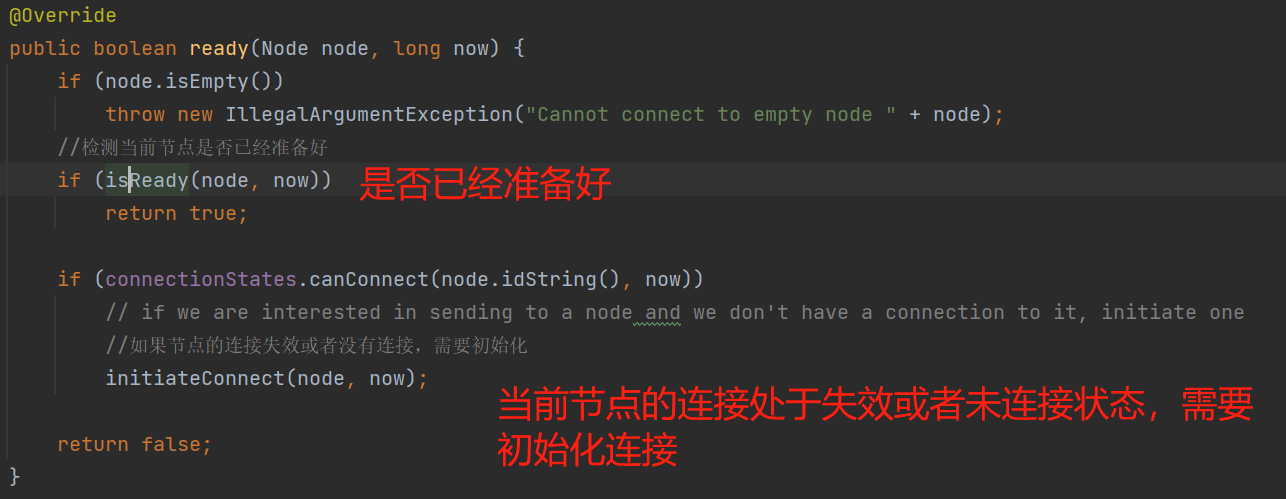
2个条件来判断:
1、检测到当前处于请求更新元数据状态 或者 需要更新元数据,那么本轮节点先不进行批数据发送了:

2、当前暂时无需更新元数据,那么判断当前节点是否达到了限制的request数:

第3步骤:基于第2步骤再次检测后确认的节点,从batches遍历收集这些节点的批数据。如下图:

具体逻辑如下图:收集每个节点的每个分区的批数据。
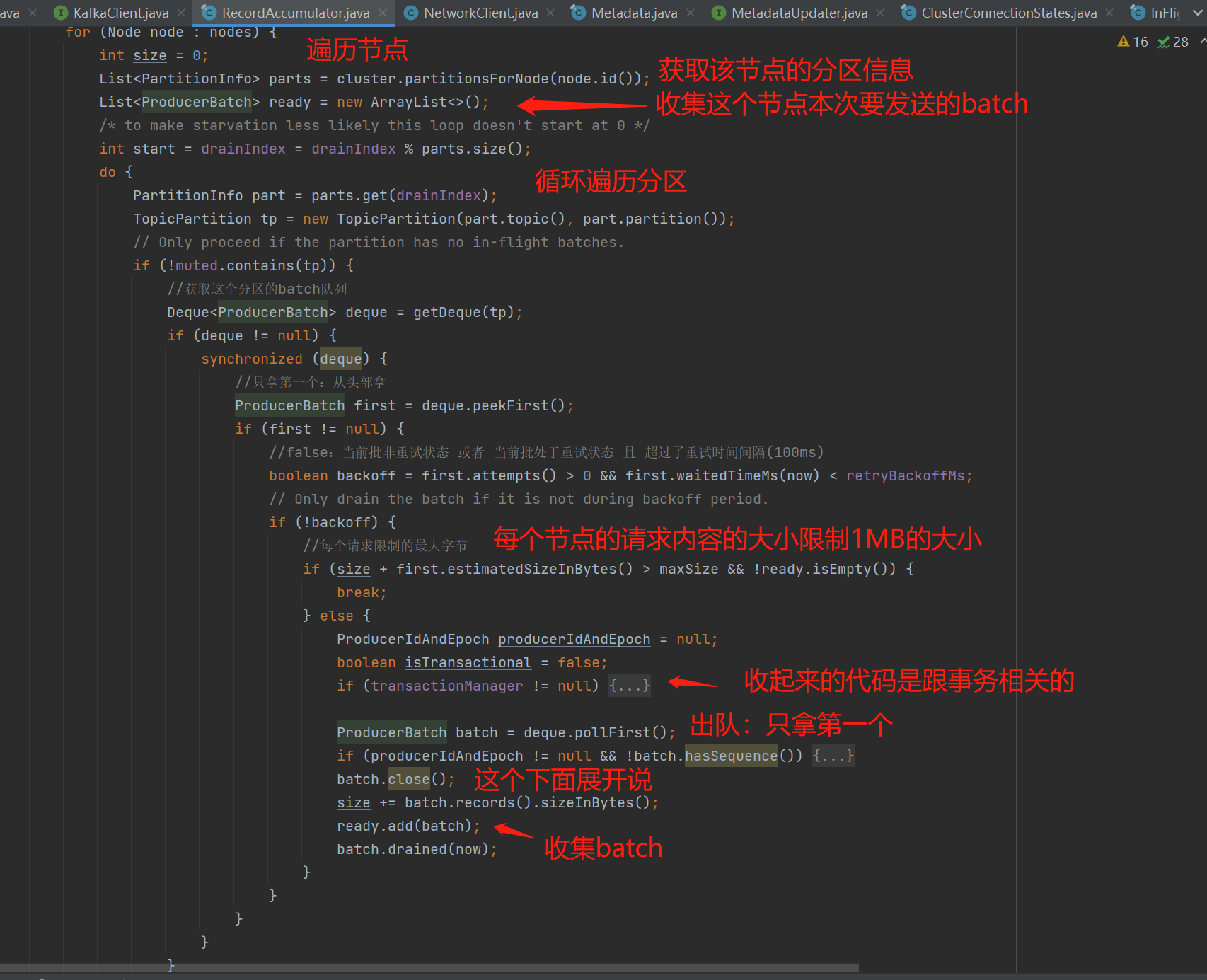
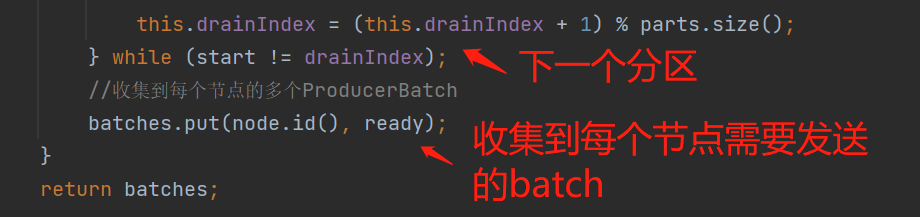
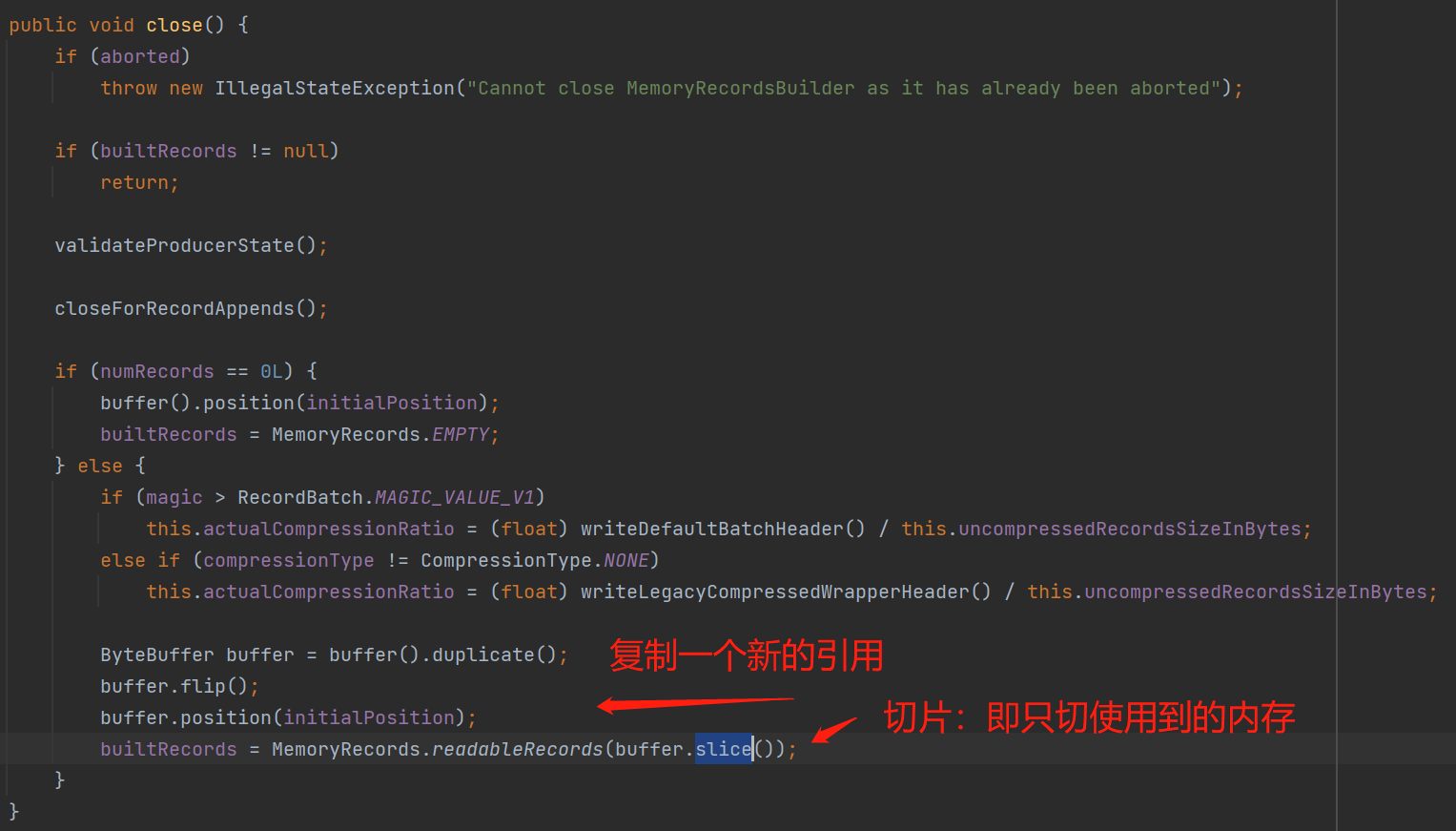
调用close(),会把当前批设置为关闭状态,即禁止写入了,并且进行内存切片,即只切16KB中只用到的那一部分内存:
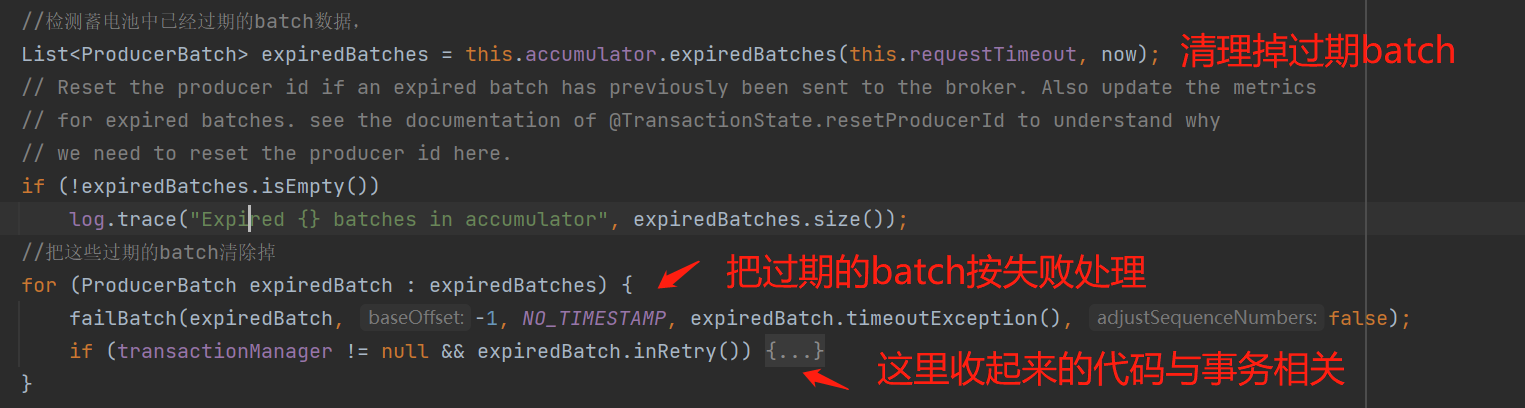
