这篇文章B-Tree、B+Tree简单介绍了B树是如何演变而来,本文将深入理解B树这种数据结构.
B树
B树是为磁盘或其他直接存取的辅助存储设备而设计的一种平衡搜索树,B树的主要作用就是降低磁盘IO次数,这就是许多数据库系统使用B树或B树的变种(B+Tree)来存储信息的原因.
- B树算法将所需的页面(数据页)从磁盘复制到内存(Buffer Pool),然后将内存中(Buffer Pool)修改过的页面(缓存页)写回磁盘
- 一个B树结点通常就是一个数据页的大小 【PS : 数据页的大小会限制了B树结点可以含有多少个键值(key)】
- B树的分支因子 : 分支因子的大小取决于一个数据页可以存放多少个关键字(key)【PS : 一个大的分支因子可以大大降低树的高度,从而降低磁盘IO次数;磁盘IO次数与树的高度是成正比的】
B树的特性
【PS : B树的变种 : B+Tree,非叶子结点只存放关键字(key)和 孩子指针 , 而叶子结点会存储整行相关联的数据,对于非叶子结点只存放关键字和孩子指针,可以最大化分支因子(每个数据页可以存储更多的键值)】
【PS : InnoDB存储引擎的聚集索引的叶子结点存储的是整行数据,辅助索引存储的是键值+主键ID】
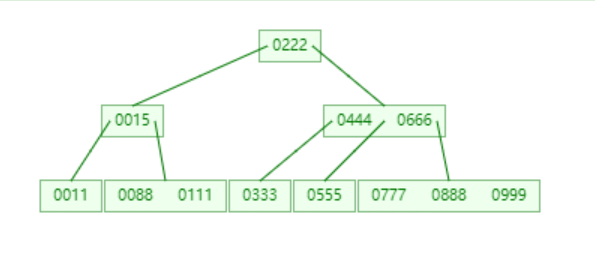 B-TREE
B-TREE
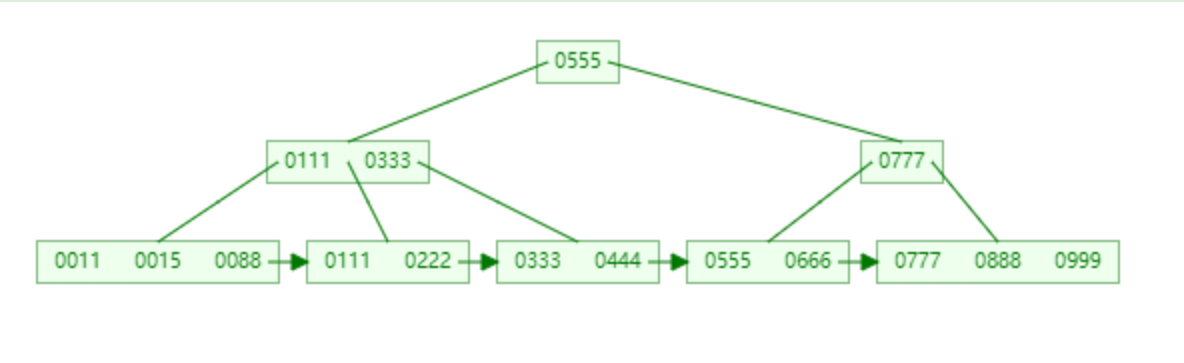 B+TREE
B+TREE
B树的特性 :
- 每个结点都包含以下属性 :
- (a) n : 关键字(key)个数,并且以升序的排列方式存放(单向链表)【PS : key(1) <= key(2) <= key(3) ... <= key(n) , 查找方式 : 二分查找】
- (b) leaf : 布尔值,叶子结点 : TRUE , 非叶子结点 : FALSE
- 每个非叶子结点包含了 (n + 1) 指向其孩子的指针, c(1) \ c(2) \ c(3) ... \ c(n+1)【PS : 叶子结点没有孩子,所以没有c属性的定义】
- 每个叶子结点具有相同的高度,即树的高度(h)【叶子结点在最低端,代表了树的高度】
- 所有结点的关键字有上界和下界(范围限制),用一个被称为B树的最小度数的固定整数 (t >= 2) 来表示这个界【PS : 每个结点的关键字有个范围控制(t >= 2)】
- (a) 除了根结点(root)以外,每个结点必须至少有 (t-1) 个关键字 、每个结点必须至少有 t 个孩子; 如果树为非空,根结点至少有一个关键字
- (b) 每个结点最多可包含 (2t-1) 个关键字,每个非叶子结点最多有 2t 个孩子【PS : 当一个结点中有 (2t-1) 个关键字,代表该结点是满的】
【PS : t = 2 时,每个非叶子结点有 2个 \ 3个 \ 4个孩子,即是一颗2-3-4树,但是,t值越大,树的高度越小,磁盘IO次数则越少】- 一个结点等于一个数据页,每检查一个结点代表一次磁盘IO访问,所以B树的高度越低,则可以更大的避免大量的磁盘IO操作.
