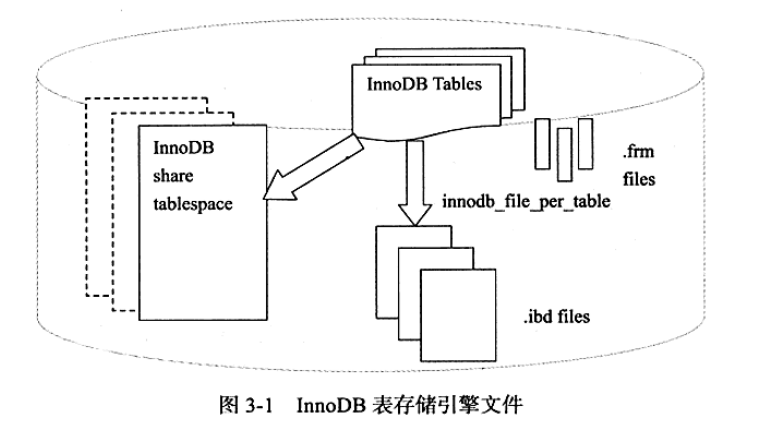
InnoDB存储引擎文件
InnoDB存储引擎文件中,为每个表提供了独立的表空间文件,并且还提供了重做日志文件(redo log).
表空间文件
InnoDB存储引擎对数据的存储采用了按表空间进行存放,默认初始化一个10MB的ibdata1文件(ibdata1为文件名称);若设置参数 innodb_data_file_path, 所有基于InnoDB存储引擎的表的数据都会存到该共享表空间中;若设置了参数 innodb_file_per_table ,则InnoDB存储引擎会基于每张表生成各自独立的表空间文件,独立表空间文件的命名规则为 : 表名.ibd,通过设置该参数,不用将所有的数据都存放于默认表空间中.
// 参数 innodb_data_file_path 可设置多个ibdata文件
[mysqld]
innodb_data_file_path = /db/ibdata1:2000M;/dr2/db/ibdata2:2000M:autoextend
/db/ibdata1 、 /dr2/db/ibdata2 分别用于两个文件夹来存放两个表空间,存放于两个文件夹在不同磁盘上,磁盘的负载可能被均衡,可以提高数据库的整体性能
/db/ibdata1 : 大小为 2000MB
/dr2/db/ibdata2 : 大小为 2000MB 如果用完2000MB,该文件也会自增长(autoextend)
// 参数 innodb_file_per_table = ON ,则表示 InnoDB存储引擎会产生每张表的单独的.idb独立表空间文件
【PS : 这些单独的表空间文件仅存储该表的数据、索引、插入缓存BITMAP等信息,其余信息都是存放于默认表空间中】
InnoDB存储引擎提供的事务日志
redo log : 在默认情况下,InnoDB存储引擎的数据目录下有两个名为 ib_logfile0 和 ib_logfile1 文件来存储redo log内容.
undo log : undo log的内容位于共享表空间中,但是参数 innodb_undo_directory 可以用来设置undo log内容存放在共享表空间以外的位置,即可以设置独立表空间,名称前缀为 undo.
InnoDB逻辑存储结构
在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式称之为 "索引组织表",且每张表都有主键(唯一性),如果创建表的时候,没有显示地定义主键,InnoDB存储引擎会做以下的操作 :
- 1.首先判断表中是否含有非空的唯一索引,如果有,则该列就是主键;
- 2.如果不符合上述第一条条件,InnoDB存储引擎会自动创建一个6字节大小的指针RowId
【PS : 当表中存在多个非空唯一索引时,InnoDB存储引擎会选择建表时第一个定义的非空唯一索引作为主键,这里的顺序指的是定义索引的顺序,而不是建表时列的顺序】
InnoDB存储引擎把所有数据都存放在表空间,表空间由段(segment)、区(extent)、页(page)组成,如下图 :

表空间
InnoDB存储引擎在默认的情况下会有一个共享表空间(ibdata1),即将所有的数据存放在这个表空间内;如果开启参数 innodb_file_per_table,则每张表都有独立的表空间文件,并且每张独立的表空间文件只存放数据、索引、插入缓存Bitmap页,而其他类型的数据 : 回滚(undo)信息 、 插入索引页 、 系统事务信息、二次写缓冲等还是存放在原来的共享表空间中.
