- 本文对源码的学习是基于JDK1.8版本.
- 对于我这几篇ConcurrentHashMap的文章,必须建立在学习过HashMap的源码基础之上.
前言
基于 并发容器:ConcurrentHashMap之putVal()源码分析(一) ,我们大致理解了ConcurrentHashMap的底层实现数据结构,并且对于添加元素、初始化table、根据key值获取value进行了源码分析.
一个容器在添加完元素之后需要统计元素的个数,其中addCount()函数就是添加完元素后对容器元素个数进行统计,而该函数并不处于synchronized锁住的临界资源之内,也就是说该函数是支持并发执行的,那么是如何做到的呢?本文将对该函数进行源码学习.
addCount()
两个作用 : 添加(统计)容器元素个数 、 检查是否达到了阈值而执行扩容操作.
addCount() --- 简化分析
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
1. 添加(统计)容器元素个数
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
......
}
2. 检查是否达到了阈值而执行扩容操作
if (check >= 0) {
......
}
}
函数的两个参数说明 :
- x : 添加了x个元素
- check : 检查是否需要扩容
添加容器元素个数
全局变量
// 在counterCells为null的情况下,是先通过这个变量来设置元素个数
private transient volatile long baseCount;
// 在并发较高的情况下,即出现多线程设置baseCount变量,则使用counterCells数组
private transient volatile CounterCell[] counterCells;
// 是否存在其他线程在使用counterCells数组对象
// 保证了多线程环境下只能一条线程使用counterCells数组对象
private transient volatile int cellsBusy;
CounterCell 对象 :
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
源码分析 --- 添加元素个数
CounterCell[] as; long b, s;
1. // 如果 counterCells 不为 null , 则 优先使用 CounterCell 对象来统计
// 如果 counterCells 为 null 则CAS 设置 baseCount变量就好了
// 如果CAS 设置 baseCount变量 失败了,出现并发情况,则通过 CounterCell 对象来统计
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
// 使用 CounterCell 对象来统计
CounterCell a; long v; int m;
boolean uncontended = true;
2. // 前两个条件是获取对应的counterCells数组为null的情况下
// 则需要执行初始化CounterCell[]对象,具体逻辑看 fullAddCount(),下文会分析
// 如果执行到第3个条件,说明counterCells数组不为null
// 则根据线程获取随机数和数组长度计算出数组索引值的CounterCell对象
// 如果该CounterCell对象为null,则需要创建CounterCell对象来统计,具体执行逻辑看 fullAddCount()
// 否则 第4个条件,CounterCell对象不为null,直接CAS设置该CounterCell对象的value值
// 如果CAS失败,则出现其他线程也在设置,那么执行 fullAddCount()
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
2.1 // 如果需要执行这个函数来统计元素个数
// 要么需要初始化 或者 较高的并发环境下可能需要对CounterCell数组扩容 或者 需要创建新的CounterCell对象来统计
// 这里也可以看出ConcurrentHashMap的元素个数并不准确的,尤其在较高的并发环境下
fullAddCount(x, uncontended);
// 所以暂时不执行下面检查扩容问题了,防止在较高的并发环境下多次扩容
return;
}
// 很幸运,上面基于CounterCell对象的value值进行CAS设置成功,
3. // check小于1,则表示暂时不检查需不需要扩容了(直接return)
// 例如在putVal()中没有哈希冲突的话check值为0、或者 remove操作中check值为-1
if (check <= 1)
return;
4. // 计算容器元素的个数,供下面检查是否达到阈值
s = sumCount();
}
函数的两个参数的具体说明 :
- x : 添加了x个元素
- check : 检查是否需要扩容,该值分为两种情况,如下 :
- 大于等于0 : 需要检查是否需要扩容
- 出现哈希冲突下,该值是大于等于2的,即出现哈希冲突的情况下,肯定会触发检查操作
- 没有出现哈希冲突的情况下,该值是等于0的,但不用执行fullAddCount()情况下也会检查是否需要扩容
- 小于等于0 : 无需检查是否需要扩容
- 没有出现哈希冲突的情况下,该值是等于0的,但在执行fullAddCount()情况下就直接return了
- 删除操作该值是等于-1,也不触发检查扩容操作
sumCount() --- 统计元素个数
结合baseCount变量 和 CounterCell数组对象进行统计.
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
fullAddCount()
在初始化CounterCell数组 或者 较高的并发环境下可能需要对CounterCell数组扩容 或者 需要创建新的CounterCell对象的时候,则需要执行fullAddCount()来添加元素个数.