第4步骤:清理掉蓄电池batches一些过期ProducerBatch,这里的清理掉是指直接清理,并不会发送到broker,所以这也是消息丢失场景该注意的地方。如下图:
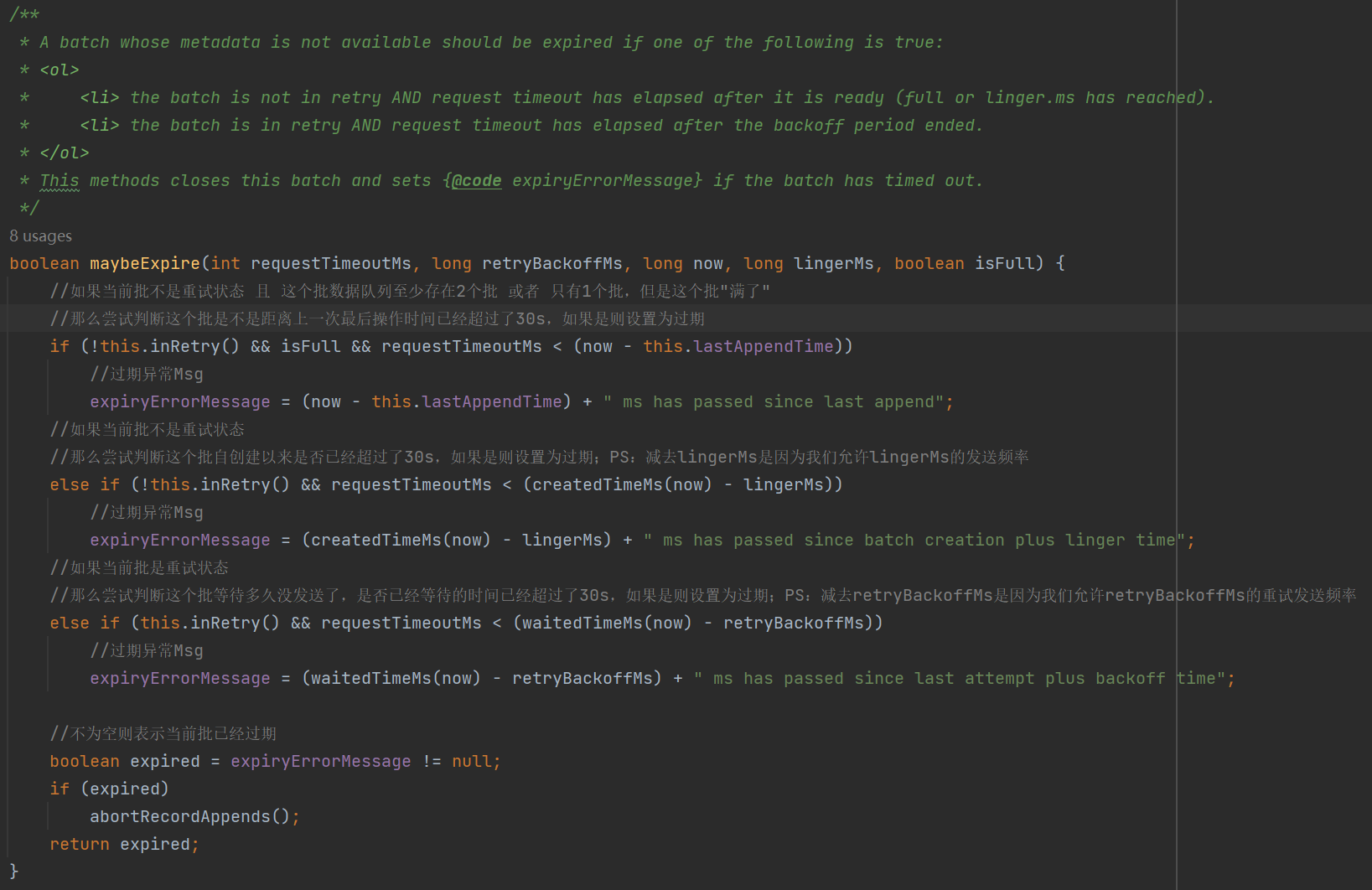
具体看看expiredBatches():
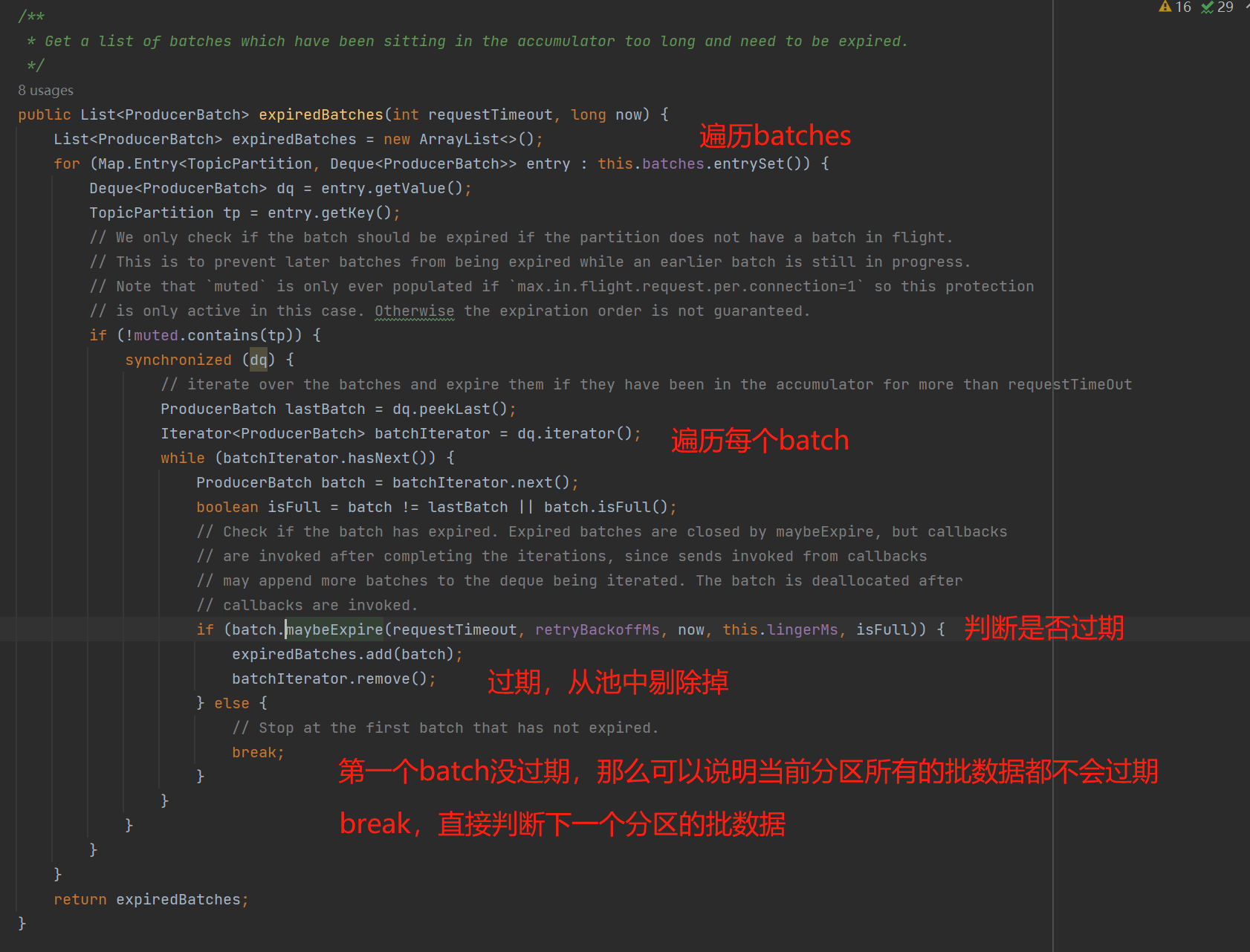
通过maybeExpire()判断当前批是否已经过期,如下图中,可以看到3种情况的判断,池中的batch允许默认是30s的存活时间,超过30s的就会被剔除。
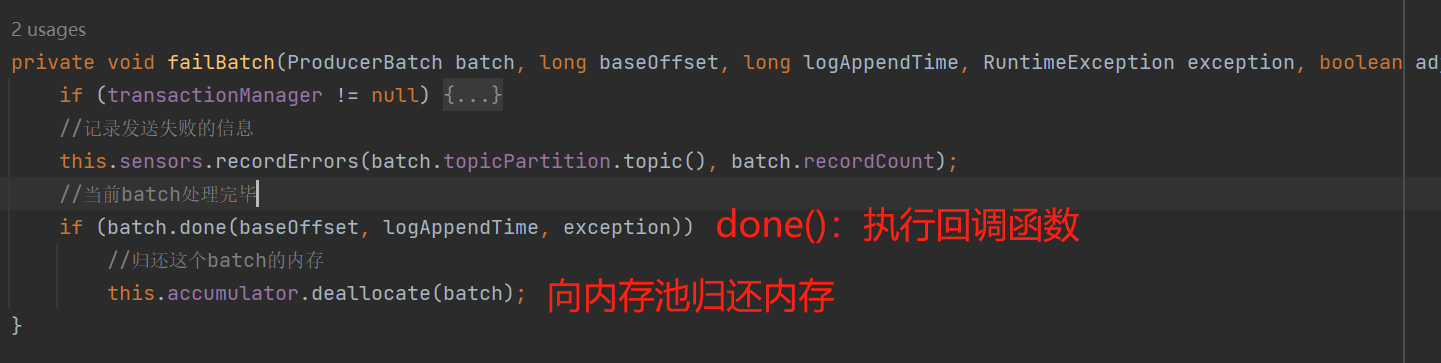
过期的batch会执行失败的回调:
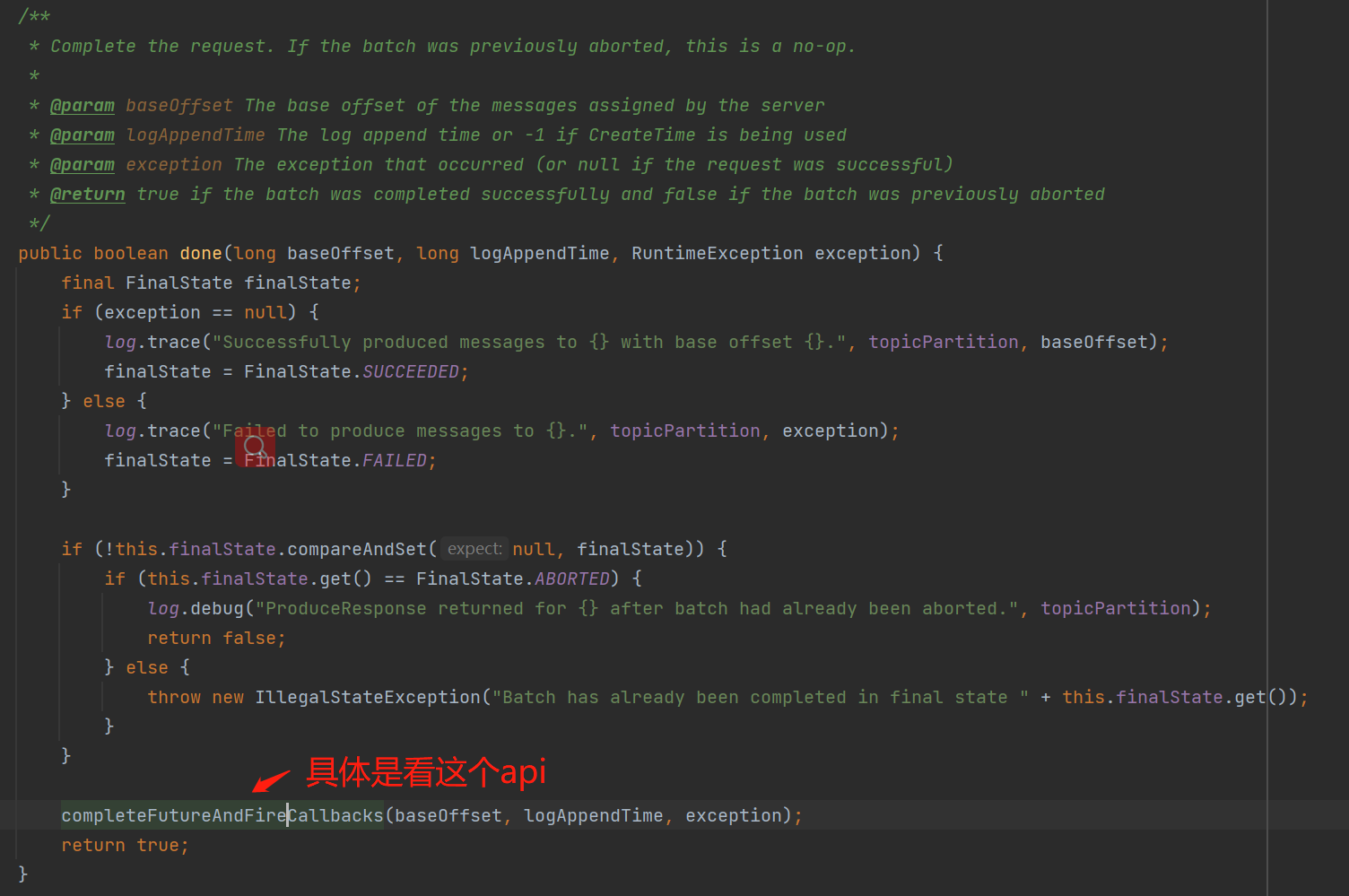
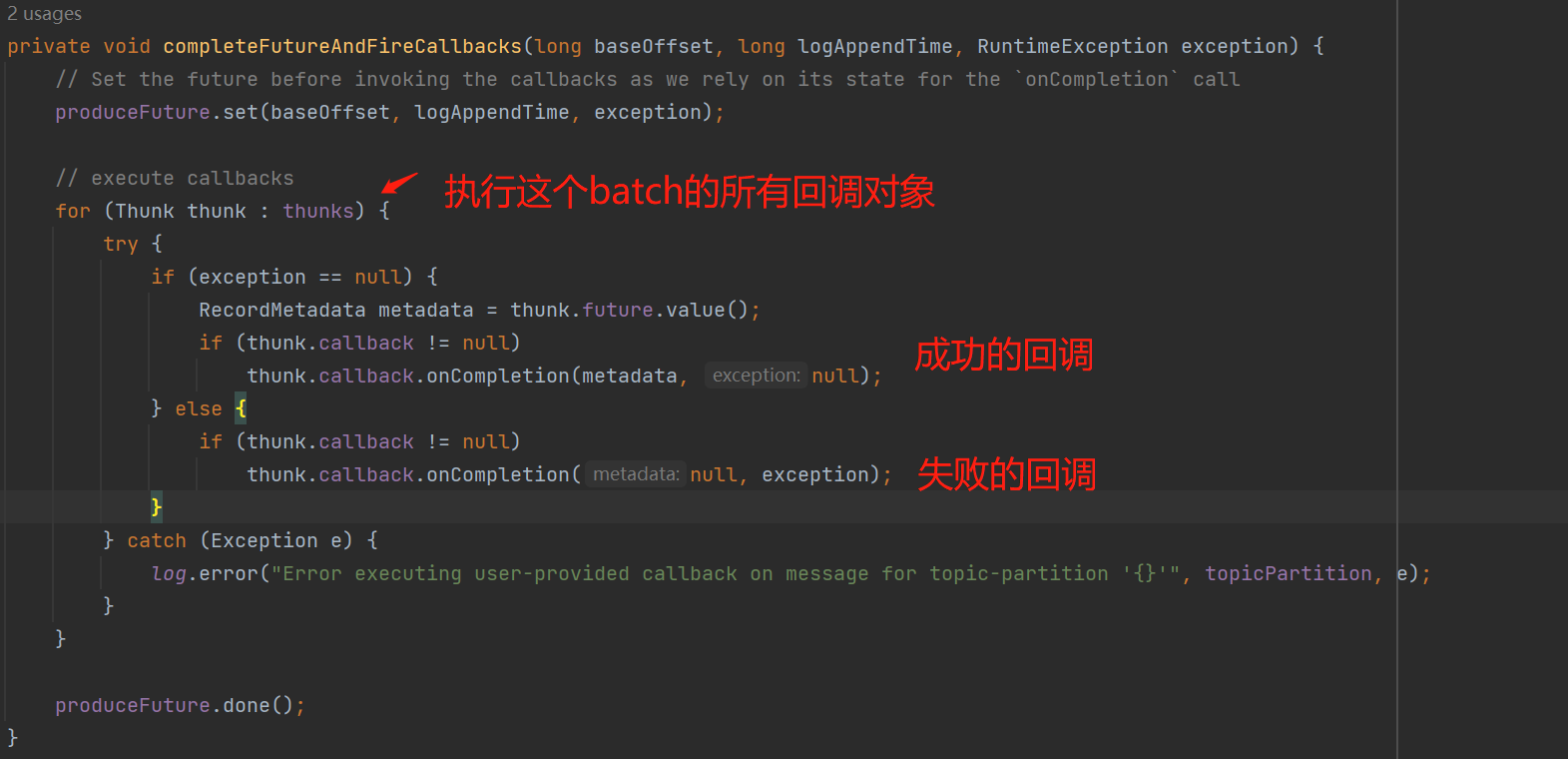