段
表空间由多个段组成,常见的段有数据段、索引段、回滚段等.
区
区由连续页(多个页连续)组成的,每个区的大小为1MB,默认情况下,InnoDB存储引擎数据页的大小为16KB,即一个区为64个数据页(16KB * 64 = 1024KB,默认情况下存储引擎页的大小为 16KB).
InnoDB存储引擎一次向磁盘申请 4 ~ 5 个 区( 4 ~ 5 MB);
InnoDB存储引擎在对创建的表中默认大小为 96KB,即6个数据页;
InnoDB存储引擎一开始使用每个段的时候,会先用32个碎片页来存放数据,使用完这32个碎片页后才会申请64个连续的数据页;(这样做的目的是对于小表或者undo这类的段,可以在最开始使用的时候申请较少的空间,节省磁盘空间);
【PS : InnoDB 1.0.x版本开始引入压缩页,每个页的大小可以通过参数 KEY_BLOCK_SIZE 设置为 2K、4K、8K,因此每个区对于页的数量为 : 512、256、128】
【PS : InnoDB 1.2.x版本开始引入参数 innodb_page_size,通过改参数可以设置页的大小(4K、8K、16K等),但是不是压缩页,相对应区的页的数量为 : 256、128、64等,该参数默认为 16KB】
页
页是InnoDB存储引擎在磁盘上的最小存储单位,且每个页的大小默认为16KB,InnoDB 1.2.x版本开始,参数innodb_page_size 可以将页的大小设置为 4K \ 8K \ 16K,设置完成后,所有表的页的大小为innodb_page_size,不能再修改.
常用页的类型 :
- 数据页(B-tree Node)
- undo 页(Undo log Page)
- 系统页
- 事务数据页
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(compressed BLOB Page)
行
InnoDB存储引擎对于数据是按行存储的,每个数据页存放着多行记录,最多可存放 (16KB / 2 - 200 ) 7992行记录.
InnoDB行记录格式 --- Compact
InnoDB存储引擎存储数据是以行的形式存储,也就是在页中保存着表中多行的数据.
【PS : 在InnoDB 1.0.x版本之前,InnoDB存储引擎提供了Compart和Redundant两种格式来存放行记录数据,Redundant是为了兼容之前版本而保留的】
【PS : Compart格式是在InnoDB 5.0版本引入了,简单来说,一个页中存放的行数据越多,其性能越高】
Compact行记录格式

非NULL变长字段长度列表 --- varchar
记录了非NULL的varchar类型的字段长度,并且是按照列的顺序逆序放置;如果列的实际存储长度小于255字节,则用1字节来表示该列的长度,反之如果大于255,则2字节来表示该列的长度.varchar字段的长度最大不会超过2字节,这样就很好的解释了varchar类型的最大长度为65535了.
NULL标志位 --- 1字节
NULL标志位是指该行数据是否存在NULL值字段,只针对可为NULL的字段,不针对不为NULL的字段,该部分占用1字节的大小.
记录头信息 --- 固定5字节长度
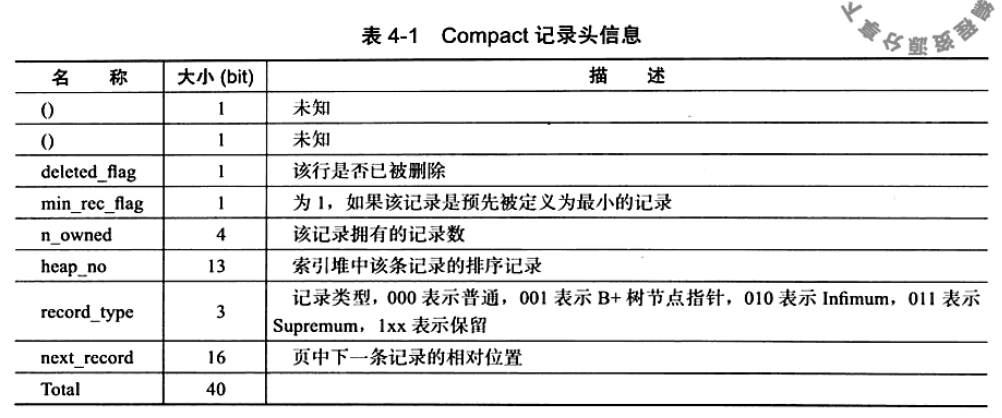
- 前两个为预留位
- deleted_flag : 该行是否已被删除,0表示没有删除,说明删除的数据很可能还在页中,并且占用着空间;该属性可结合Undo log和Purge线程.