该函数总共差不多80行代码,我分为三部分 :
- 第一部分 : counterCells不为null的情况下,即已经初始化过了,根据CounterCell对象来添加个数.这部分的代码量比较多,也是重点分析,涉及到CounterCell[]的扩容或者.
- 第二部分 : counterCells为null的情况下,需要初始化counterCells.这部分的代码比较简单.
- 第三部分 : counterCells为null的情况下,但是因为存在其他线程在初始化counterCells,所以还是通过CAS设置baseCount变量.这部分的代码也比较简单.
具体看看源码,如下分为三部分 :
// x : 添加x个元素
// wasUncontended : 是否重置当前线程随机数
private final void fullAddCount(long x, boolean wasUncontended) {
// ThreadLocalRandom.getProbe()) == 0时重新获取当前线程的随机数
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
// 判断counterCells是否需要扩容的一个标识
boolean collide = false;
// 自旋的方式添加元素个数
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
1. // 第一部分 : counterCells不为null
if ((as = counterCells) != null && (n = as.length) > 0) {
......
}
2. // 第二部分 : counterCells为null
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
......
}
3. // 第三部分 : counterCells为null,但是存在其他线程在初始化counterCells
// 通过 baseCount 变量来添加元素个数
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
......
}
}
第一部分 : counterCells不为null
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
// 是否需要扩容CounterCell[]的标识
boolean collide = false;
# 自旋的方式
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
#第一部分 counterCells不为null
if ((as = counterCells) != null && (n = as.length) > 0) {
1. // 根据随机数计算数组索引值,获取到相对应的CounterCell
// 该数组索引值位置并没有CounterCell,则创建CounterCell
if ((a = as[(n - 1) & h]) == null) {
1.1 // 判断一下操作CounterCell数组的权限
if (cellsBusy == 0) {
1.2 // 创建CounterCell对象
CounterCell r = new CounterCell(x);
1.3 // 获取操作CounterCell数组的权限
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
// 创建对象是否成功的标识
boolean created = false;
try {
1.4 // 把创建的CounterCell对象添加到CounterCell数组中
CounterCell[] rs; int m, j;
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
1.5 // 释放操作CounterCell数组的权限
cellsBusy = 0;
}
1.6 // 创建成功,跳出自旋
if (created)
break;
1.7 // 否则 重新自旋操作
continue;
}
}
// 有其他线程在操作CounterCell[]
// 执行 第7步骤 : 重置当前线程随机数,然后回到第1步骤重新执行
collide = false;
}
2. // 如果没有重置过当前线程随机数,则需要重置
else if (!wasUncontended)
2.1 // 执行 第7步骤 : 重置当前线程随机数,然后回到第1步骤重新执行
wasUncontended = true;
3. // 该数组索引值位置存在CounterCell,CAS设置该CounterCell的value值
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
4. // 第3步骤CAS设置失败,出现并发设置了,判断是否需要对CounterCell数组扩容
// 第一个条件表示 当前CounterCell数组发生变化
// 第二个条件表示 限制了CounterCell数组的长度,
// 即 CounterCell数组的长度已经达到了(大于等于)当前服务器的CPU处理器数量
else if (counterCells != as || n >= NCPU)
// 两个条件其中达到一个 : 不需要扩容,执行 第7步骤 : 重置当前线程随机数,然后回到第1步骤重新执行
collide = false;
5. // collide == false : 执行 第7步骤 : 重置当前线程随机数,然后回到第1步骤重新执行
// collide == true : 已经重置过了,执行第6步骤扩容
else if (!collide)
collide = true;
6. // 获取操作CounterCell数组的权限
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
// 成功获取到操作CounterCell数组的权限
try {
if (counterCells == as) {
6.1 // 扩大到原来的两倍
CounterCell[] rs = new CounterCell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
counterCells = rs;
}
} finally {
6.2 // 释放操作权限
cellsBusy = 0;
}
collide = false;
6.3 // 自旋重新添加个数
continue;
}
// 第2、4、5、6步骤的判断条件如果为true,
// 则需要重置当前线程随机数,然后重新自旋
7. // 重置当前线程随机数
h = ThreadLocalRandom.advanceProbe(h);
}
else if {
#第二部分 初始化 counterCells
......
}
else if {
#第三部分 通过baseCount添加元素个数
......
