
// 存在index_test 表
CREATE TABLE `index_test` (
`a` int(10) NOT NULL AUTO_INCREMENT,
`b` int(10) NOT NULL,
`c` int(10) NOT NULL,
`d` int(10) NOT NULL,
`e` varchar(20) NOT NULL,
PRIMARY KEY (`a`),
KEY `idx_bcd ` (`b`,`c`,`d`),
KEY `idx_e` (`e`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
// 插入数据
insert into index_test values(1,13,12,4,'dll'),
(2,1,5,4,'doc'),
(3,13,16,5,'img'),
(4,12,14,3,'xml'),
(5,1,1,4,'txt'),
(6,13,16,1,'exe'),
(7,5,3,6,'pdf');
index_test 表
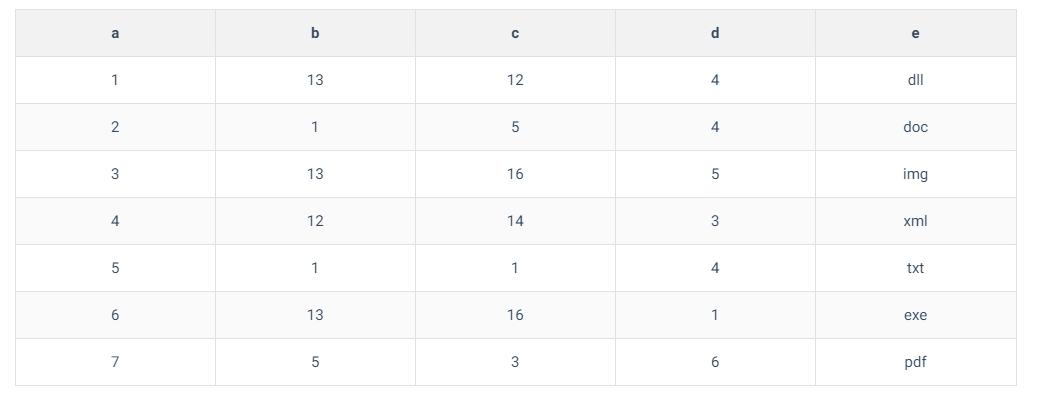
聚集索引
聚集索引:索引值的顺序和数据的存储顺序一致,是通过是主键值来维护的一颗B+Tree.
InnoDB引擎引擎的聚集索引 :
- 如果一个主键被定义了,那么这个主键就是作为聚集索引
- 如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引
- 如果没有主键也没有合适的唯一索引,那么InnoDB内部会生成一个隐藏的主键作为聚集索引(6个字节的列)
【PS : 表必须有聚集索引,可以没有主键(唯一索引)】
【PS : MySQL的优化器会优先考虑走聚集索引】
【PS : 聚集索引的B+Tree的叶子结点存储的是整行的数据】
聚集索引图
非聚集索引分类
非聚集索引 : 普通索引(单列索引)常用、唯一索引(唯一性,不可重复)、覆盖索引常用、联合索引(多个列组合成的索引)优先推荐、前缀索引看场景、全文索引看场景都是非聚集索引.该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,单表中可以多个非聚集索引.