- 小结 :
- 根节点(root),如果树为非空,根结点至少有一个关键字
- 非叶子结点,由关键字(key)、孩子指针(c)、是否叶子节点(leaf) 组成,leaf为 FALSE;【对于B-Tree,多了个value值】
- 叶子结点,由关键字(key)、是否叶子节点(leaf) 组成,leaf为 TRUE;
- 无论是非叶子结点还是叶子节点,结点中的关键字是以升序方式存放在链表中;对于结点,如果存在n个关键字,则有(n + 1)个孩子指针, 并且需要满足 :
t >= 2 : 每个结点的关键字有个范围控制
关键词控制范围 : (t - 1) <= n <= (2t - 1) 【树为null,root的关键字为0】
孩子指针控制范围 : t <= (n+1) <= 2t 【叶子结点没有孩子指针】
B-Tree的基本操作
查询操作 ---- B-TREE-SEARCH
【PS : 查询一颗B-Tree和搜索一颗二叉搜索树不相同,B-Tree的查询是对每个结点所做的并不是"二叉"或者"两路"查找,而是根据该结点的孩子指针数的"多路"分支查找,例如对一个结点x做的一个(x,n+1)的多路查找】
 B-TREE-SEARCH[算法导论中提供的伪代码]
B-TREE-SEARCH[算法导论中提供的伪代码]
每个结点的数据是单向链表连接起来的,所以对于该结点的查询,是一个线性查询,接下来解析伪代码的各行代码的执行作用 : 【PS : x 代表当前结点;k 代表需要查找的key值;DISK-READ(x,c(i)) 代表去磁盘读取 x 结点的 c(i) 孩子结点】
- 第1 ~ 3 行 : 每个结点的数据是单向链表连接起来的,且key值是升序方式存放,所以这里是遍历比较当前n个key中,如果 k <= key(i),就是在当前结点找到关键字k,如果没找到,则 i = n+1 (i是从1开始遍历) 【PS : key值是升序方式存放,这里是有用到二分查找算法的】
- 第4 ~ 5 行 : 检查是否找到关键字k,如果找到,则直接返回;否则,执行第6 ~ 7 行
- 第6 ~ 7 行 : 如果是叶子结点,则返回NULL,否则,执行第8 ~ 9 行
- 第8 ~ 9 行 : 上面的第4 ~ 7 行 已经排除到当前结点找不到关键字k 且不是 叶子结点, 所以需要从磁盘中找到 x 结点的孩子结点(c(i))载入内存中,然后以此结点继续执行B-TREE-SEARCH函数.
创建一颗空的B树 ---- B-TREE-CREATE
构造一颗B树,需要使用B-TREE-CREATE函数来创建一个空的根节点,创建一个结点需要一个磁盘页,是由ALLOCATE-NODE函数来完成的,B-TREE-CREATE函数伪代码如下 :
 B-TREE-CREATE[算法导论中提供的伪代码]
B-TREE-CREATE[算法导论中提供的伪代码]
- 第 1 行 : ALLOCATE-NODE函数创建了一个结点【PS : 在内存中创建】
- 第 2 行 : 表示该结点为叶子结点
- 第 3 行 : 表示该结点的关键字数 n 为 0
- 第 4 行 : 写到磁盘中
- 第 5 行 : 赋值为root结点
【PS : B-TREE-CREATE只需要O(1)次的磁盘操作和O(1)的CPU时间】
向B树中插入一个关键字 ---- B-TREE-SPLIT-CHILD \ B-TREE-INSERT
二叉搜索树插入一个结点,只需要定位该结点的插入位置就行,而B树插入一个关键字,并不是简单的定位一个新的结点,而是插入到一个已经存在的结点(数据页);但是如果将关键字插入到一个满的结点中(一个满的结点含有 (2t-1) 个关键字),这个时候则需要进行"分裂"操作,"分裂"为两个各含 (t-1) 个关键字的结点,中间结点被提到父节点中,来表示两个新结点的划分点.