}
}
小结
- 第一部分 : counterCells不为null
- ① : 根据随机数计算数组索引值,获取到相对应的CounterCell,该数组索引值位置并没有CounterCell,则创建CounterCell :
- 1.1 ~ 1.3 : 判断并获取操作CounterCell数组的权限,并且创建CounterCell对象
- 1.4 : 把创建的CounterCell对象添加到CounterCell数组中
- 1.5 : 释放操作CounterCell数组的权限
- 1.6 : 创建成功,跳出自旋
- 1.7 : 否则 重新自旋操作
- ② : 判断是否有重置当前线程随机数,如果没有,则执行 第7步骤 : 重置当前线程随机数,然后回到第1步骤重新执行
- ③ : 该数组索引值位置存在CounterCell,CAS设置该CounterCell的value值
- ④ : 第3步骤CAS设置失败,出现并发设置了,判断是否需要对CounterCell数组扩容 :
- counterCells != as : counterCells发生变化.
- n >= NCPU : CounterCell数组的长度已经达到了(大于等于)当前服务器的CPU处理器数量
- 限制CounterCell数组的容量
- 两个条件其中一个条件满足,则不需要扩容,执行 第7步骤 : 重置当前线程随机数,然后回到第1步骤重新执行
- ⑤ : 是否对CounterCell数组的扩容基于第④步骤 :
- collide == false 表示暂不需要扩容,则执行 第7步骤 : 重置当前线程随机数,然后回到第1步骤重新执行
- collide == true 则执行第6步骤
- ⑥ : 判断并获取操作CounterCell数组的权限
- 6.1 : CounterCell数组扩大到原来的两倍
- 6.2 : 释放操作权限
- ⑦ : 重置当前线程随机数.
第二部分 : counterCells为null,需要初始化CounterCell数组
// counterCells为null
// 尝试获取操作 counterCells 的权限
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
// 是否初始化成功标识
boolean init = false;
try {
if (counterCells == as) {
1. // 初始化长度为2的CounterCell[]
CounterCell[] rs = new CounterCell[2];
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
2. 释放操作CounterCell[]的权限
cellsBusy = 0;
}
// 初始化完成,跳出自旋循环
if (init)
break;
}
第三部分 : counterCells为null的情况下,但是因为存在其他线程在初始化counterCells,所以通过CAS设置baseCount变量
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break;
总结
- ConcurrentHashMap的元素个数统计是基于baseCount 和 counterCells来统计,具体可以看看sumCount();同时也支持多线程添加元素个数,具体可以看看fullAddCount().
- ConcurrentHashMap的获取元素个数(size())并不是准确的,尤其在高并发putVal()的情况下.
- ThreadLocalRandom.getProbe()解决了Random在高并发环境下获取随机数性能问题.
- counterCells 默认初始化长度为2,并且最大长度为服务器的CPU处理器数量.
检查是否扩容
全局变量
# PS : putVal()文章中没说明该变量为负数(除了-1)时是处于什么状态
// -1 : 正在初始化状态
// 其他负数 : 正在扩容状态
private transient volatile int sizeCtl;
// 32位的一半,即低16位
private static int RESIZE_STAMP_BITS = 16;
// 2的16次幂 65535
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 32bit的一半,即高16位
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// 当触发扩容的时候,旧数组的数据会迁移到新数组(nextTable)
private transient volatile Node<K,V>[] nextTable;
// 多线程并发分配资源的时候的一个值
// 主要用来协调多个线程,并发安全地给多个线程分配资源
private transient volatile int transferIndex;
源码分析 --- 检查是否扩容
// check值上面的知识点有分析了