- min_rec_mask : 标记该记录是否为B+Tree的非叶子节点中的最小记录
- n_owned : 表示当前槽里面管理的记录数
- next_record : 说明数据页中的多行数据是由单向链表串联起来的.
存储列的数据
最后一部分就是实际存储的每个列的数据,NULL值不占用该部分的任何空间,即NULL只占用了NULL标志位,实际存储不占有任何空间.
InnoDB存储引擎对于每行数据还有两个隐藏列,即事务ID和回滚指针,这两个隐藏列可结合Undo log和MVCC;事务ID占用6字节的大小,回滚指针占用7字节的大小,如果没有定义主键,InnoDB存储引擎还会给每行增加一个6字节大小的RowId列.
实践
// t1 t2 t3 t4字段都可为空、且字符集为LATIN1 行格式类型为COMPACT
// 该表没有显示的创建主键
CREATE TABLE `latin1_test` (
`t1` varchar(10) DEFAULT NULL,
`t2` varchar(10) DEFAULT NULL,
`t3` char(10) DEFAULT NULL,
`t4` varchar(10) DEFAULT NULL
) ENGINE=InnoDB CHARSET=LATIN1 ROW_FORMAT=COMPACT;
// 插入三行数据
INSERT INTO latin1_test(t1,t2,t3,t4) VALUES('a','bb','bb','ccc');
INSERT INTO latin1_test(t1,t2,t3,t4) VALUES('d','ee','ee','fff');
INSERT INTO latin1_test(t1,t2,t3,t4) VALUES('d',NULL,NULL,'fff');
打开表空间文件latin1_test.idb,Window系统可使用UltraEdit打开二进制文件或者使用Notepad++和HexEditor插件,Linux系统可使用hexdump,本文是在Window系统下使用Notepad++和HexEditor插件.下图为插入三行数据的存储在latin1_test.idb的格式 :

第一行数据 --- 'a','bb','bb','ccc'
03 02 01 // 非NULL变长字段长度列表,逆序存放,即对应的是 ccc bb a
00 // NULL标志位,该行数据的全部字段都不为NULL,所以是00
00 00 10 00 2c // 记录头信息 --- 固定5字节,0x2c表示next_recorder,下一个记录的偏移量,即当前记录的位置加上偏移量0x2c就是下一条记录的起始位置
00 00 00 00 03 15 // 6个字节的RowId,InnoDB存储引擎自己创建的,6个字节
00 00 00 00 3b 48 // 6个字节的TransactionID
81 00 00 01 26 01 10 // 7个字节的Roll Pointer
61 // 列t1数据 a
62 62 // 列t2数据 bb
62 62 20 20 20 20 20 20 20 20 // 列t3数据 bb 由于是char类型,所以后面8个字符由0x20补上
63 63 63 // 列t4数据 ccc