第5步骤:基于第3步骤获取到每个节点的批数据,给每个节点创建request请求对象。

为每个broker创建一个ProduceRequest对象:下图创建ProduceRequest的acks是个核心参数,默认是1,表示把消息写入leader副本即可响应,如果是all,那么表示这个节点的集群副本都要写入成功才响应;produceRecordsByPartition是本次发送到broker的各个分区的批数据。
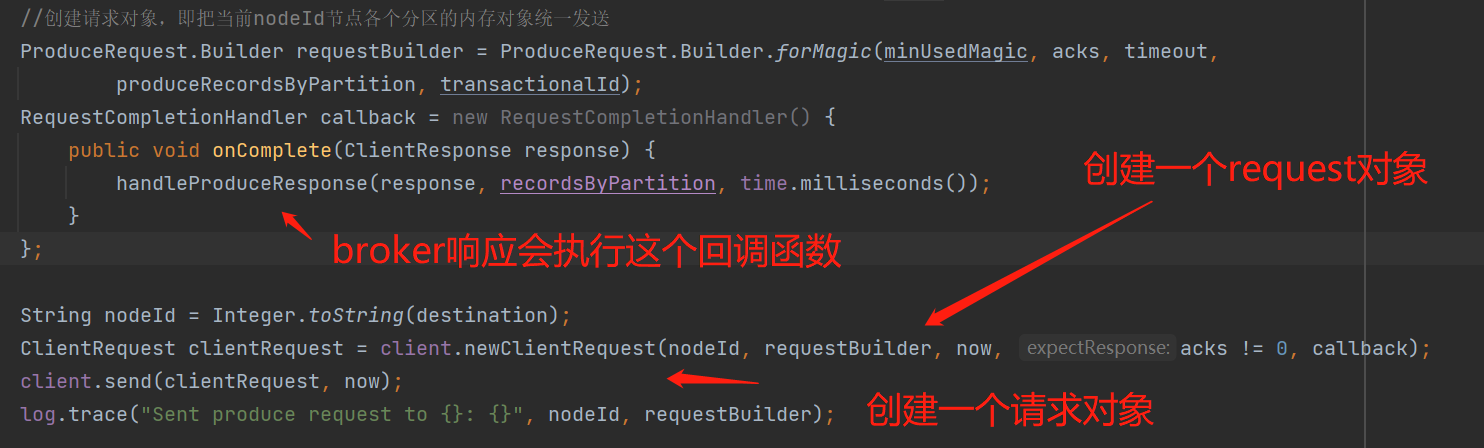
client.send():最终会调用下图的toSend,将本次的请求数据转换成Send:
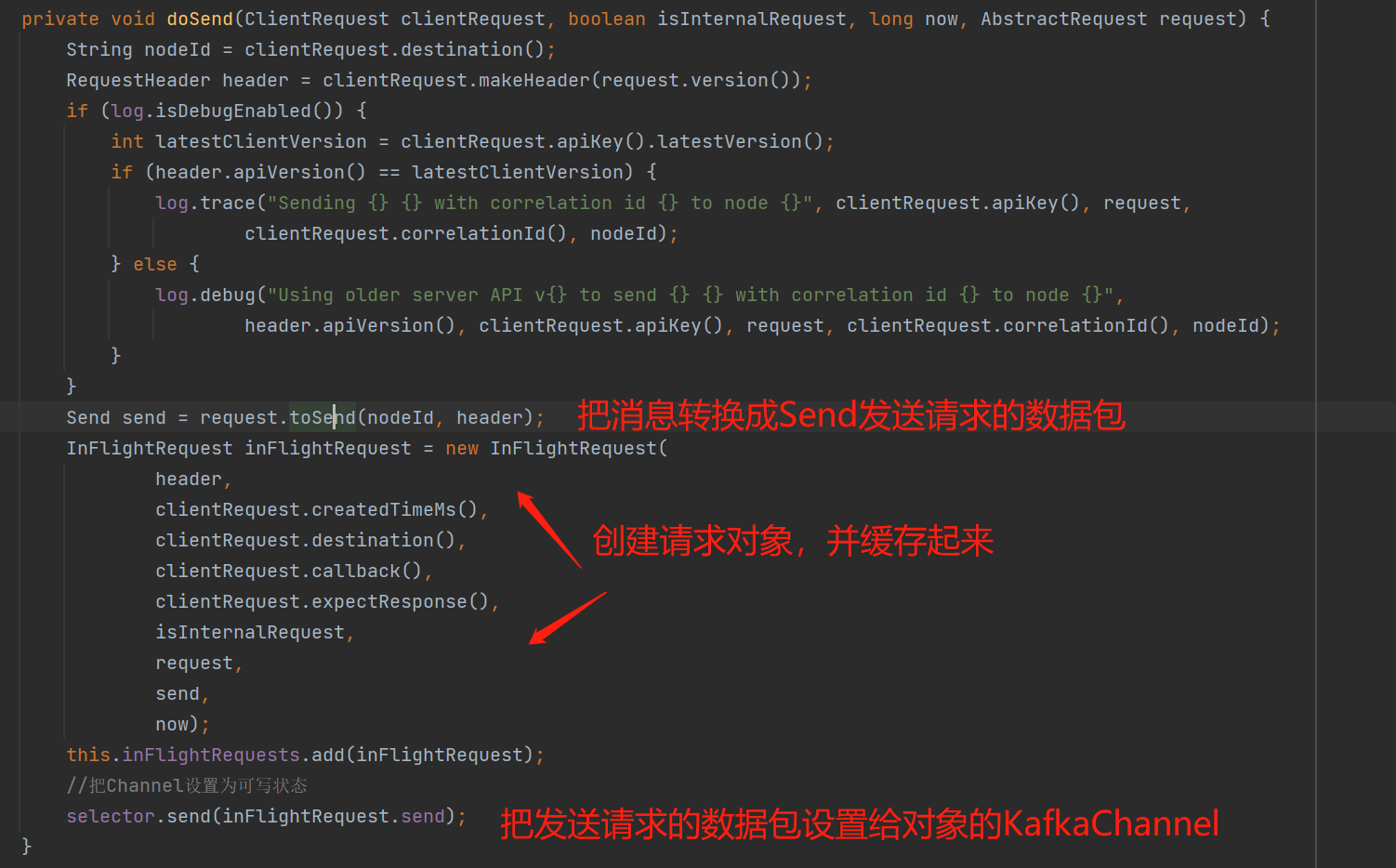
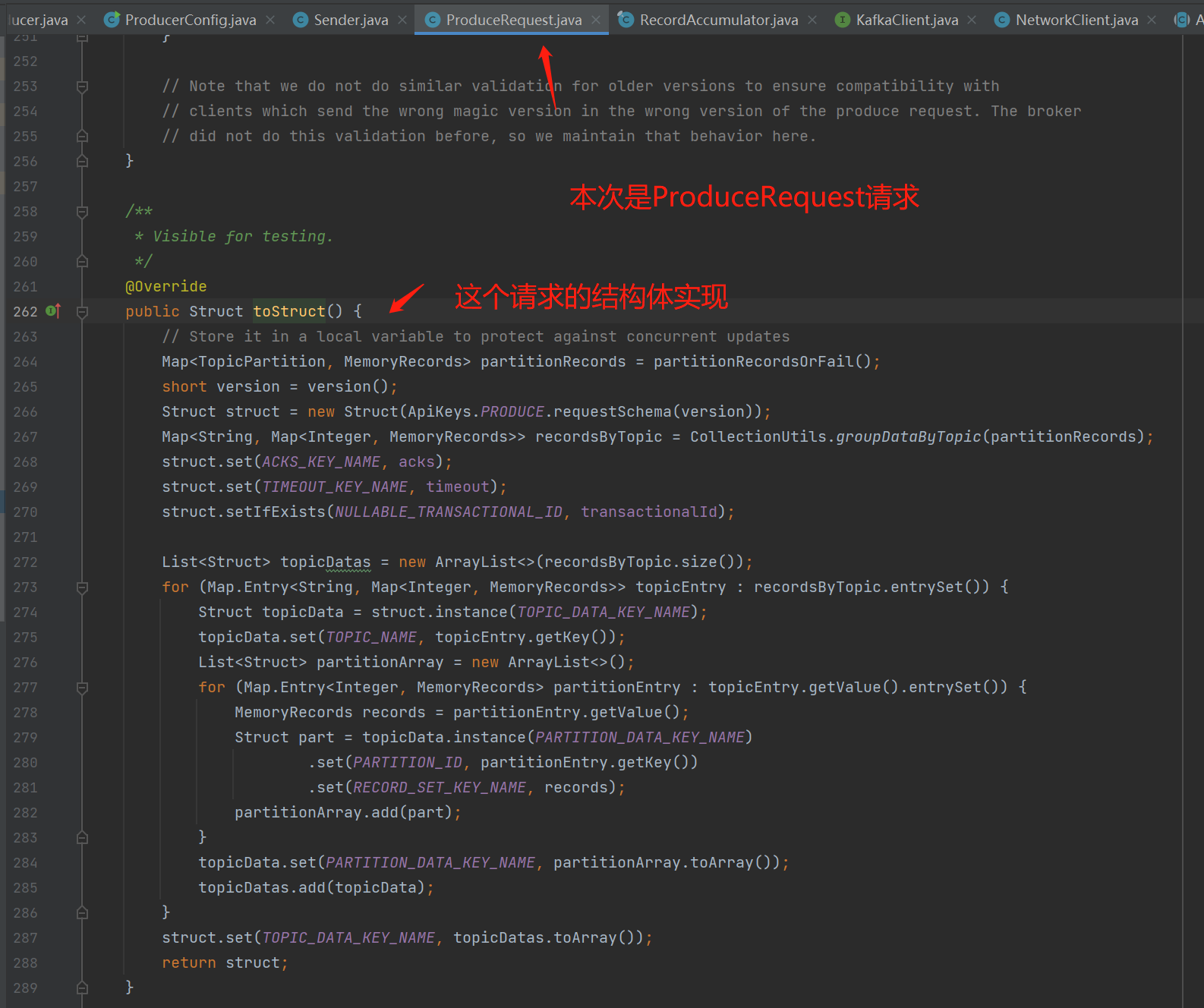
request.toSend():具体看看序列化API的实现:

把发送数据序列化到ByteBuffer:

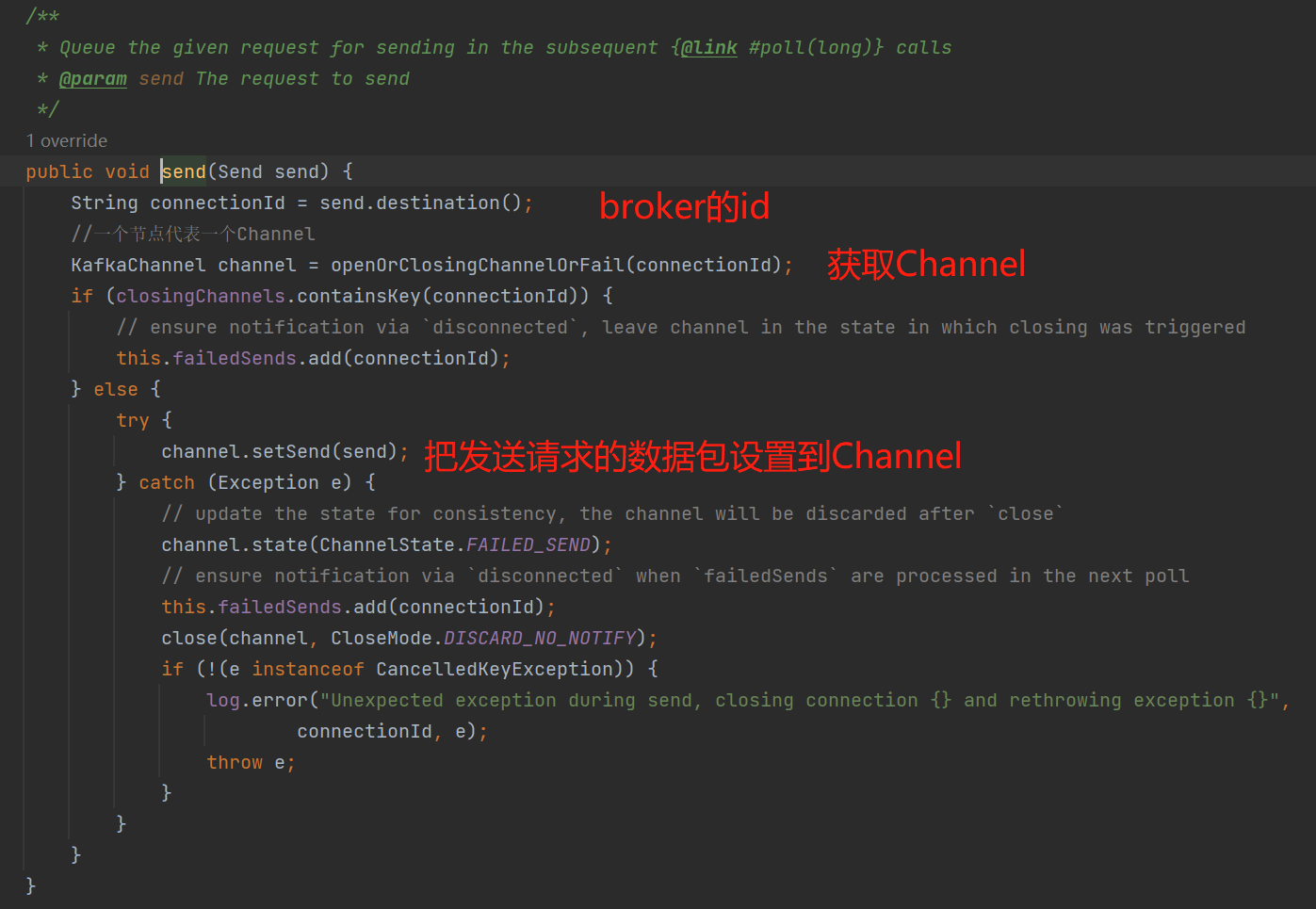
selector.send():最终将创建的NetWorkSend这个请求的网络数据包设置到相对应的KafkaChannel:
小结一下:sendProducerData()这个API做的事情:
- 会把各个节点的各个分区批数据队列的第一个batch进行发送,每个节点每次的请求最大字节是1MB的大小,这里需要注意的是broker端配置的接收最大字节;
- 池中的batch默认超过30s会过期,即丢弃,不发送了;
- 最后是把每个节点收集到本次要发送的batch集合,把这些batch集合数据转换成一个Send发送请求的数据包,然后设置给相对应的KafkaChannel,并且标记网络事件为WRITE事件,即当前Channel是要发送数据的状态。
client.poll()