【PS : 当插入的结点为 (2t-1) 个关键字的时候, 就需要分裂操作, 分裂操作就是把该结点分裂为两个新的结点,怎么分裂 : (2t-1) 总是奇数的,取中间数作为两个新结点的划分点,并且把中间数移到父节点中,然后以中间数为中心分裂为两个 (t-1)个 的新结点,分裂完后再把关键字插入到新分裂的两个结点中的一个】
如下图 : 插入666,对于666插入的位置是在存储222结点的右结点c2中,需要把c2分裂成两个新节点(两个新结点分别是存放关键字333的结点z、和存放关键字555的结点y),把中间数444移到父结点c2中,然后把666插入到结点y中.
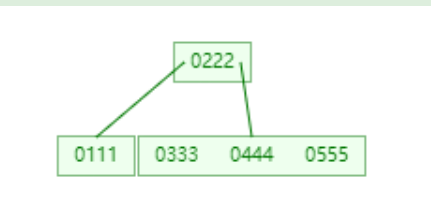 分裂前(B-Tree)
分裂前(B-Tree)
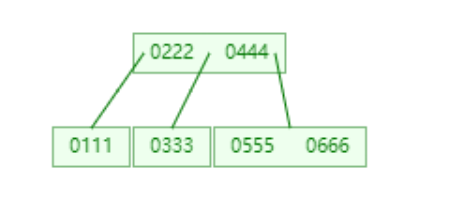 分裂前(B-Tree)
分裂前(B-Tree)
【PS : B树的插入关键字过程并不是插入该结点后的关键字满了就立即分裂,而是沿着树往下查找关键字插入位置的时候,会分裂沿途遇到的每一个满结点(包括叶子结点),这样做的目的可以确保在分裂的满结点的父结点不是满的】
分裂B树中的结点 ---- B-TREE-SPLIT-CHILD
B-TREE-SPLIT-CHILD(x,i)函数是指对一个非满的非叶子结点x和一个x.c(i)为x的满孩子结点i,该过程把满结点x.c(i)分裂成两个结点,并且调整父结点(x).
【PS : 对于分裂的结点是根节点,树的高度会增加1,分裂根节点是树长高的唯一途径】
B-TREE-SPLIT-CHILD函数伪代码如下 :
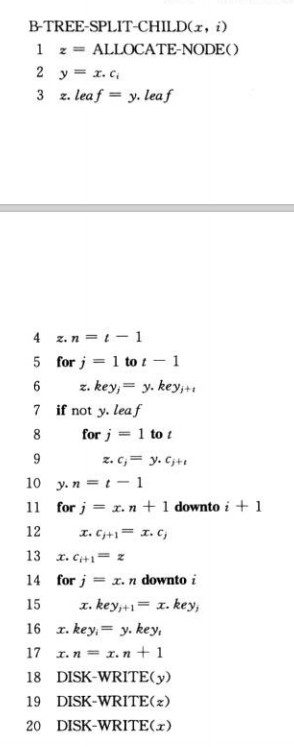 B-TREE-SPLIT-CHILD[算法导论中提供的伪代码]
B-TREE-SPLIT-CHILD[算法导论中提供的伪代码]
- 第 1 行 : ALLOCATE-NODE函数创建了一个新结点【PS : 在内存中创建】
- 第 2 行 : 把需要分裂的满结点x.c(i)赋值给y结点
- 第 3 行 : y结点是需要分裂的满结点(分裂成两个),z结点是分裂后的另一个新结点,所以y、z结点的leaf是一样的
- 第 4 行 : 初始化z结点的关键字数 (t-1)
- 第 5 ~ 6 行 : 把满结点y中 的 (t - 1) 个 key给 z结点
- 第 7 ~ 8 行 : 如果是非叶子结点,y结点相对应的孩子指针也需要给z结点
- 第 10 行 : 重新初始化y结点的关键字 由原来的 (2t - 1)个 变为 (t - 1) 个
- 第 11 ~ 13 行 : 将新结点z插入为x结点的孩子结点