第二行数据 --- 'd','ee','ee','fff'
03 02 01 // 非NULL变长字段长度列表,逆序存放,即对应的是 fff ee d
00 // NULL标志位,该行数据的全部字段都不为NULL,所以是00
00 00 18 00 2b // 记录头信息 --- 固定5字节
00 00 00 00 03 16 // 6个字节的RowId,InnoDB存储引擎自己创建的,6个字节
00 00 00 00 3b 49 // 6个字节的TransactionID
82 00 00 01 2a 01 10 // 7个字节的Roll Pointer
64 // 列t1数据 d
65 65 // 列t2数据 ee
65 65 20 20 20 20 20 20 20 20 // 列t3数据 ee 由于是char类型,所以后面8个字符由0x20补上
66 66 66 // 列t4数据 fff
第三行数据 --- 'd',NULL,NULL,'fff'
03 01 // 非NULL变长字段长度列表,逆序存放,即对应的是 fff d
06 // NULL标志位,该行数据的t2、t3字段为NULL,所以需要记录,即06转二进制为 00000110,1为代表为NULL,则表示第二、三列为NULL值,在COMPART格式下,不管是char或者varchar类型,NULL值不占用实际的存储空间
00 00 20 ff 98 // 记录头信息 --- 固定5字节
00 00 00 00 03 17 // 6个字节的RowId,InnoDB存储引擎自己创建的,6个字节
00 00 00 00 3b 4e // 6个字节的TransactionID
81 00 00 00 f2 01 10 // 7个字节的Roll Pointer
64 // 列t1数据 d
#65 65 // 列t2数据 ee
#65 65 20 20 20 20 20 20 20 20 // 列t3数据 ee 由于是char类型,所以后面8个字符由0x20补上
66 66 66 // 列t4数据 ccc
相同的数据,不同的字符集,看看UTF8字符集是怎么样存储的:
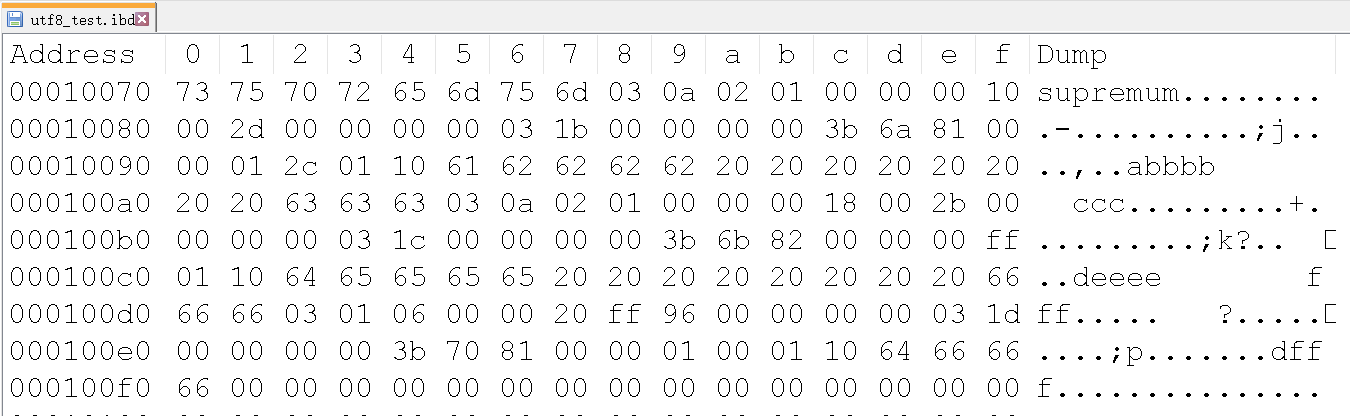
- 第一行 : 'a','bb','bb','ccc'
03 0a 02 01 // 非NULL变长字段长度列表,逆序存放,即对应的是 ccc bb bb a ,相对于latin1,char类型也存储进来了 0x0a = 10
00 // NULL标志位,该行数据的全部字段都不为NULL,所以是00
00 00 10 00 2d // 记录头信息 --- 固定5字节,0x2c表示next_recorder,下一个记录的偏移量,即当前记录的位置加上偏移量0x2d就是下一条记录的起始位置
00 00 00 00 03 1b // 6个字节的RowId,InnoDB存储引擎自己创建的,6个字节
00 00 00 00 3b 3a // 6个字节的TransactionID
81 00 00 01 2c 01 10 // 7个字节的Roll Pointer
61 // 列t1数据 a
62 62 // 列t2数据 bb