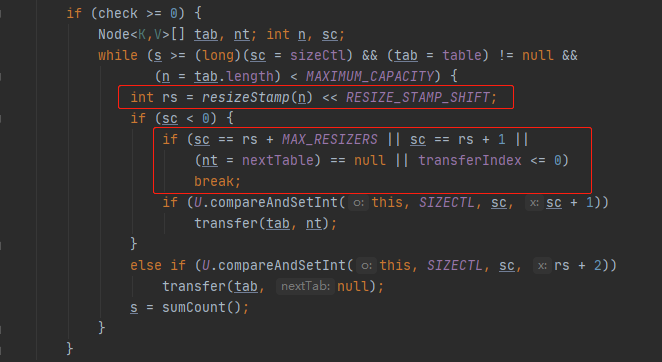
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
1. // sizeCtl为阈值 赋值给sc s为当前容器的元素个数
// 判断s是否大于等于阈值(sc) (元素个数达到了阈值)
// 并且 table不为null
// 并且 table的长度没超过最大值(MAXIMUM_CAPACITY)
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
2. // 该函数根据当前数组长度生成一个16位的值,该值的范围总是在 :
// 1000000000 000001 ~ 1000000000 011110
// 具体下文会详细分析,这里我们称它为
// 基于旧数组长度生成的一个扩容标记(扩容标识位)
int rs = resizeStamp(n);
// 以下步骤可以先看下面的分析再回来看
3. // sizeCtl < 0
// 回忆第一篇文章这个变量可以代表着不同状态,其中小于0这种状态(除了-1)没有说明
// 当小于0时,代表着正在扩容状态
if (sc < 0) {
3.1 文字幅度较大,解析写在下面
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
3.2 // sizeCtl + 1 ,表示参与扩容的线程数量+1
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
3.2 // 执行扩容函数,会独立一篇文章
transfer(tab, nt);
}
4. // sizeCtl > 0 : 表示当前没有线程在扩容,初始化sizeCtl为 :
// (rs << RESIZE_STAMP_SHIFT) + 2
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 执行扩容函数
transfer(tab, null);
5. 重新统计元素个数
s = sumCount();
}
}
resizeStamp()及判断条件
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
// 二分查找,查找最高位1
public static int numberOfLeadingZeros(int i) {
if (i == 0)
return 32;
int n = 1;
if (i >>> 16 == 0) { n += 16; i <<= 16; }
if (i >>> 24 == 0) { n += 8; i <<= 8; }
if (i >>> 28 == 0) { n += 4; i <<= 4; }
if (i >>> 30 == 0) { n += 2; i <<= 2; }
n -= i >>> 31;
return n;
}
- Integer.numberOfLeadingZeros(n) : 计算数组长度(二进制)的最高位1在32位bit处于哪个位置,例如默认数组长度是16,二进制为 : 10000 , 最高位1是在第5位,但是第5位是基于从右边计算,而该函数是从左边计算,即返回的是27;
- 由于数组的长度最小为2、最大为1 << 30,即【2的1次幂 ~ 2的30次幂】,所以numberOfLeadingZeros()返回的值的范围在 【1 ~ 30】,即 【000001 ~ 011110】
- (1 << (RESIZE_STAMP_BITS - 1)) : RESIZE_STAMP_BITS等于16,是32bit位的一半,该式子最终是 (1 << 15),即 1左移15位 ,得到的结果就是 1000 0000 0000 0000 , 是16bit位二进制.
- 两者做 | 运算 即resizeStamp()得到的范围 : 【1000000000 000001 ~ 1000000000 011110】,可以总结为 resizeStamp()返回的是一个二进制为10000000000 XXXXXX(占16bit位)的数字,这个16bit位是一个数组扩容标识位,即每次扩容,基于数组长度的不同会产生不同的标识位.
现在明白了resizeStamp()返回的是一个基于数组长度生成的10000000000 XXXXXX(占16bit位)的标识位,再来看看三个步骤的判断 : 3.1 \ 3.2 \ 4 : 先说 第4步骤的判断,再结合resizeStamp(),3.1 \ 3.2 基本就可以看明白了.
- 第4步骤 : 走到这一步判断,可以肯定的是当前线程是第一条线程(即sizeCtl > 0)执行扩容操作,则将 sizeCtl 初始化为 (rs << RESIZE_STAMP_SHIFT) + 2,告诉其他线程,当前处于正在扩容阶段;10000000000 XXXXXX左移16位,即把10000000000 XXXXXX放在高16位,而低位 + 2,如下图 : 一目了然,这是一个负数,此时你看看第3步骤,就明白了小于0时是处于扩容阶段的.