- 第 14 ~ 17 行 : 将y结点的中间关键字提升到x结点来分隔y、z结点,并且调整x结点的关键字数(加1)
- 第 18 ~ 20 行 : 分别把x、y、z结点写入磁盘中
【PS : B-TREE-SPLIT-CHILD函数的分裂过程中的第 5~6 行 、 第 7~8 行代码,两个循环把y结点的 (t-1)个关键字 和 相对应的t个孩子结点(非叶子结点) 分配给新结点z,占用的CPU时间会比较多】
插入B树中的关键字 ---- B-TREE-INSERT
【PS : 对于一颗高度为H的B+Tree,沿着根结点(root)单程往下插入一个关键字k的操作需要O(H)次磁盘存取】
【PS : B-TREE-INSERT函数的插入关键字在B-TREE-SPLIT-CHILD函数中,保证了其分裂的父结点并不是满的】
B-TREE-INSERT函数伪代码如下 :
 B-TREE-INSERT[算法导论中提供的伪代码]
B-TREE-INSERT[算法导论中提供的伪代码]
- 第 1 行 : 获取根结点(root)
- 第 2 行 : 判断当前结点是否为满结点,如果是,则执行第 3~9 行代码
- 第 3 行 : 创建一个新结点s
- 第 4 行 : 新结点s赋值给根结点
- 第 5 行 : 新结点s为非叶子结点
- 第 6 行 : 新结点s的关键字n为0
- 第 7 行 : 此时s结点的第一个孩子节点(c1) 就是原来的满结点r
- 第 8 行 : 开始对结点s的孩子满结点r进行分裂(图中第二个参数的l是r)
- 第 9 行 : 执行B-TREE-INSERT-NONFULL(s,k) 函数
- 第 10 行 : 当前根结点不是满结点,执行B-TREE-INSERT-NONFULL(r,k) 函数插入到当前根结点中
【PS : 对根结点的分裂是增加B树高度的唯一途径,B树的高度的增加是在顶部,而二叉搜索树是在底部】
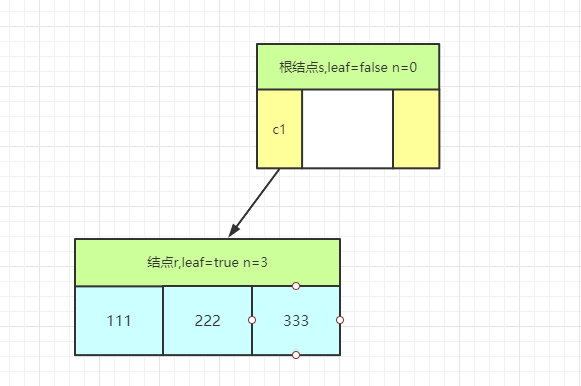 第 1~7 行代码(B-Tree)
第 1~7 行代码(B-Tree)
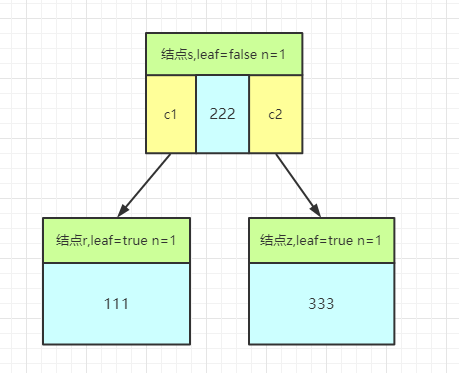 第 8 行代码(B-Tree)
第 8 行代码(B-Tree)
接下来看看 第 9 行 执行代码中的B-TREE-INSERT-NONFULL函数,B-TREE-INSERT-NONFULL函数伪代码如下 :
 B-TREE-INSERT-NONFULL[算法导论中提供的伪代码]
B-TREE-INSERT-NONFULL[算法导论中提供的伪代码]
B-TREE-INSERT-NONFULL是一个递归函数,并且调用B-TREE-INSERT-NONFULL(x,k)函数之前已经保证了插入x结点是非满结点.