62 62 20 20 20 20 20 20 20 20 // 列t3数据 bb 由于是char类型,所以后面8个字符由0x20补上
63 63 63 // 列t4数据 ccc
- 第二行 : 'd','ee','ee','fff'
03 0a 02 01 // 非NULL变长字段长度列表,逆序存放,即对应的是 fff ee ee d
00 // NULL标志位,该行数据的全部字段都不为NULL,所以是00
00 00 18 00 2b // 记录头信息 --- 固定5字节
00 00 00 00 03 1c // 6个字节的RowId,InnoDB存储引擎自己创建的,6个字节
00 00 00 00 3b 6b // 6个字节的TransactionID
82 00 00 00 ff 01 10 // 7个字节的Roll Pointer
64 // 列t1数据 d
65 65 // 列t2数据 ee
65 65 20 20 20 20 20 20 20 20 // 列t3数据 ee 由于是char类型,所以后面8个字符由0x20补上
66 66 66 // 列t4数据 fff
- 第三行 : 'd',NULL,NULL,'fff'
03 01 // 非NULL变长字段长度列表,逆序存放,即对应的是 fff d
06 // NULL标志位,该行数据的t2、t3字段为NULL,所以需要记录,即06转二进制为 00000110,1为代表为NULL,则表示第二、三列为NULL值,在COMPART格式下,不管是char或者varchar类型,NULL值不占用实际的存储空间
00 00 20 ff 96 // 记录头信息 --- 固定5字节
00 00 00 00 03 1d // 6个字节的RowId,InnoDB存储引擎自己创建的,6个字节
00 00 00 00 3b 70 // 6个字节的TransactionID
81 00 00 01 00 01 10 // 7个字节的Roll Pointer
64 // 列t1数据 d
#65 65 // 列t2数据 ee
#65 65 20 20 20 20 20 20 20 20 // 列t3数据 ee 由于是char类型,所以后面8个字符由0x20补上
66 66 66 // 列t4数据 ccc
InnoDB行记录格式 --- Redundant

不同于Compart格式,Redundant格式的首部是一个字段长度偏移列表,同样的也是按照列的顺序的逆序放置,若列的长度小于255字节,则用1字节的大小表示,反之大于255则2字节的大小表示;Redundant的记录头信息不同于Compart,Redundant的记录头信息占用6字节,如下图 :
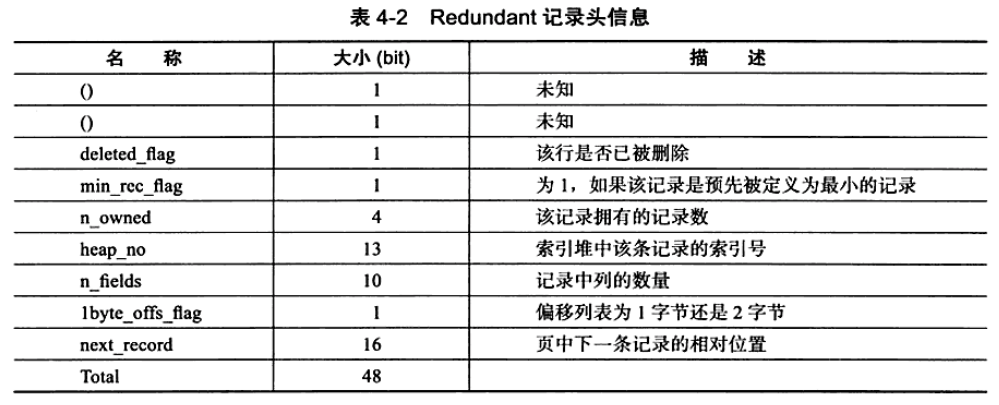
- n_fields : 表示一行记录中列的数量,占用10 bit,说明MySQL数据库一行数据最多支持1023个列
- lbyte_offs_flags : 该值定义了偏移列表占用1字节还是2字节.
- 最后部分就是实际存储的每个列的数据.
行溢出数据
InnoDB存储引擎可以将一条记录中的某些数据存储在数据页之外,例如BLOB、LOB这类大对象数据类型的存储,BLOB并不都是将数据放在溢出页中,而varchar类型也会存放溢出页的可能.