// 创建的单值索引
create index index_name(这里填写单值索引的名称) on table(col(列名));
如: create index idx_e on index_test(e);
// 创建的联合索引
create index index_name(这里填写联合索引的名称) on table(col(多个列名));
如:create index idx_bcd on index_test(b,c,d);
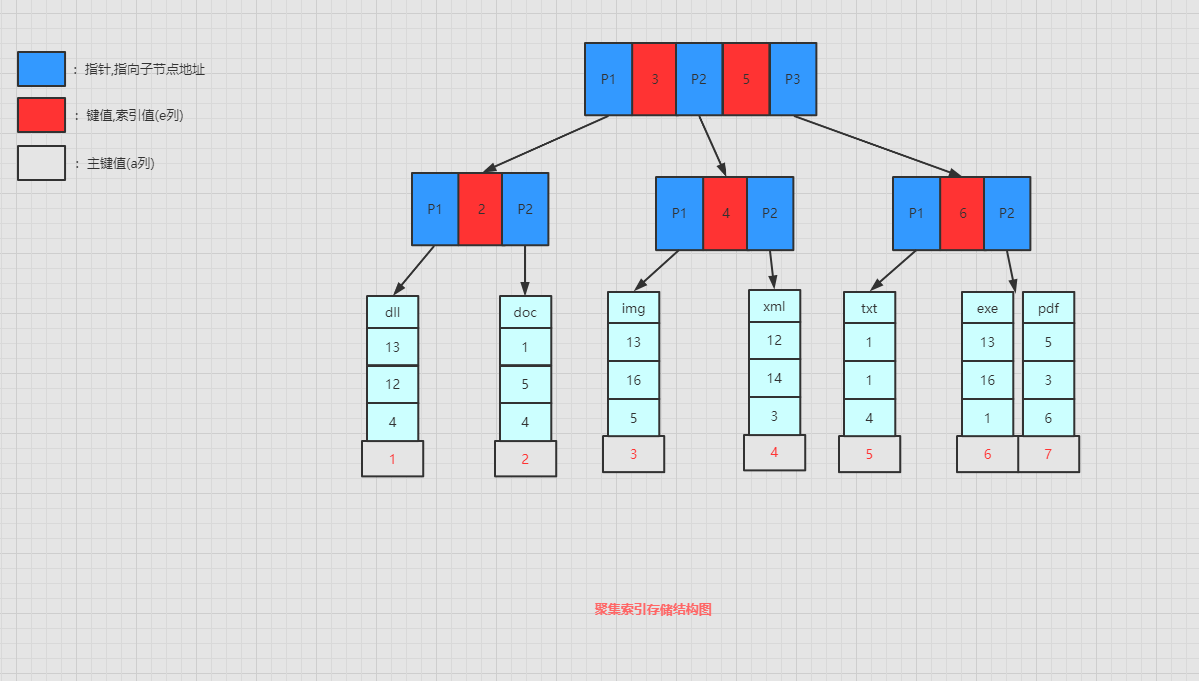