sendProducerData()会把各个broker需要发送的批数据转换成Send发送请求的网络数据包,并且设置到各个的KafkaChannel、WRITE事件。这些事情做完后,接下来才真正的执行网络I/O操作,即调用client.poll()。如下图:
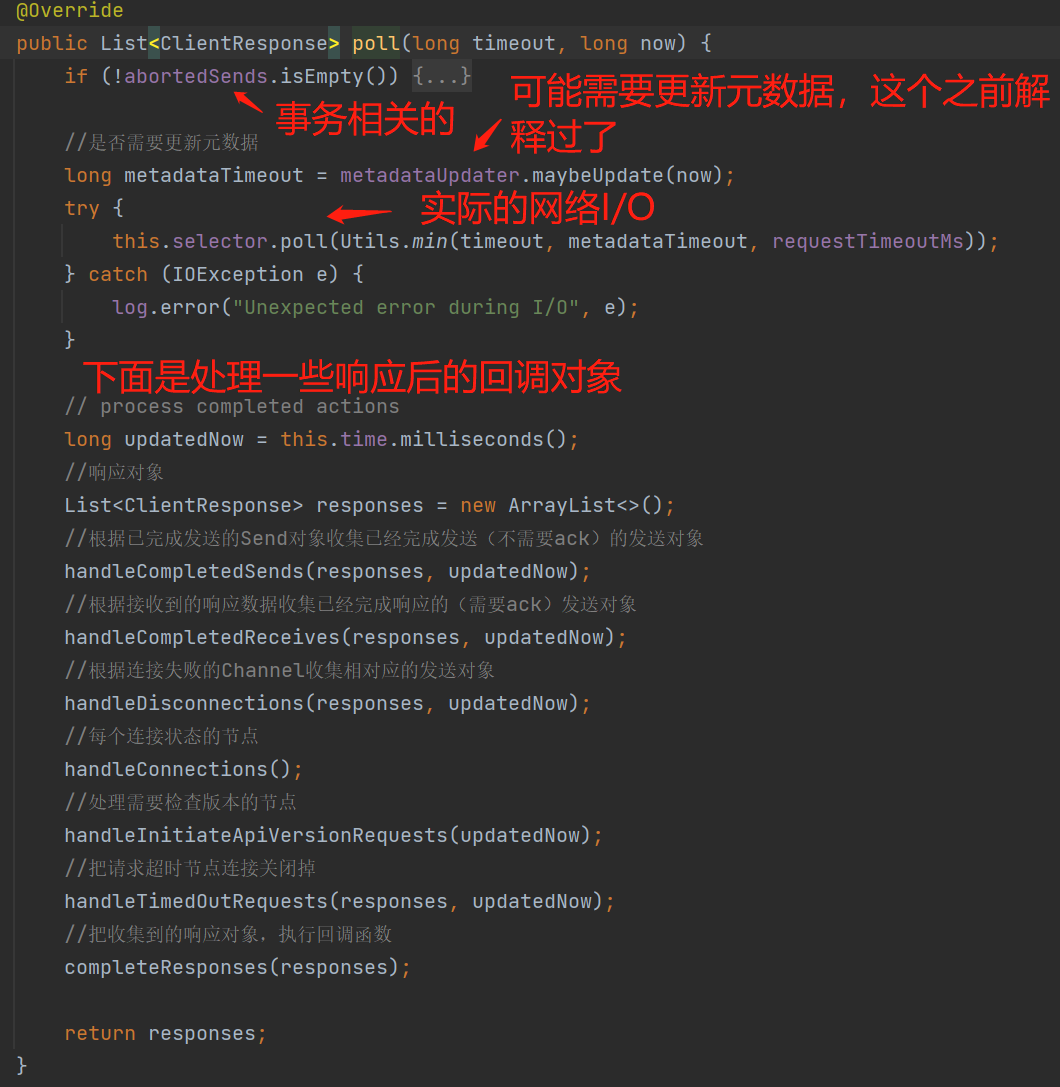
this.selector.poll():实际的网络I/O操作。
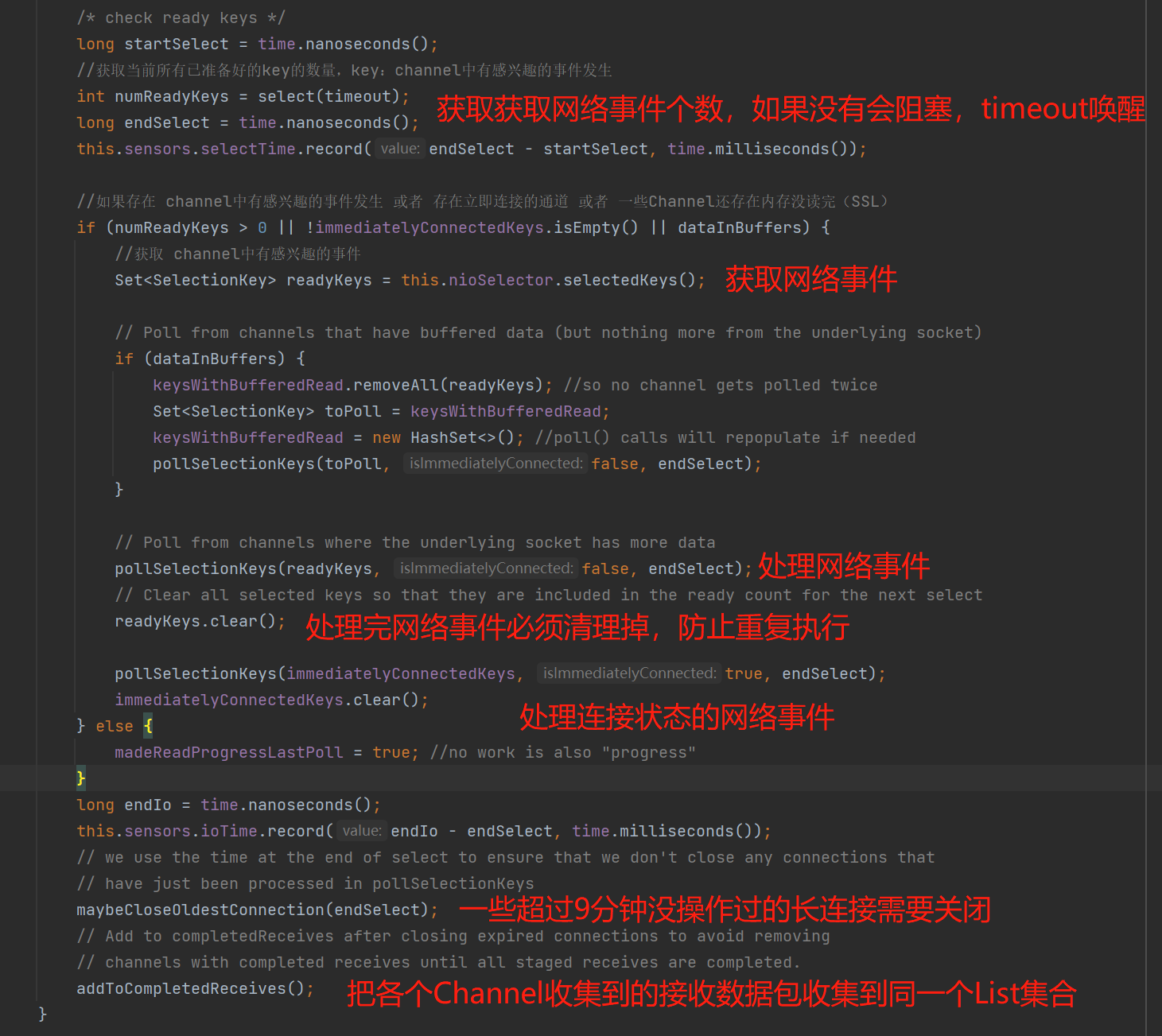
上图中核心是看pollSelectionKeys(),这个API的作用是处理网络事件:
1、处理连接的网络事件:PS:下图文字出错: 更新一些该Channel的操作网络事件的事件,正确的应该是:更新一下该Channel的操作网络事件的时间
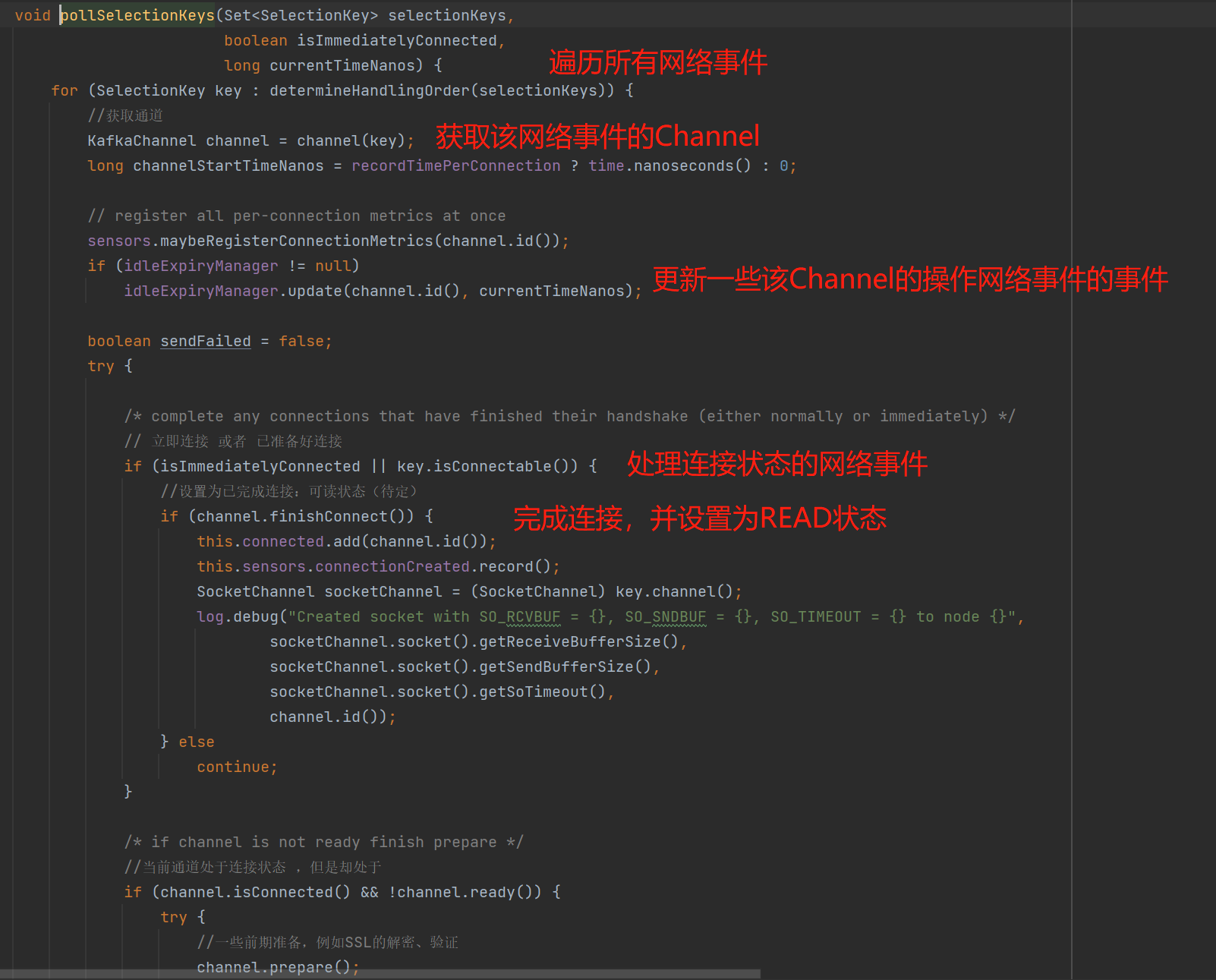
2、网络I/O读写数据前的准备,例如SSL、SASL的验证:
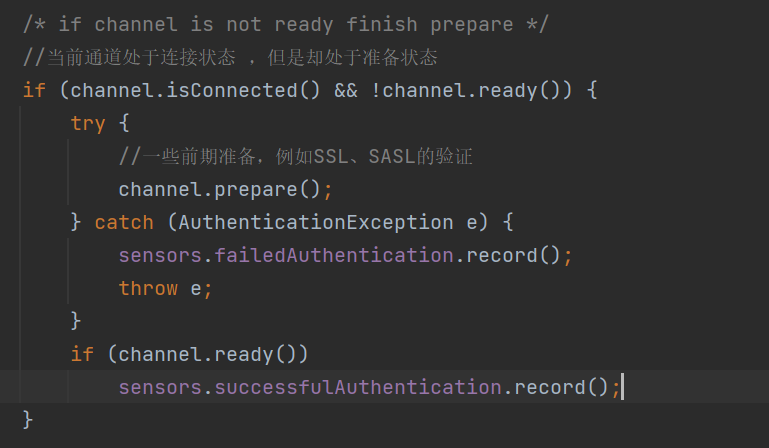