【PS : B-TREE-INSERT 和 B-TREE-INSERT-NONFULL 保证了插入的s结点是非满的】
- 第 1 行 : 获取当前结点的关键字数 n
- 第 2 行 : 判断当前结点是否叶子结点,如果是,则执行 第 3~8 行代码,否则,则执行 第 9~17行代码
- 第 3 ~ 7 行 : 把关键字k插入到结点x中,也就是插入到叶子结点中
- 第 8 行 : 把结点x刷入到磁盘中
- 第 9 ~ 11 行 : 结点x是一个非叶子结点,需要根据x结点向下找孩子结点x.c(i)
- 第 12 行 : 对结点x.c(i)从磁盘读取到内存中
- 第 13 行 : 判断结点x.c(i)是否一个满的结点,如果是,则执行第 14 行代码,否则执行第 15~16 行 代码
- 第 14 行 : 对结点x.c(i)进行分裂,这里分裂完以后继续执行 第 15 ~ 16 行 代码
- 第 15 ~ 16 行 : 同 第 9 ~ 11 行 代码的含义是一样的,需要继续往下找,此时找到的结点x.c(i)(i重新计算了)
- 第 17 行 : 对x.c(i)结点执行B-TREE-INSERT-NONFULL
【PS : 对一颗高度H的B树来说,B-TREE-INSERT要做O(H)次磁盘存取,插入的关键字最终会存储到叶子结点中】
执行B-TREE-INSERT-NONFULL流程图
 (1)初始化一颗B-Tree
(1)初始化一颗B-Tree
 (2)插入关键字235
(2)插入关键字235
 (3)插入关键字2021
(3)插入关键字2021
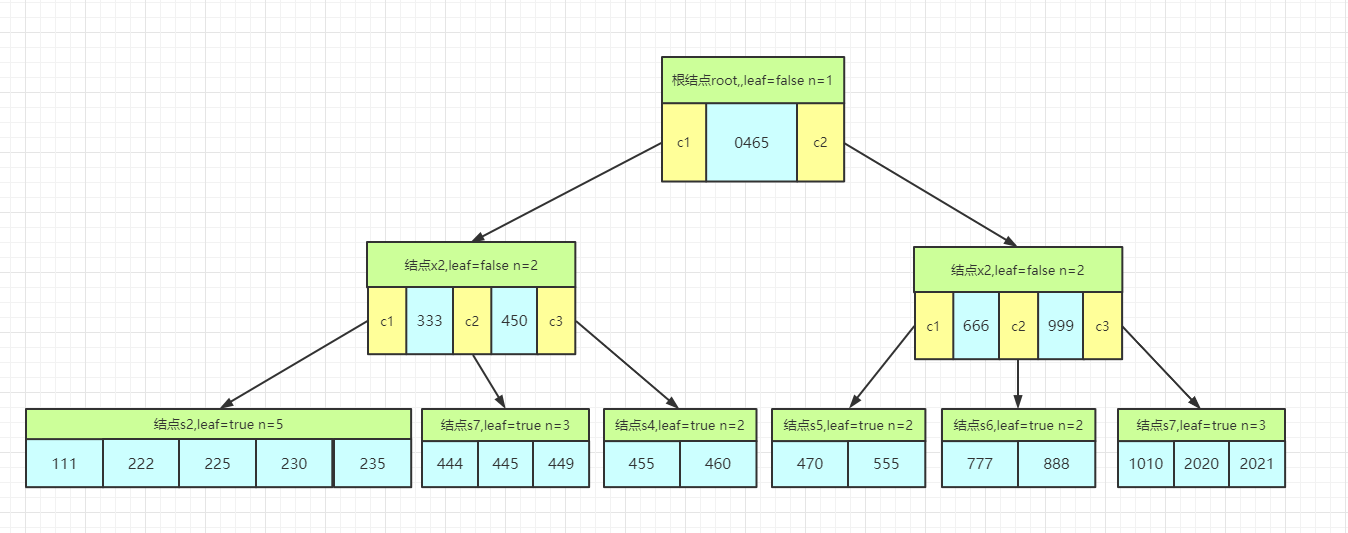 (4)插入关键字449
(4)插入关键字449
 (5)插入关键字88
(5)插入关键字88
上面的执行流程 : 向B树插入关键字,这颗B树的最小度数t = 3,所以一个结点最多关键字数为5个.