MySQL对于varchar类型并不支持存放65535字节,因为有其他开销,所以实际存放的最大长度是65532;由于varchar类型最大支持是65532字节,而创建表的时候使用的varchar(N)的字段中,N是字符,所以创建表的时候varchar(N)的N与字符集是息息相关的.
varchar的最大长度相关知识参考链接 :
行溢出的处理方式
InnoDB存储引擎默认的数据页大小为16KB.即16384字节,明显是不够存储65532字节的.当发生行溢出的时候,数据存放在页类型为Uncompress BLOB页中,如下图 :

从上图可以知道,行数据实际存储的是前765字节的前缀,之后是偏移量,指向行溢出页,行溢出页就是Uncompressed BLOB Page.
由于InnoDB存储引擎对于数据的存储是使用B+Tree存储结构,所以上面图中这样的设计可以保证每个页中至少有两条记录,即每个页中有多条数据.否则失去了B+Tree的意义,变成链表了.
【PS : 对于TEXT 、 BLOB 这些大对象的数据类型,并不是这种大对象的数据类型就会使用Uncompressed BLOB Page来存放,是不是使用溢出页来存放,同varchar类型一样,需要保证一个页至少存放两条数据】
【PS : 大多数情况下,BLOB类型的行数据是会出现行溢出,即实际数据保存在BLOB页,数据页只保存数据的前缀768字节】
Compressed和Dynamic行记录格式
InnoDB存储引擎 1.0.x版本开始引入新的文件格式,旧的格式称为Antelope文件格式(Compact 和 Redundant),新的格式成为Barracuda文件格式(Compressed 和 Dynamic)
新的两种记录格式对于TEXT、BLOB这种大对象的数据类型,都采用了行溢出的方式,即在数据页种只存放20个字节的指针,实际的数据存储在Off Page种,如下图 :
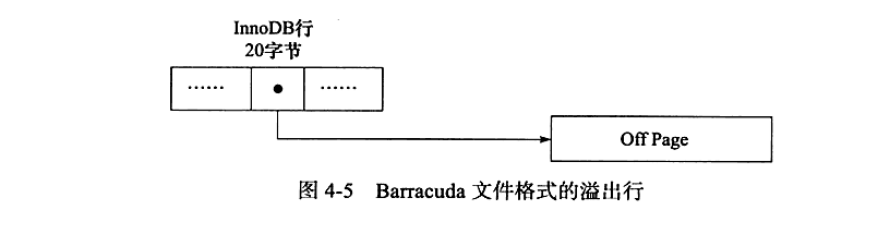
【PS : Compact 和 Redundant 两种格式会存放768个前缀字节】
【PS : Compressed 行记录格式存储行数据会以zlib的算法进行行压缩,对于BLOB\TEXT\VARCHAR这些大对象的数据类型都能够进行有效的存储】
InnoDB数据页的结构
InnoDB数据页由7部分组成 :
- File Header(文件头,固定大小38字节)
- Page Header(页头,固定大小56字节)
- Infimun 和 Supremum Records
- User Records(行记录,大小为动态的)
- Free Space(空闲空间,大小为动态的)
- Page Directory(页目录,大小为动态的)
- File Trailer(文件结尾信息,固定大小8字节)

File Header
File Header : 用来记录数据页的头信息,总共8个部分,38字节.