单值索引
单值索引 : 表示创建了一个只有一个列的索引.
index_test 表中的 列e 为单值索引,在存储引擎中存在这颗B+Tree:
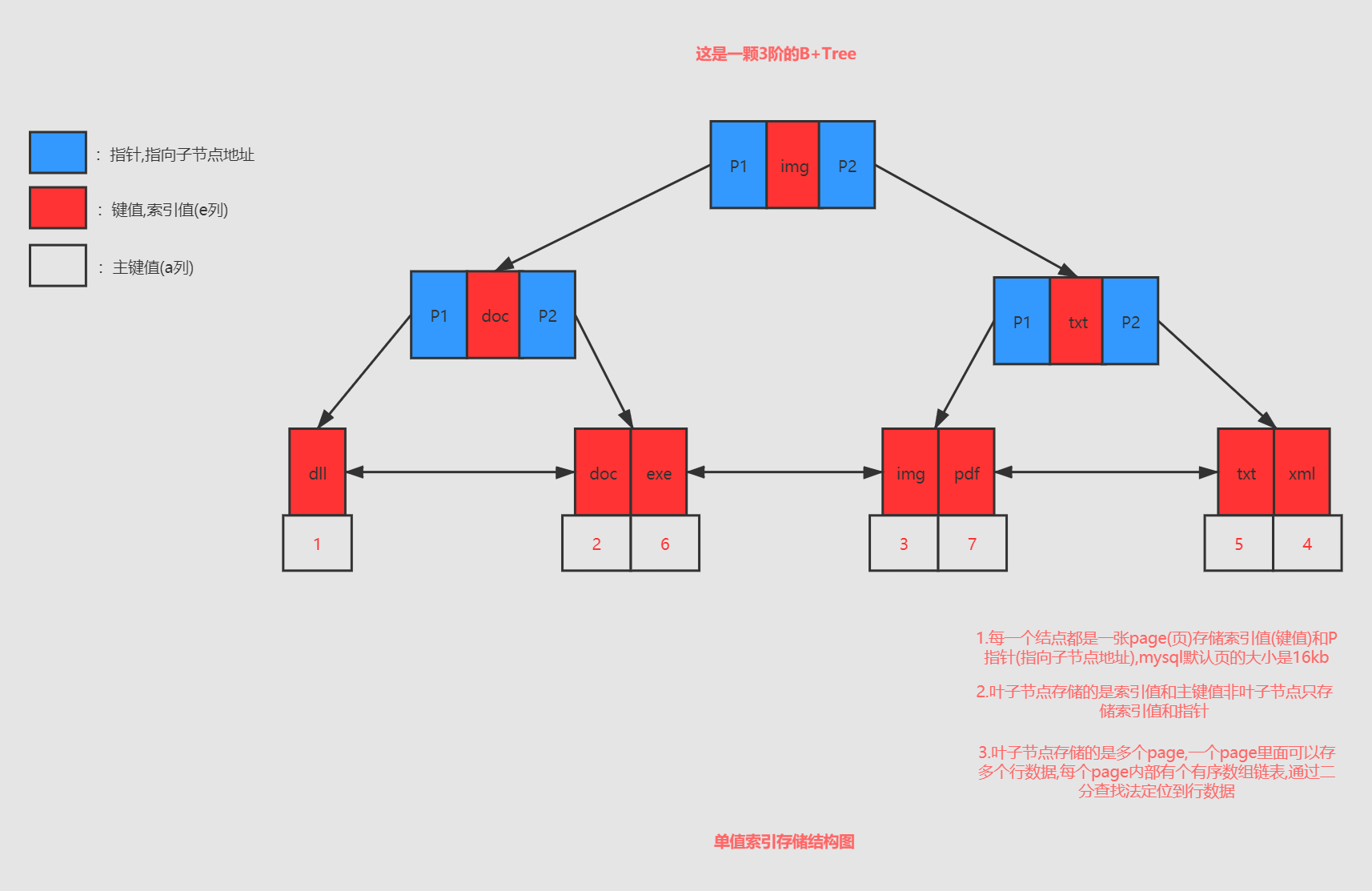
联合索引(本文核心)
联合索引:表示创建了多个列一起组合成一个索引的组合索引.
index_test 表中的 列b、列c、列d 为联合索引,在存储引擎中存在这颗B+Tree:
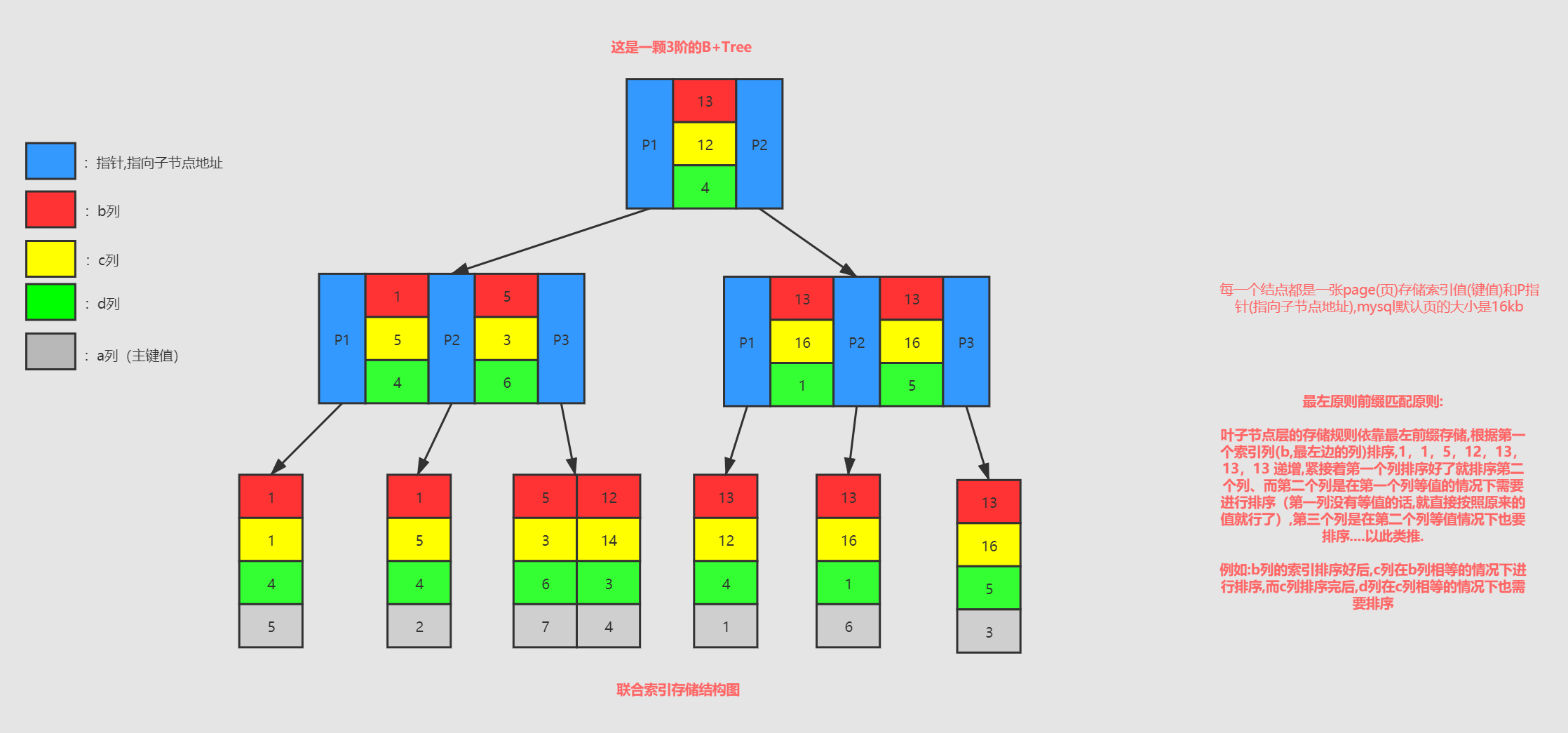
联合索引的存储规则是基于最左前缀原则.