- (1)初始化一棵B树
- (2)插入关键字235,由于插入过程无需分裂,所以这是一个简单的叶子结点插入过程
- (3)插入关键字2021,root结点的最右结点的关键字等于5,需要先分裂,把关键字999作为分隔提升到父节点中,并且分裂出两个新的结点
- (4)插入关键字449,root为满结点,需要分裂,树的高度加1;(5)插入关键字88,叶节点需要分裂,分裂操作同(3).
向B树中删除一个关键字 ---- B-TREE-DELETE
B树上删除一个关键字,必须防止删除操作而导致违反B树的特性.B树的插入操作必须保证一个结点不会因为插入而变得太大,而删除操作必须保证一个结点不会因为删除而变得太小(跟结点除外,root可为空,一棵空树).
【PS : 一个插入操作,如果插入关键字的沿途中有满结点,需要向上回溯,同样的,一个删除操作,当要删除的关键字的沿途中结点(根结点除外),有最少个关键字个数时(t-1),也可能要回溯】B树中删除关键字的各种情况 :
- 如果关键字k在结点x中,x为叶子结点,直接从x结点中删除关键字k
- 如果关键字k在结点x中,x为非叶子结点,那么则需要考虑这几种情况 :
- (a). 找到结点x中的关键字k的左右孩子指针的左指针c(l),通过c(l)找到其孩子结点x(c[l]),判断x(c[l])的关键字个数是否至少包含t个(不能小于 t 个),如果符合这个条件,则把x(c[l])中最大的关键字(最右边)代替被删除的关键字k的位置;否则,如果x(c[l])的关键字个数小于 t 个 ,则执行下面b情况
- (b). 找到结点x中的关键字k的左右孩子指针右指针c(r),通过c(r)找到其孩子结点x(c[r]),判断x(c[r])的关键字个数是否至少包含t个(不能小于 t 个),如果符合这个条件,则把不能小于 t 个中最小的关键字(最左边)代替被删除的关键字k的位置;否则,如果x(c[r])的关键字个数小于 t ,这个时候说明 被删除关键字k的左右孩子结点 x(c[l]) 、 x(c[r]) 的关键字个数都是小于 t个,那么将执行下面 c情况 :
- (c). 关键字k的左右孩子结点 x(c[l]) 、 x(c[r]) 的关键字个数都是小于 t个,此时将关键字k和结点x(c[r])的所有关键字合并进结点x(c[l]),这样结点x就失去了关键字k和结点x(c[r]),并且结点x(c[l])此时含有 2t - 1 个关键字,然后释放结点x(c[r])并且从结点x(c[l])中删除关键字k.