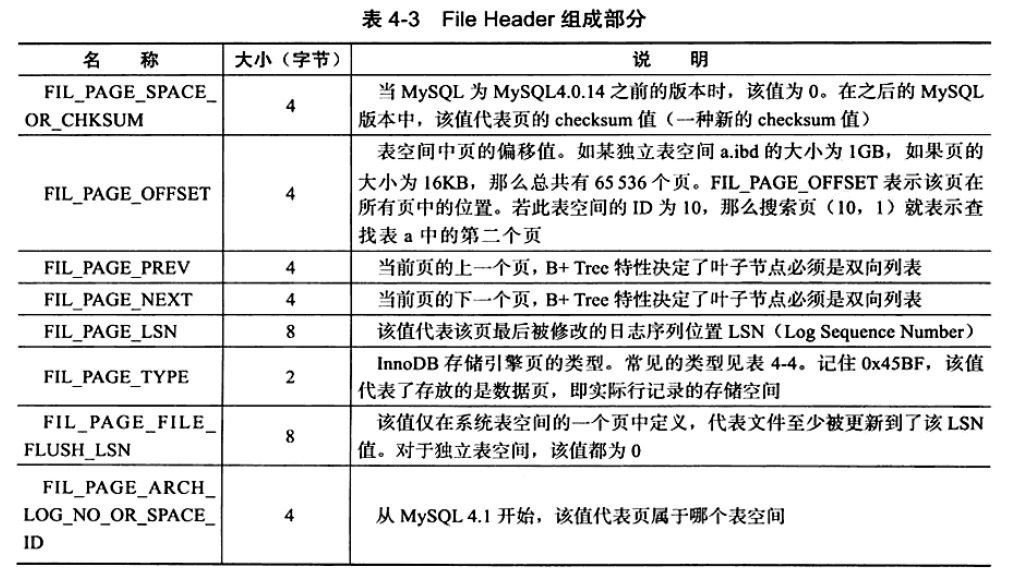
- FIL_PAGE_SPACE_OR_CHKSUM : 数据页的checksum值
- FIL_PAGE_OFFSET : 页号(偏移量)
- FIL_PAGE_PREV \ FIL_PAGE_NEXT : 上一页、下一页;B+Tree结点(数据页)之间是双向链表
- FIL_PAGE_LSN :页的LSN值,同redo log、BufferPool刷脏页知识点相关,即触发检查点
- FIL_PAGE_TYPE : 数据页类型,如下面的4-4图
- FIL_PAGE_FILE_FLUSH_LSN : 独立表空间,该值为0
- FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID : 表空间SPACE_ID

Page Header
Page Header : 用来记录数据页的状态信息,由14个部分组成,占用56字节.
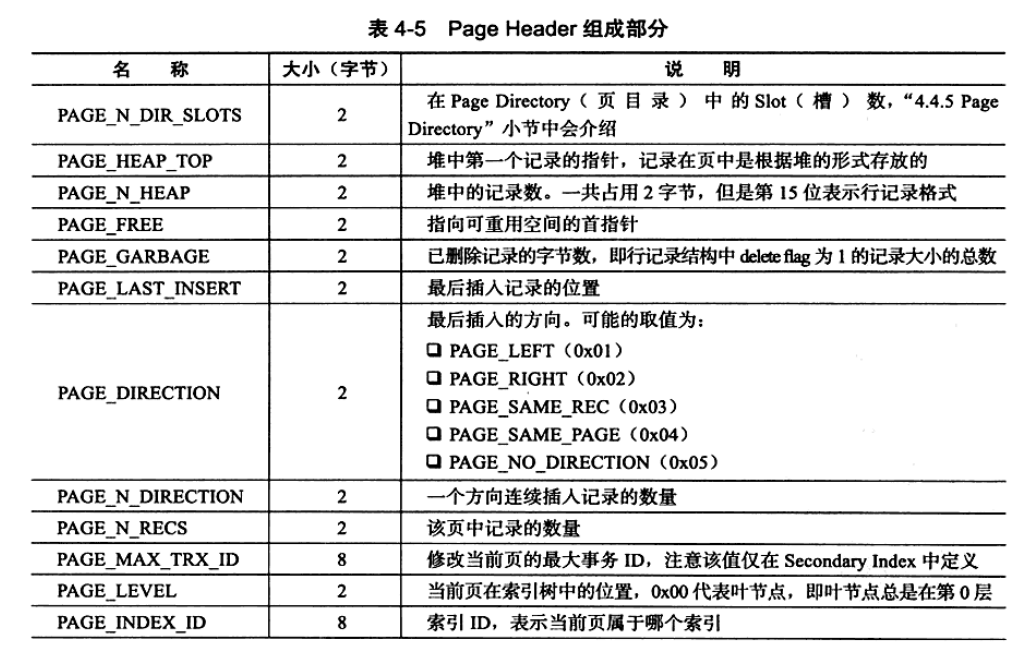

- PAGE_N_DIR_SLOTS : Page Directory(页目录)中的Slot(槽)数
- PAGE_HAEP_TOP : 表示空闲空间开始位置的偏移量
- PAGE_N_HAEP : 代表该页中实际的记录多少条记录,其中包括两条伪记录,且第15位表示行记录格式
- PAGE_FREE : 指向页中空闲位置的首指针(偏移量)
- PAGE_GARBAGE : 记录页中删除的数据(标记delete flag为1的数据)的总数
- PAGE_LAST_INSERT : 最后插入记录的位置偏移,即指向最后插入那条数据的偏移量
- PAGE_DIRECTION : 最后插入数据的插入方向
- PAGE_N_DIRECTION : 一个方向连续插入记录的数量
- PAGE_RECS : 当前数据页中含有多少条数据
- PAGE_MAX_TRX_ID : 修改当前页的最大事务ID
- PAGE_LEVEL : 当前页在B+Tree的层数,0x00代表叶子节点,即0层
- PAGE_INDEX_ID : 索引ID,表示当前页属于哪个索引
- PAGE_BTR_SEG_LEAF : B+Tree数据页非叶子节点所在段的segment header.注意该值仅在Tree的root页中定义
- PAGE_BTR_SEG_TOP : B+Tree数据页所在段的segment header
【PS : InnoDB在整个页可以使用的空间当成Heap(堆),当需要插入记录的时候,首先会检查PAGE_FREE指向的空闲空间,若申请的空间小于等于该空间容量时,那么使用该空闲空间,否者从PAGE_HEAP_TOP指向的空闲空间进行分配】