最左前缀原则
叶子节点层的存储规则依靠最左前缀存储,根据第一个索引列(b,最左边的列)排序,1,1,5,12,13,13,13 递增,紧接着第一个列排序好了就排序第二个列、而第二个列是在第一个列等值的情况下需要进行排序(第一列没有等值的话,就直接按照原来的值就行了),第三个列是在第二个列等值情况下也要排序....以此类推.例如:b列的索引排序好后,c列在b列相等的情况下进行排序,而c列排序完后,d列在c列相等的情况下也需要排序.如图的page3的b列中的 1 和 page6的 13相对应的c列就需要排序,page6中c列的16 相对应的d列就需要排序.
最左前缀匹配原则 : 创建的联合索引,其实是创建了三个索引 (b) 、 (bc)、(bcd),所以假如你以 单列b 或者 联合bc 创建了索引,其实已经创建了重复索引,我们应该避免这种操作.
怎么样的查询才会走单值索引或者联合索引?
// 查询条件(where) 只存在 e列 条件,优化器会告诉执行器走 e列 单值索引.
select a,e from index_test i where i.e = 'pdf';
// 查询条件(where) 只存在 联合索引(b,c,d) 条件,优化器会告诉执行器走 (b,c,d)列 联合索引.
select a,b,c,d from index_test i where i.b = 13 and i.c > 5 order by i.c;
// 查询条件(where) 存在 单值索引(e列) 和 联合索引(b,c,d)列,优化器会智能的根据两个索引条件判断哪种索引过滤的数据较少而走哪种索引,例如走联合索引过滤 b = 13 符合这个条件的数据有三条,而 e = 'pdf' 这个条件只有一条符合条件的数据,所以优化器会告诉执行器走 e列 索引,然后再判断 b列条件.(这里是优化器的知识点,有更多的细节需要讲,本文暂不阐述)
select * from index_test i where i.b = 13 and i.e = 'pdf';
回表查询
我们知道非聚集索引的叶子结点只存储索引列的值和主键值,如果查询的时候走非聚集索引查询,且需要查询到其他列的信息,这个时候就需要根据拿到的主键值去再一次遍历聚集索引树,这种情况就是回表查询.而减少回表查询是我们优化查询的手段之一,解决回表查询的有效手段就是覆盖索引、联合索引等.
// 当前查询语句会走 e列 索引,但是b列信息需要回表查询才可以拿到.
select id,e,b from index_test i where i.e = 'pdf';
覆盖索引
// 以下的查询语句的查询的信息(主键值和索引列的信息)无需回表查询,
// 在这个查询里面,索引 e 已经"覆盖了"我们的查询需求,我们称为覆盖索引.
// 覆盖索引也是优化查询的有效手段之一.
select a,e from index_test i where i.e = 'pdf';
索引下推
// 当前查询语句将走联合索引
select a,b,c,d from index_test i where i.b = 13 and i.d = 5;
在 MySQL 5.6 之前,只能从第一条符合 b = 13 条件的数据 开始一个个回表查询,对聚集索引树上找出数据行,再过滤 d = 5 这个条件.
在 MySQL 5.6 引入 索引下推:可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数,提高查询优化.例如:从第一条符合 b = 13 条件的数据的时候,再过滤一下 d = 5 这个条件,而不需要去回表.
结束语
本文只是简单的了解下 单列索引\覆盖索引\联合索引\索引下推 ,单列索引\覆盖索引\联合索引\索引下推 都是常见的优化手段之一,合理的运用这些优化手段将有效的提高查询效率.