- 如果需要删除的关键字k并不在当前访问到的结点x之中,我们需要以下两个步骤来保证子树的根至少含有t个关键字【PS : 这种保证子树中关键字不能少于t个的情况,跟插入操作沿途发现结点为满结点就分裂,保证父结点不为满结点(2t-1)是差不多一个道理】
- (a). 如果结点x的孩子节点(x.c(i))只有t-1个关键字,但他的相邻兄弟结点含有至少t个关键字(左右相邻的兄弟结点中只要有一个至少t个关键字),则将结点x中的一个关键字降至x.c(i)的关键字中,并且同时在相邻的兄弟子树节点的之中将一个关键字提升到结点x的关键字中,在进行删除
- (b). 如果结点x的孩子节点(x.c(i))只有t-1个关键字,并且他的所有相邻兄弟结点也是只含有至少t-1个关键字,则将其中一个相邻兄弟结点合并成一个新的结点y,并且将结点x的一个关键字降至y结点作为y结点的中间关键字,在进行删除
- 如果删除的关键字k在叶子结点x.c(i)中(父结点x),如果叶子结点x.c(i)的关键字个数 为 t-1,结点x的x.k(i)关键字 在 x.c(i) 与 x.c(i+1)之间,存在以下两种情况 :
- (a). 如果叶子结点x.c(i)的右邻叶子结点x.c(i+1)的关键字个数不小于t个,则把结点x的x.k(i)关键字降至结点x.c(i)的关键字中最右边,结点x.c(i+1)的最左边关键字提升至结点x的x.k(i)关键字的位置,最后删除关键字k
- (b). 如果叶子节点x.c(i)的右邻叶子结点x.c(i+1)的关键字个数等于t-1个,也就是叶子结点x.c(i) 和 右邻叶子结点x.c(i+1)的关键字个数都是 t-1 个,此时把结点x的x.k(i)关键字降至到结点x.c(i)的关键字中最右边,然后与x.c(i+1)合并成新节点y,最后删除关键字k
- 如果删除的是一个存在于非叶子节点x的关键字k,此关键字k拥有左右孩子指针,且结点x的关键字数大于3个【PS : 根据删除关键字k的左右孩子结点来合并、升降关键字】
引用算法导论提供的的删除流程 如下图 :
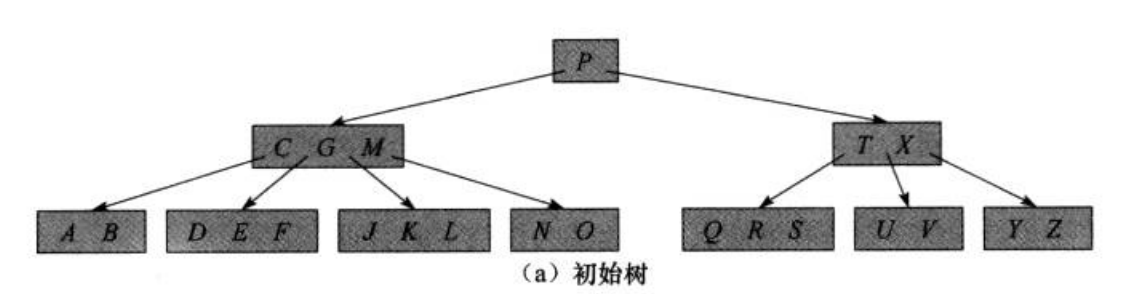
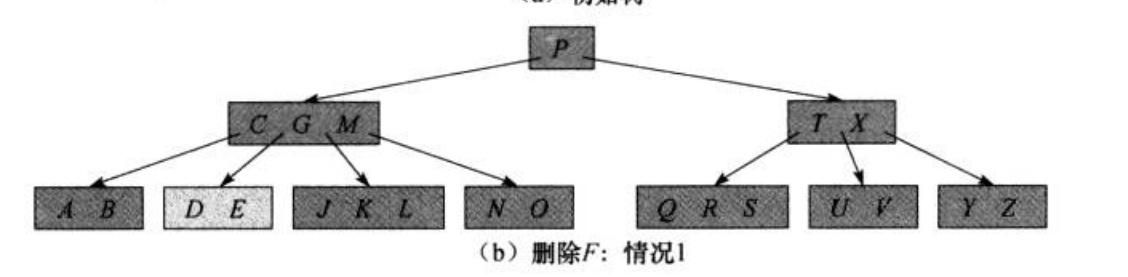

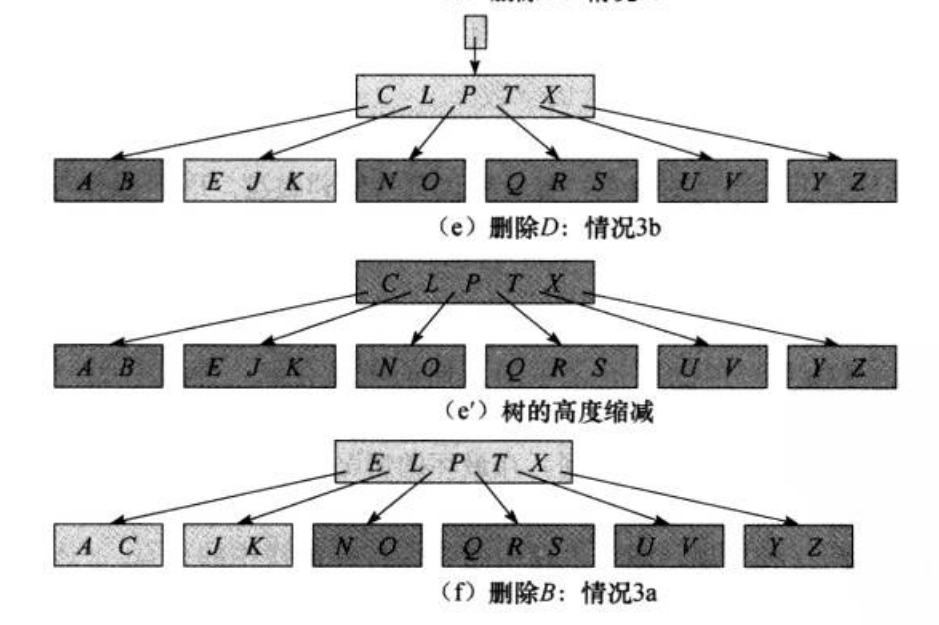
B-Tree ---- 小结
B-Tree 和 B+Tree 的结点存储的数据不一样,B+Tree的结点存储的是关键字和孩子指针,而B-Tree的结点比B+Tree的结点多存储了value,导致了B-Tree结点存储的关键字信息更少了;接下来看看它们的比较如下 :