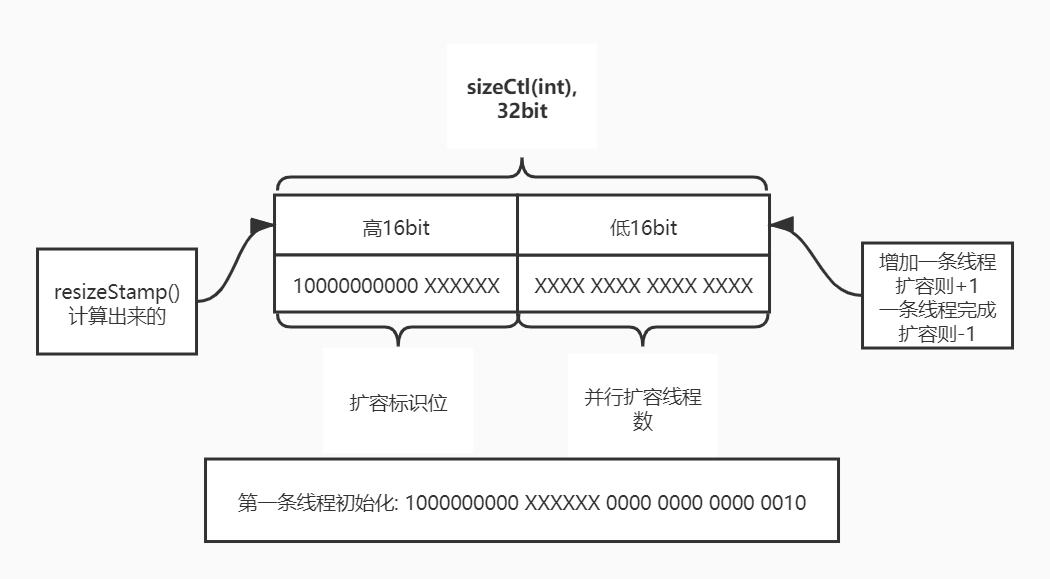
- 第3.1步骤 : 总共5个判断条件,前3个判断跟sizeCtl有关
- (sc >>> RESIZE_STAMP_SHIFT) != rs : 结合上面的知识点,可以知道 sc >>> RESIZE_STAMP_SHIFT 是 取sizeCtl的高16位,即rs数组扩容标识位;如果两个不相等,则表示并不是基于同一个旧的数组扩容,那么当前线程是不能执行扩容操作的;该判断条件保证所有线程要基于同一个旧的数组进行扩容.
- sc == rs + 1 : 第一个条件返回false,说明还是同一个扩容标识位(即对同一个旧数组扩容),则判断第二个条件;这个条件是JDK1.8的一个Bug,正确的写法应该是 : sc == (rs << RESIZE_STAMP_SHIFT) + 1 ,代表着当前扩容的线程数为0,即已经扩容完成了,就不需要再新增线程扩容.
- sc == rs + MAX_RESIZERS : 第二个条件返回false,说明当前存在线程在扩容,则判断第三个条件;这个条件也是JDK1.8的一个Bug,正确的写法应该是 : sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS , 代表着当前扩容线程数最大只能同时达到MAX_RESIZERS(65535).
- (nt = nextTable) == null : 表示扩容结束了
- transferIndex <= 0 : 表示当前数组不需要其他线程帮忙扩容了
上面五个条件只要一个条件为true,则不执行扩容操作.否则执行第3.2步骤通过CAS设置sizeCtl+1,表示多加一条线程执行扩容操作.
【PS : 相关Bug连接 : JDK8 ConcurrentHashMap的Bug集锦】
【PS : 第一个线程尝试扩容的时候,为什么是+2 : 因为1表示初始化,2表示一个线程在执行扩容,而且对sizeCtl的操作都是基于位运算的,所以不会关心它本身的数值是多少,只关心它在二进制上的数值,而sc+1会在低16位上加1】
特意下载了JDK12源码 :
小结
sizeCtl小于0时(除了-1),sizeCtl会被分为高低16位,高16位是数组扩容标识位、低16位是并行扩容线程数.
总结
- 本文核心是addCount(),该函数总体分为两大部分 : 添加元素个数 和 检查是否扩容.
- 添加元素个数 : 核心是通过CounterCell数组 和 baseCount变量 来多线程统计.
- 检查是否扩容 : 当前容器需要扩容时,即容器元素个数大于等于阈值,并且也是支持多线程扩容的,那么如何判断此时存在其他线程正在扩容呢 : 当sizeCtl小于0时(除非-1),那么此时此刻就是正在扩容阶段;sizeCtl被拆分为 高16位 和 低16位 , 高16位是数组扩容标识位、低16位是并行扩容线程数.
- 结合第一篇文章,再对 sizeCtl 不同状态做一次总结 :
- sizeCtl = 0 : 没有初始化状态
- sizeCtl >0 : 表示通过构造器的初始容量或者正常状态下的扩容阈值(0.75f)
- sizeCtl <0 :
- -1 : 当前存在一条线程正在初始化
- (resizeStamp(n) << RESIZE_STAMP_SHIFT) + 2 : 表示此时只有一个线程在执行扩容
- 其他负数 : 当前处于扩容中状态
结束语
- 原创不易
- 希望看完这篇文章的你有所收获!
- 扩容函数transfer()请跳转
相关参考资料
- JDK1.8