3、处理可读的网络事件,即接收broker的response的数据包:

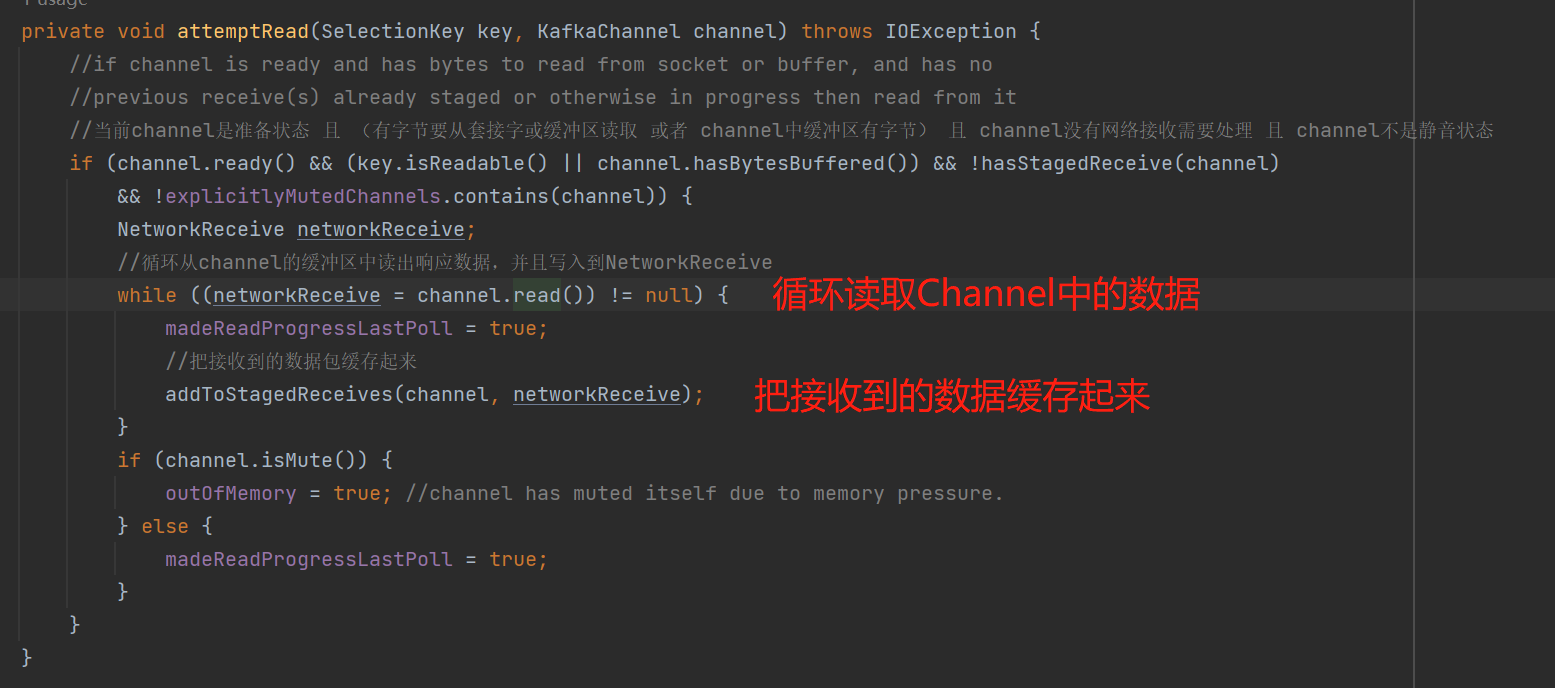
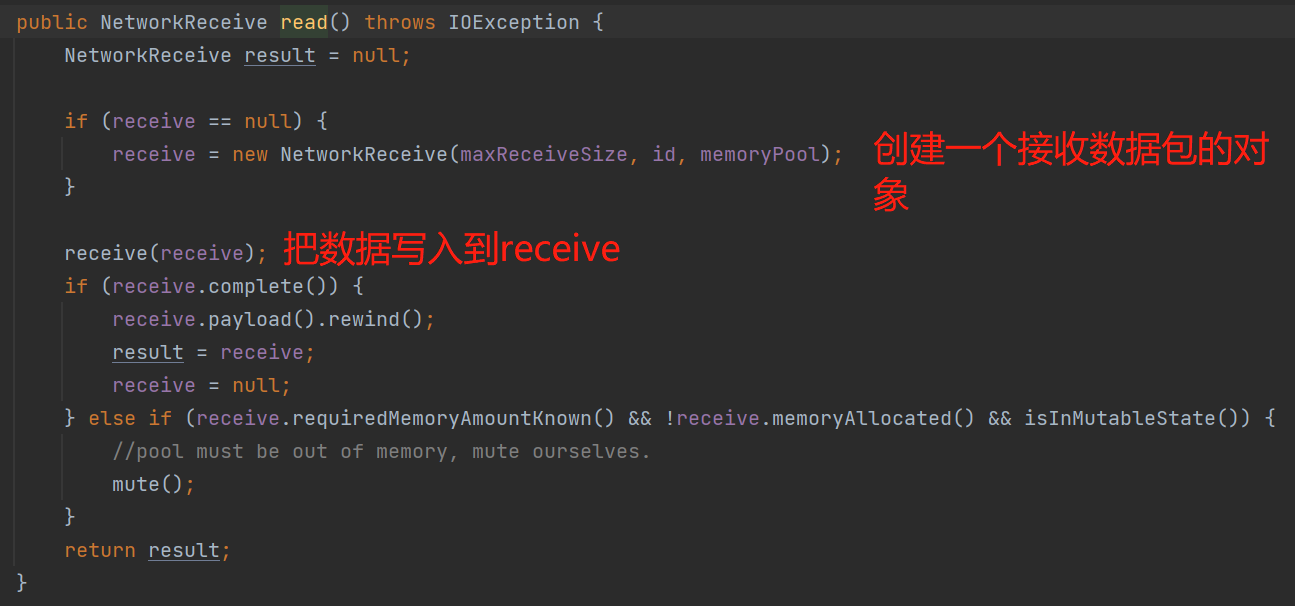
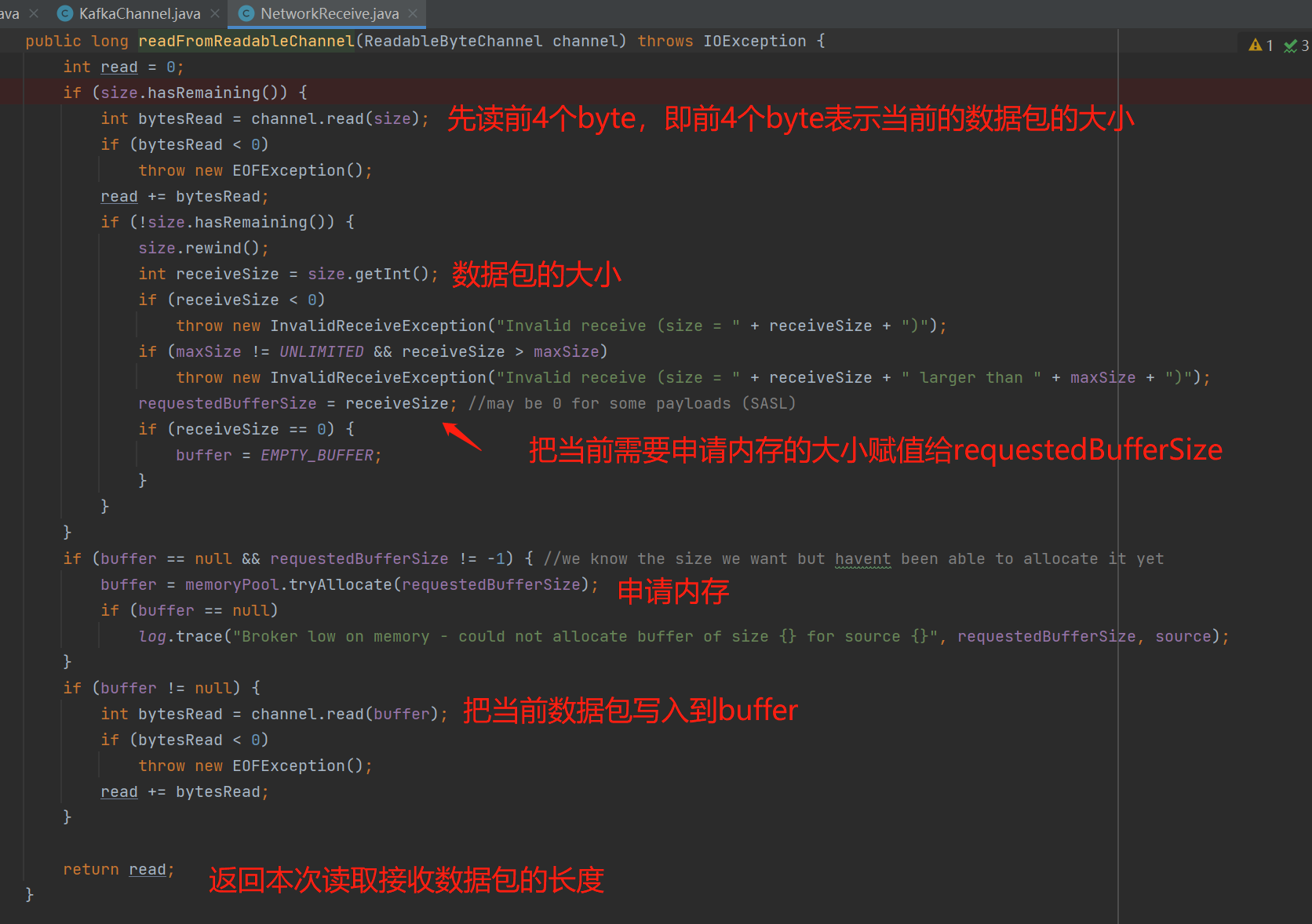
从上图可知,broker响应的数据包,最终是写入到NetworkReceive。
4、处理可写的网络事件,即发送到broker的请求:
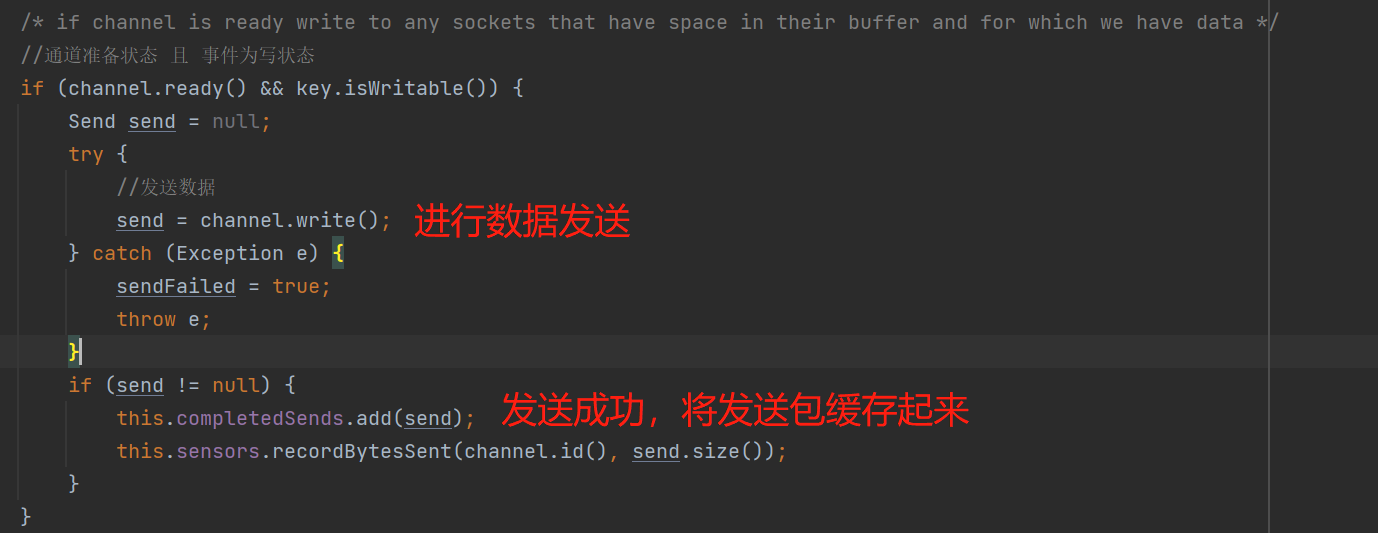
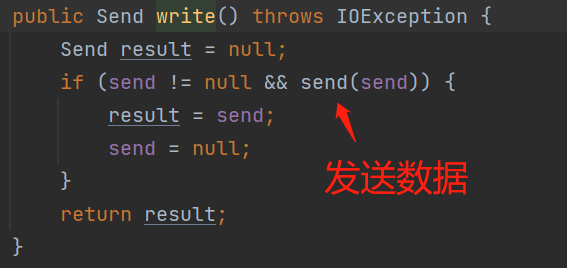
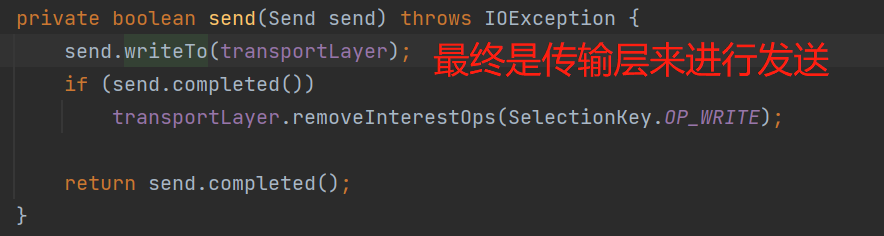
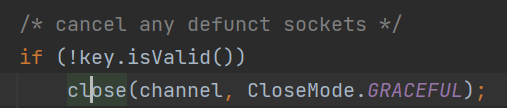
5、处理无效的网络事件,并关闭该网络事件的连接:
小结一下:pollSelectionKeys()执行着实际的网络I/O事件,Send是发送的网络数据包,NetworkReceive是接收的网络数据包。
网络I/O操作完之后,还需做一些流程完成的操作,如下图几个API,例如response后需执行回调对象等等,我这里就简单说下handleCompletedReceives()、completeResponses()。
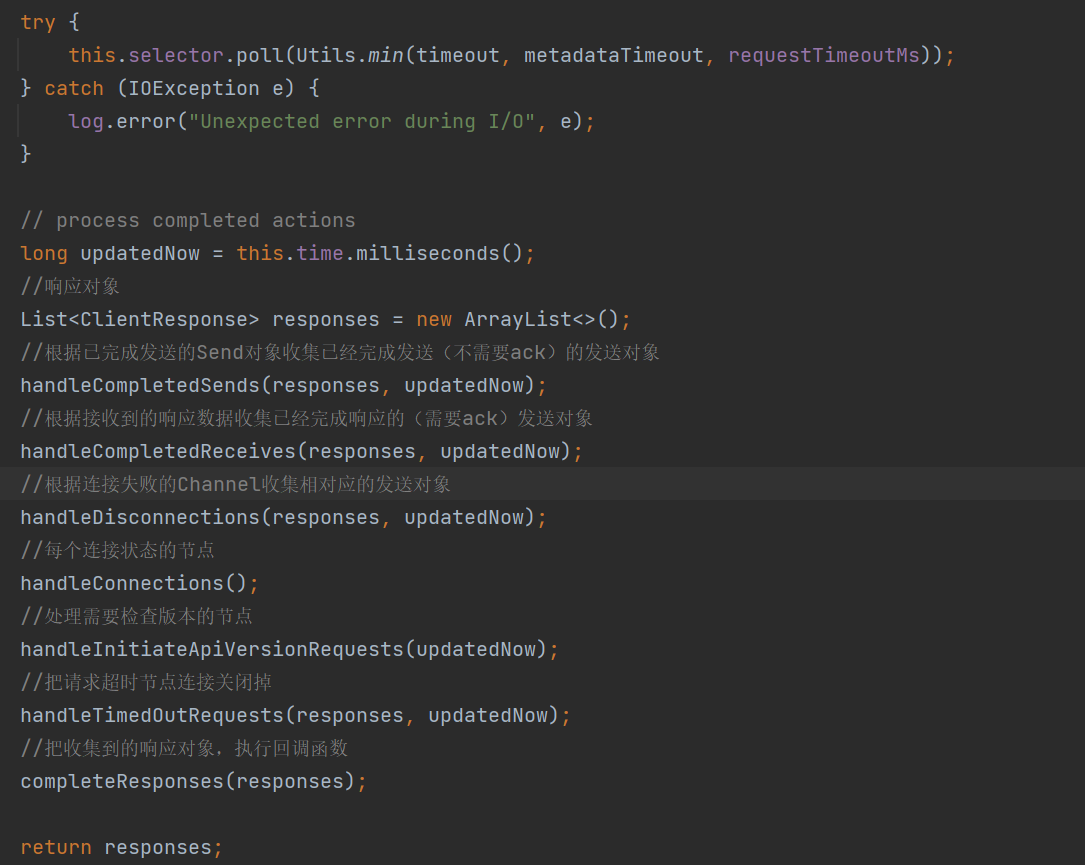
handleCompletedReceives():执行一些内部请求的response、外部response则是收集起来。
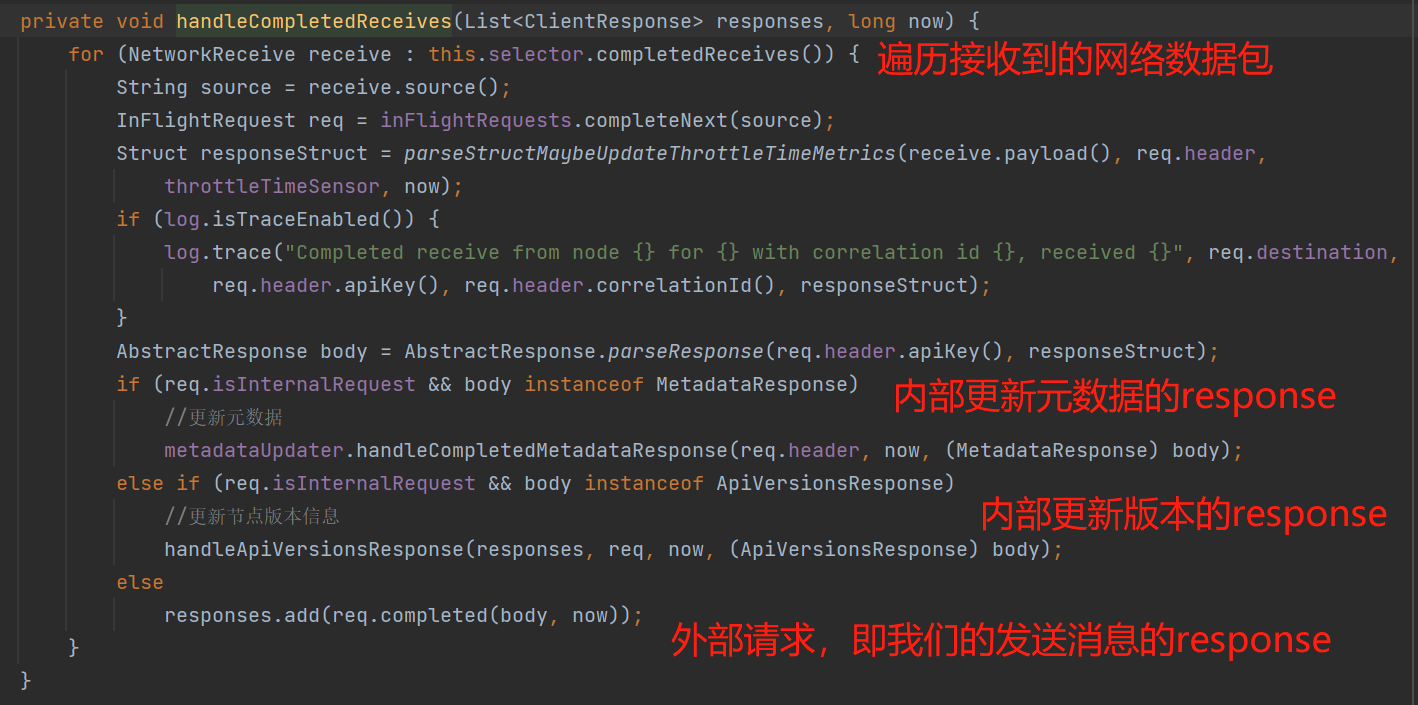
completeResponses():执行收集到的响应对象的回调函数,如下图:
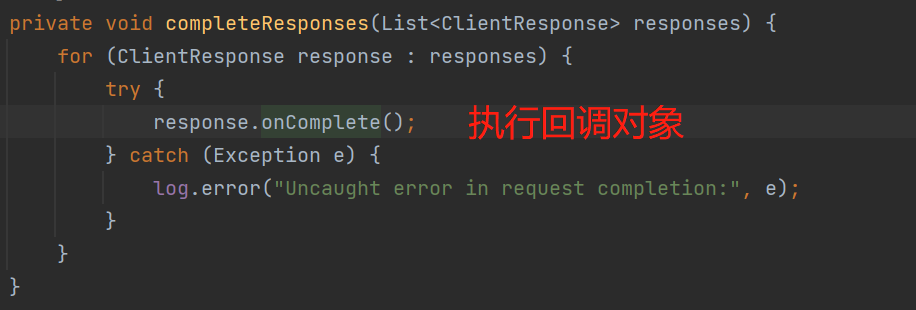
回调对象就是我们创建request注册的回调对象:

handleProduceResponse(),最终会根据broker返回的状态来执行不同的逻辑,根据写入成功或者失败来执行我们注册的回调对象;也就是说,如果我们有在发送消息的时候设置回调对象,其实是网络I/O线程来执行处理,所以这一点需要注意。PS:这个API的代码量挺多的,但是并不复杂,这里就不贴图了。
网络相关的知识就说到这里了。
一图胜千言
结束语
- 本文只是从源码的角度去学习KafkaProducer的原理设计,还有很多一些例如拦截器、数据收集、测量等等扩展性的东西、消息丢失问题、事务消息、kafka如何解决的网络的粘包和拆包问题、发送失败后的重试机制等等都没展开说,后期有时间再整理另一篇文章说吧。
- 原创不易
- 希望看完这篇文章的你有所收获!
相关参考资料
- kafka源码github地址 ,下载完之后,代码模块对应的是clients模块,版本:kafka-1.1.1。