- B-Tree每次查询的时候并不是都需要读取到叶子节点,而B+Tree每次的查询都必须查询到叶子节点才能读到符合条件的数据
- B+Tree的每个结点可以存储更多的关键字
- B-Tree 和 B+Tree 的插入操作都会插入到叶子节点
- 根结点的分裂的树的高度增加的唯一途径
- 减少分裂、合并可以给B-Tree、B+Tree提高性能
- B-Tree、B+Tree能找到的只是被查询的结点,最终是要把结点载入内存中,对该结点的关键字进行遍历(单向链表、二分查询算法)
- B-Tree、B+Tree的结点与结点是通过双向链表链接起来的
- B-Tree 不支持范围查询、B+Tree支持范围查询
InnoDB存储引擎使用的索引
InnoDB存储引擎底层的存储结构使用的是B+Tree数据结构,B+Tree能找到的只是被查询的数据页,InnoDB存储引擎把数据页载入Buffer Pool,在Buffer Pool中对该数据页的关键字进行查找遍历,而B+Tree每次查询都需要查询到叶子节点才能找到数据,所以每次的查询需要H次磁盘IO(H为B+Tree高度).
InnoDB存储引擎索引的分类
InnoDB存储引擎对B+Tree的存储是如何分类的 : 聚集索引、辅助索引
- 聚集索引 : 按照每张表的主键构造的一棵B+Tree,叶子节点存放的是整行的数据,且每张表只能拥有一个聚集索引;在多数情况下,优化器会优先采用聚集索引,因为聚集索引可以在叶子结点上直接找到整行的数据(无需回表),并且B+Tree也支持范围查询.
- 辅助索引 : 叶子结点并不包含行记录的全部数据,而是除了关键字之外还包含主键ID,可通过主键ID回表查询完整的行数据(查询聚集索引);
Online DDL
创建索引会阻塞表上的DML操作,Online DDL的作用就是允许辅助索引创建的同时,还允许其他例如INSERT\UPDATE\DELETE这类的DML操作,这极大的提升了MySQL数据库的可用性.
B+Tree 的使用
- 联合索引 : 指对表上多个列进行索引,联合索引也是一棵B+Tree,不同的是联合索引的关键字值的数量不是1(单列索引),而是大于等于2.
- 覆盖索引 : 表示从辅助索引中就可以查询到的记录(无需回表查询),可减少大量的磁盘IO.
结束语
- 原创不易
- 希望看完这篇文章的你有所收获!
相关参考资料
- 算法导论(第3版)【书籍】
- MySQL技术内幕(第2版)【书籍】