【PS : Heap中存储的记录非物理连续的,只是逻辑上连续的;PAGE_LAST_INSERT、PAGE_DIRECTION、PAGE_N_DIRECTION主要使用来做页分裂操作的】
Infimum 和 Supremum Record
在InnoDB存储引擎中,每个数据页都有两个虚拟的行记录,用来限定记录的边界.Infimum记录的是比该页中任何主键值都要小的值,Supremum记录的是比任何可能大的值还要大的值;这两个值在页被创建的时候被建立,并且在任何时候无法删除.

【PS : Page Header的PAGE_N_HAEP就包含了这两条伪记录】
【PS : Infimum行记录的next_record存放的是第一条实际用户记录】
User Record 和 Free Space
User Record : 实际存储行记录的内容,上面已经有基于行格式的存储格式进行实践分析过了.
Free Space : 空闲空间,同样是链表,在一条记录被删除后,该空间会被加入空闲链表中.
Page Directory
Page Directory : Page Directory(页目录)中存放了记录的相对位置,有些时候这些记录指针成为Slots(槽)或者目录槽.InnoDB存储引擎的槽是一个稀疏目录,即一个槽可能包含多个记录;Page Header中PAGE_N_DIR_SLOTS记录了槽数.
在Slots中记录按照索引键值顺序存放,这样可以利用二分查找找到记录指针.
【PS : 由于在InnoDB存储引擎中Page Direcotry是稀疏目录,二分查找的结果只是一个初略的结果,因此InnoDB存储引擎必须通过Recorder中的next_record来继续查找相关记录】
【PS : B+Tree索引本身并不能查找到具体的一行记录,能找到只是该记录所在的页,InnoDB把找到的页载入内存,然后通过Page Directory再进行二分查找】
File Trailer
File Trailer : 为了检测页是否完整地写入磁盘,InnoDB存储引擎的页设置了File Trailer,固定占用8个字节,并且是在页尾部.
前4个字节代表该页的checksum值,最后四个字节和File Header中的FIL_PAGE_LSN相同;这两个值与File Header中的FIL_PAGE_SPACE_OR_CHKSUM 和 FIL_PAGE_LSN值比较,看是否一致,依次来保证数据页的完整性.
结束语
- 将独立一篇文章来实践解析数据页的存储结构
- 原创不易
- 希望看完这篇文章的你有所收获!
相关参考资料
- MySQL技术内幕(第2版)【书籍】
- InnoDB数据页结构分析【链接】
- 位(bit)、字节(byte)、字符、编码之间的关系【链接】
- Mysql中varchar和char区别【链接】